用EM算法求解高斯混合模型
本文从高斯混合模型出发,引出EM算法,最后回归到利用EM算法求解高斯混合模型。理论部分力求详尽不留证明疑点,所以略显冗长。实验部分给出了生成高斯混合分布样本和利用EM算法求解高斯混合模型的matlab代码。
理论部分
高斯混合模型(GMM)
顾名思义,高斯混合模型就是由多个高斯分布混合构成的模型。 K K K高斯混合分布的概率密度为:
p ( x ) = ∑ k = 1 K ϕ k N ( x ∣ μ k , Σ k ) . p(\mathbf{x})=\sum_{k=1}^K \phi_k\mathcal{N}(\mathbf{x}|\boldsymbol{\mu}_k,\boldsymbol{\Sigma}_k). p(x)=k=1∑KϕkN(x∣μk,Σk).
这里, ∑ k = 1 K ϕ k = 1 \sum_{k=1}^{K}\phi_k=1 ∑k=1Kϕk=1为混合系数,
N ( x ∣ μ , Σ ) = 1 ( 2 π ) D / 2 1 ∣ Σ ∣ 1 / 2 exp { − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) } \mathcal{N}(\mathbf{x}|\boldsymbol{\mu},\boldsymbol{\Sigma})=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\boldsymbol{\Sigma}|^{1/2}}\exp\left\{-\frac{1}{2}(\mathbf{x}-\boldsymbol{\mu})^T\boldsymbol{\Sigma}^{-1}(\mathbf{x}-\boldsymbol{\mu})\right\} N(x∣μ,Σ)=(2π)D/21∣Σ∣1/21exp{−21(x−μ)TΣ−1(x−μ)}
为 D D D维高斯分布,其中 μ \boldsymbol{\mu} μ为其均值向量, Σ \boldsymbol{\Sigma} Σ为其协方差矩阵。
直观来看,高斯混合分布可以看做下面分步过程的整合:
第一步,以 ϕ k \phi_k ϕk概率选择第 k k k个高斯模型;
第二步,利用第 k k k个高斯模型生成一个样本 x \mathbf{x} x。
为了讨论方便,记 θ = { ϕ 1 , … , ϕ K , μ 1 , … , μ K , Σ 1 , … , Σ K } \theta=\{\phi_1,\dots,\phi_K,\boldsymbol{\mu}_1,\dots,\boldsymbol{\mu}_K,\boldsymbol{\Sigma}_1,\dots,\boldsymbol{\Sigma}_K\} θ={ϕ1,…,ϕK,μ1,…,μK,Σ1,…,ΣK}为高斯混合分布的参数集合。现在要解决的问题是,对于给定服从高斯混合分布的独立同分布样本集 X = { x 1 , … , x n } \mathbf{X}=\{\mathbf{x}_1, \dots, \mathbf{x}_n\} X={x1,…,xn},最大化其对数似然函数:
max θ ln p ( X ∣ θ ) = ∑ i = 1 n ln ∑ k = 1 K ϕ k N ( x i ∣ μ k , Σ k ) . \max_{\theta}\ln p(\mathbf{X}|\theta)=\sum_{i=1}^n\ln\sum_{k=1}^K\phi_k\mathcal{N}(\mathbf{x}_i|\boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k). θmaxlnp(X∣θ)=i=1∑nlnk=1∑KϕkN(xi∣μk,Σk).
这里, p ( X ∣ θ ) = ∏ i = 1 n p ( x i ∣ θ ) p(\mathbf{X}|\theta)=\prod\limits_{i=1}^np(\mathbf{x}_i|\theta) p(X∣θ)=i=1∏np(xi∣θ)。由于 ln \ln ln函数里的求和项,我们无法直接求得闭式解,而利用EM算法可以得到一个局部最优数值解。
EM算法
从分步角度来看,求解高斯混合模型的难点在于,我们不知道一个样本 x i \mathbf{x}_i xi具体是由 K K K个高斯模型中的哪一个生成的。所以,对于第 i i i个样本 x i \mathbf{x}_i xi来说,我们构造一个隐变量 z i z_i zi用来表示 x i \mathbf{x}_i xi来自于哪个高斯模型。也即, z i = k z_i=k zi=k当且仅当 x i \mathbf{x}_i xi来自于第 k k k个高斯模型。注意,虽然这个隐变量的取值是客观确定的,但对我们来说是不可见,因此仍将其看作随机变量。记 Z = { z 1 , … , z n } \mathbf{Z}=\{z_1,\dots,z_n\} Z={z1,…,zn},对于固定的模型参数 θ ˉ \bar{\theta} θˉ,下面的不等式给出了EM算法的框架。
ln p ( X ∣ θ ˉ ) = ∑ Z p ( Z ∣ X , θ ˉ ) ln p ( X ∣ θ ˉ ) = ∑ Z p ( Z ∣ X , θ ˉ ) ln p ( X , Z ∣ θ ˉ ) p ( Z ∣ X , θ ˉ ) ≤ max θ ∑ Z p ( Z ∣ X , θ ˉ ) ln p ( X , Z ∣ θ ) p ( Z ∣ X , θ ˉ ) ( 1 ) ≤ ln ∑ Z p ( X , Z ∣ θ m a x ) p ( Z ∣ X , θ ˉ ) p ( Z ∣ X , θ ˉ ) ( J e n s e n 不 等 式 ) = ln p ( X ∣ θ m a x ) \begin{aligned} \ln p(\mathbf{X}|\bar{\theta})&=\sum_{\mathbf{Z}}p(\mathbf{Z}|\mathbf{X},\bar{\theta})\ln p(\mathbf{X}|\bar{\theta})\\ &=\sum_{\mathbf{Z}}p(\mathbf{Z}|\mathbf{X},\bar{\theta})\ln\frac{p(\mathbf{X},\mathbf{Z}|\bar{\theta})}{p(\mathbf{Z}|\mathbf{X},\bar{\theta})} \\ &\leq\max_\theta \sum_{\mathbf{Z}}p(\mathbf{Z}|\mathbf{X},\bar{\theta})\ln\frac{p(\mathbf{X},\mathbf{Z}|\theta)}{p(\mathbf{Z}|\mathbf{X},\bar{\theta})} & (1)\\ &\leq \ln \sum_{\mathbf{Z}}\frac{p(\mathbf{X},\mathbf{Z}|\theta_{max})}{p(\mathbf{Z}|\mathbf{X},\bar{\theta})}p(\mathbf{Z}|\mathbf{X},\bar{\theta}) & (Jensen不等式)\\ &=\ln p(\mathbf{X}|\theta_{max}) \end{aligned} lnp(X∣θˉ)=Z∑p(Z∣X,θˉ)lnp(X∣θˉ)=Z∑p(Z∣X,θˉ)lnp(Z∣X,θˉ)p(X,Z∣θˉ)≤θmaxZ∑p(Z∣X,θˉ)lnp(Z∣X,θˉ)p(X,Z∣θ)≤lnZ∑p(Z∣X,θˉ)p(X,Z∣θmax)p(Z∣X,θˉ)=lnp(X∣θmax)(1)(Jensen不等式)
如果将 θ ˉ \bar{\theta} θˉ和 θ m a x \theta_{max} θmax分别看成EM算法一次迭代前后的模型参数,上面的推导实际上证明了其会收敛到局部最优解。对于上面的式(1),我们有
θ m a x = arg max θ ∑ Z p ( Z ∣ X , θ ˉ ) ln p ( X , Z ∣ θ ) p ( Z ∣ X , θ ˉ ) = arg max θ ∑ Z p ( Z ∣ X , θ ˉ ) ln p ( X , Z ∣ θ ) . ( 2 ) \begin{aligned} \theta_{max}&=\mathop{\arg \max}_\theta \sum_{\mathbf{Z}}p(\mathbf{Z}|\mathbf{X},\bar{\theta})\ln\frac{p(\mathbf{X},\mathbf{Z}|\theta)}{p(\mathbf{Z}|\mathbf{X},\bar{\theta})}\\&=\mathop{\arg \max}_\theta\sum_{\mathbf{Z}}p(\mathbf{Z}|\mathbf{X},\bar{\theta})\ln p(\mathbf{X},\mathbf{Z}|\theta). & (2) \end{aligned} θmax=argmaxθZ∑p(Z∣X,θˉ)lnp(Z∣X,θˉ)p(X,Z∣θ)=argmaxθZ∑p(Z∣X,θˉ)lnp(X,Z∣θ).(2)
这里式(2)中的优化问题就对应了EM算法中的M步。另一方面,E步指的就是利用旧的模型参数 θ ˉ \bar{\theta} θˉ将目标函数 ∑ Z p ( Z ∣ X , θ ˉ ) ln p ( X , Z ∣ θ ) \sum_{\mathbf{Z}}p(\mathbf{Z}|\mathbf{X},\bar{\theta})\ln p(\mathbf{X},\mathbf{Z}|\theta) ∑Zp(Z∣X,θˉ)lnp(X,Z∣θ)显示的表达出来。
对于EM算法中的M步的目标函数,在《PRML》和Ng的讲义中分别用两种形式来表达,下面的命题表明两种形式是等价的。注意到 p ( Z ∣ X , θ ˉ ) = ∏ j = 1 n p ( z j ∣ x j , θ ˉ ) p(\mathbf{Z}|\mathbf{X},\bar{\theta})=\prod\limits_{j=1}^np(z_j|\mathbf{x}_j,\bar{\theta}) p(Z∣X,θˉ)=j=1∏np(zj∣xj,θˉ)以及 p ( X , Z ∣ θ ) = ∏ i = 1 n p ( x i , z i ∣ θ ) p(\mathbf{X},\mathbf{Z}|\theta)=\prod\limits_{i=1}^np(\mathbf{x}_i,z_i|\theta) p(X,Z∣θ)=i=1∏np(xi,zi∣θ),则有
###Proposition 1.
∑ Z p ( Z ∣ X , θ ˉ ) ln p ( X , Z ∣ θ ) = ∑ i = 1 n ∑ z i p ( z i ∣ x i , θ ˉ ) ln p ( x i , z i ∣ θ ) . ( 3 ) \sum_{\mathbf{Z}}p(\mathbf{Z}|\mathbf{X},\bar{\theta})\ln p(\mathbf{X},\mathbf{Z}|\theta)=\sum_{i=1}^n\sum_{z_i}p(z_i|\mathbf{x}_i,\bar{\theta})\ln p(\mathbf{x}_i,z_i|\theta). \quad (3) Z∑p(Z∣X,θˉ)lnp(X,Z∣θ)=i=1∑nzi∑p(zi∣xi,θˉ)lnp(xi,zi∣θ).(3)
Pf.
∑ Z p ( Z ∣ X , θ ˉ ) ln p ( X , Z ∣ θ ) = ∑ Z ∏ j = 1 n p ( z j ∣ x j , θ ˉ ) ln ∏ i = 1 n p ( x i , z i ∣ θ ) = ∑ z 1 ∑ z 2 ⋯ ∑ z n ∏ j = 1 n p ( z j ∣ x j , θ ˉ ) ∑ i = 1 n ln p ( x i , z i ∣ θ ) = ∑ i = 1 n ∑ z i p ( z i ∣ x i , θ ˉ ) ln p ( x i , z i ∣ θ ) ∑ z 1 ∑ z 2 ⋯ ∑ z t , t ̸ = i ⋯ ∑ z n ∏ j = 1 , j ̸ = i n p ( z j ∣ x j , θ ˉ ) = ∑ i = 1 n ∑ z i p ( z i ∣ x i , θ ˉ ) ln p ( x i , z i ∣ θ ) ∏ j = 1 , j ̸ = i n ∑ z j p ( z j ∣ x j , θ ˉ ) ( 多 项 式 乘 积 展 开 式 的 逆 ) = ∑ i = 1 n ∑ z i p ( z i ∣ x i , θ ˉ ) ln p ( x i , z i ∣ θ ) . ( 概 率 归 一 性 ) □ \begin{aligned} \sum_{\mathbf{Z}}p(\mathbf{Z}|\mathbf{X},\bar{\theta})\ln p(\mathbf{X},\mathbf{Z}|\theta)&=\sum_{\mathbf{Z}}\prod\limits_{j=1}^np(z_j|\mathbf{x}_j,\bar{\theta})\ln \prod\limits_{i=1}^np(\mathbf{x}_i,z_i|\theta)\\ &=\sum_{z_1}\sum_{z_2}\cdots\sum_{z_n}\prod\limits_{j=1}^np(z_j|\mathbf{x}_j,\bar{\theta})\sum_{i=1}^n\ln p(\mathbf{x}_i,z_i|\theta)\\ &=\sum_{i=1}^n\sum_{z_i}p(z_i|\mathbf{x}_i,\bar{\theta})\ln p(\mathbf{x}_i,z_i|\theta)\sum_{z_1}\sum_{z_2}\cdots\sum_{z_t,t\not=i}\cdots\sum_{z_n}\prod\limits_{j=1,j\not=i}^np(z_j|\mathbf{x}_j,\bar{\theta})\\ &=\sum_{i=1}^n\sum_{z_i}p(z_i|\mathbf{x}_i,\bar{\theta})\ln p(\mathbf{x}_i,z_i|\theta)\prod_{j=1,j\not=i}^n\sum_{z_j}p(z_j|\mathbf{x}_j,\bar{\theta}) & (多项式乘积展开式的逆)\\ &=\sum_{i=1}^n\sum_{z_i}p(z_i|\mathbf{x}_i,\bar{\theta})\ln p(\mathbf{x}_i,z_i|\theta). & (概率归一性)\quad\square \end{aligned} Z∑p(Z∣X,θˉ)lnp(X,Z∣θ)=Z∑j=1∏np(zj∣xj,θˉ)lni=1∏np(xi,zi∣θ)=z1∑z2∑⋯zn∑j=1∏np(zj∣xj,θˉ)i=1∑nlnp(xi,zi∣θ)=i=1∑nzi∑p(zi∣xi,θˉ)lnp(xi,zi∣θ)z1∑z2∑⋯zt,t̸=i∑⋯zn∑j=1,j̸=i∏np(zj∣xj,θˉ)=i=1∑nzi∑p(zi∣xi,θˉ)lnp(xi,zi∣θ)j=1,j̸=i∏nzj∑p(zj∣xj,θˉ)=i=1∑nzi∑p(zi∣xi,θˉ)lnp(xi,zi∣θ).(多项式乘积展开式的逆)(概率归一性)□
窃以为式(3)中左式(PRML中的写法)简洁抽象,适合做理论推导;右式(Ng讲义中的写法)表达具体,适合指导算法实践。
EM算法求解高斯混合模型
具体应用到GMM模型中,EM算法中的M步我们要求解
max θ ∑ i = 1 n ∑ z i p ( z i ∣ x i , θ ˉ ) ln p ( x i , z i ∣ θ ) = ∑ i = 1 n ∑ z i = 1 K p ( z i ∣ x i , θ ˉ ) ln ϕ z i N ( x i ∣ μ z i , Σ z i ) = ∑ i = 1 n ∑ k = 1 K p ( k ∣ x i , θ ˉ ) ln ϕ k N ( x i ∣ μ k , Σ k ) \begin{aligned} \max_{\theta}\sum_{i=1}^n\sum_{z_i}p(z_i|\mathbf{x}_i,\bar{\theta})\ln p(\mathbf{x}_i,z_i|\theta)&=\sum_{i=1}^n\sum_{z_i=1}^Kp(z_i|\mathbf{x}_i,\bar{\theta})\ln \phi_{z_i}\mathcal{N}(\mathbf{x}_i|\boldsymbol{\mu}_{z_i},\boldsymbol{\Sigma}_{z_i})\\ &=\sum_{i=1}^n\sum_{k=1}^Kp(k|\mathbf{x}_i,\bar{\theta})\ln \phi_{k}\mathcal{N}(\mathbf{x}_i|\boldsymbol{\mu}_{k},\boldsymbol{\Sigma}_{k}) \end{aligned} θmaxi=1∑nzi∑p(zi∣xi,θˉ)lnp(xi,zi∣θ)=i=1∑nzi=1∑Kp(zi∣xi,θˉ)lnϕziN(xi∣μzi,Σzi)=i=1∑nk=1∑Kp(k∣xi,θˉ)lnϕkN(xi∣μk,Σk)
注意到 p ( k ∣ x i , θ ˉ ) p(k|\mathbf{x}_i,\bar{\theta}) p(k∣xi,θˉ)不包含优化变量 θ \theta θ,因此在此问题中可以看做关于 i i i和 k k k的常数,故我们暂记其为 γ i k \gamma_{ik} γik,留到最后再讨论其具体取值。 忽略掉优化无关常数,M步的优化问题正式写作:
max ϕ k , μ k , Σ k f ( ϕ k , μ k , Σ k ) = ∑ i = 1 n ∑ k = 1 K γ i k ( ln ϕ k − 1 2 ln ∣ Σ k ∣ − 1 2 ( x i − μ k ) T Σ k − 1 ( x i − μ k ) ) ( 4 ) \begin{aligned} \max_{\phi_k,\boldsymbol{\mu}_k,\boldsymbol{\Sigma}_k}f(\phi_k,\boldsymbol{\mu}_k,\boldsymbol{\Sigma}_k)=\sum_{i=1}^n\sum_{k=1}^K\gamma_{ik}(\ln\phi_k-\frac{1}{2}\ln|\boldsymbol{\Sigma}_k|-\frac{1}{2}(\mathbf{x}_i-\boldsymbol{\mu}_k)^T\boldsymbol{\Sigma}_k^{-1}(\mathbf{x}_i-\boldsymbol{\mu}_k)) & (4) \end{aligned} ϕk,μk,Σkmaxf(ϕk,μk,Σk)=i=1∑nk=1∑Kγik(lnϕk−21ln∣Σk∣−21(xi−μk)TΣk−1(xi−μk))(4)
s.t. ϕ k > 0 ( k = 1 , … , K ) ∑ k = 1 K ϕ k = 1 Σ k ≻ 0 ( k = 1 , … , K ) \begin{aligned} \text{s.t. } & \phi_k>0 & (k=1,\dots,K)\\ &\sum_{k=1}^K\phi_k=1\\ &\boldsymbol{\Sigma}_k\succ0 & (k=1,\dots,K) \end{aligned} s.t. ϕk>0k=1∑Kϕk=1Σk≻0(k=1,…,K)(k=1,…,K)
这里, Σ k ≻ 0 \boldsymbol{\Sigma}_k\succ0 Σk≻0表示 Σ k \boldsymbol{\Sigma}_k Σk正定。观察到对 μ k \boldsymbol{\mu}_k μk没有任何约束,所以我们先让目标函数对 μ k \boldsymbol{\mu}_k μk求偏导并令其为0
∂ ∂ μ k = − ∑ i = 1 n γ i k Σ k − 1 ( x i − μ k ) = 0 , \frac{\partial}{\partial\boldsymbol{\mu}_k}=-\sum_{i=1}^n\gamma_{ik}\boldsymbol{\Sigma}_k^{-1}(\mathbf{x}_i-\boldsymbol{\mu}_k)=0, ∂μk∂=−i=1∑nγikΣk−1(xi−μk)=0,
令 n k = ∑ i = 1 n γ i k n_k=\sum\limits_{i=1}^n\gamma_{ik} nk=i=1∑nγik,利用 Σ k \boldsymbol{\Sigma}_k Σk满秩约束解得
μ k ∗ = 1 n k ∑ i = 1 n γ i k x i . \boldsymbol{\mu}_k^*=\frac{1}{n_k}\sum_{i=1}^n\gamma_{ik}\mathbf{x}_i. μk∗=nk1i=1∑nγikxi.
接下来,我们在没有 Σ k ≻ 0 \boldsymbol{\Sigma}_k\succ0 Σk≻0限制下求使目标函数极大的 Σ k ∗ \boldsymbol{\Sigma}_k^* Σk∗,最后再验证 Σ k ∗ \boldsymbol{\Sigma}_k^* Σk∗的确是一个正定矩阵。因为直接对 Σ k \boldsymbol{\Sigma}_k Σk求偏导比较困难,因此我们转而对 Σ k − 1 \boldsymbol{\Sigma}_k^{-1} Σk−1求偏导并令其为0
∂ ∂ Σ k − 1 = ∑ i = 1 n γ i k ( adj ( Σ k − 1 ) T ∣ Σ k − 1 ∣ − ( x i − μ k ) ( x i − μ k ) T ) = 0 , \frac{\partial}{\partial\boldsymbol{\Sigma}_k^{-1}}=\sum_{i=1}^n\gamma_{ik}(\frac{\text{adj}(\boldsymbol{\Sigma}_k^{-1})^T}{|\boldsymbol{\Sigma}_k^{-1}|}-(\mathbf{x}_i-\boldsymbol{\mu}_k)(\mathbf{x}_i-\boldsymbol{\mu}_k)^T)=0, ∂Σk−1∂=i=1∑nγik(∣Σk−1∣adj(Σk−1)T−(xi−μk)(xi−μk)T)=0,
解得
Σ k ∗ = 1 n k ∑ i = 1 n γ i k ( x i − μ k ) ( x i − μ k ) T . \boldsymbol{\Sigma}_k^*=\frac{1}{n_k}\sum_{i=1}^n\gamma_{ik}(\mathbf{x}_i-\boldsymbol{\mu}_k)(\mathbf{x}_i-\boldsymbol{\mu}_k)^T. Σk∗=nk1i=1∑nγik(xi−μk)(xi−μk)T.
这里 adj ( M ) = ∣ M ∣ M − 1 \text{adj}(\mathbf{M})=|\mathbf{M}|\mathbf{M}^{-1} adj(M)=∣M∣M−1表示矩阵 M \mathbf{M} M的伴随矩阵。容易验证 Σ k ∗ \boldsymbol{\Sigma}_k^* Σk∗为一个半正定矩阵。 Σ k ∗ \boldsymbol{\Sigma}_k^* Σk∗不可逆的情况只会在样本集的防射维数小于数据空间维数情况下发生,对于此情况有两种解决办法。一是将原始数据利用PCA降维;二是对数据加上微小随机扰动。两种方式本质上都是保证数据集的防射维数等于数据空间维数。
然后,我们对 ϕ k \phi_k ϕk在条件 ∑ k = 1 K ϕ k = 1 \sum_{k=1}^K\phi_k=1 ∑k=1Kϕk=1下利用拉格朗日乘子法求解,然后再来验证 ϕ k > 0 \phi_k>0 ϕk>0。构造拉格朗日函数
L ( ϕ k , λ ) = f ( ϕ k , μ k , Σ k ) + λ ( ∑ k = 1 K ϕ k − 1 ) , L(\phi_k,\lambda)=f(\phi_k,\boldsymbol{\mu}_k,\boldsymbol{\Sigma}_k)+\lambda\left(\sum_{k=1}^K\phi_k-1\right), L(ϕk,λ)=f(ϕk,μk,Σk)+λ(k=1∑Kϕk−1),
利用KKT条件:
{ ∂ ∂ ϕ k L ( ϕ k , λ ) = 1 ϕ k ∑ i = 1 n γ i k + λ = 0 k = 1 , … , K ∑ k = 1 K ϕ k = 1. \left\{ \begin{array}{cc} \frac{\partial}{\partial\phi_k}L(\phi_k,\lambda)=\frac{1}{\phi_k}\sum_{i=1}^n\gamma_{ik}+\lambda=0 & k=1,\dots,K\\ \sum_{k=1}^K\phi_k=1. \end{array}\right. {∂ϕk∂L(ϕk,λ)=ϕk1∑i=1nγik+λ=0∑k=1Kϕk=1.k=1,…,K
解得
ϕ k ∗ = n k n , \phi_k^*=\frac{n_k}{n}, ϕk∗=nnk,
可以看到 ϕ k \phi_k ϕk确实是大于0的。这样就验证了 μ k ∗ , Σ k ∗ , ϕ k ∗ \boldsymbol{\mu}_k^*,\boldsymbol{\Sigma}_k^*,\phi_k^* μk∗,Σk∗,ϕk∗确实是满足条件的一个局部最优解。最后再来看 γ i k = p ( k ∣ x i , θ ˉ ) \gamma_{ik}=p(k|\mathbf{x}_i,\bar{\theta}) γik=p(k∣xi,θˉ)的具体表达式,利用贝叶斯公式可得
p ( k ∣ x i , θ ˉ ) = ϕ ˉ k N ( x i ∣ μ ˉ k , Σ ˉ k ) ∑ k = 1 K ϕ ˉ k N ( x i ∣ μ ˉ k , Σ ˉ k ) . p(k|\mathbf{x}_i,\bar{\theta})=\frac{\bar{\phi}_{k}\mathcal{N}(\mathbf{x}_i|\bar{\boldsymbol{\mu}}_{k},\bar{\boldsymbol{\Sigma}}_{k})}{\sum\limits_{k=1}^K\bar{\phi}_k\mathcal{N}(\mathbf{x}_i|\bar{\boldsymbol{\mu}}_k,\bar{\boldsymbol{\Sigma}}_k)}. p(k∣xi,θˉ)=k=1∑KϕˉkN(xi∣μˉk,Σˉk)ϕˉkN(xi∣μˉk,Σˉk).
综上所述,可得整个算法如下:

实验部分
生成数据
此步用matlab生成服从高斯混合分布的数据。
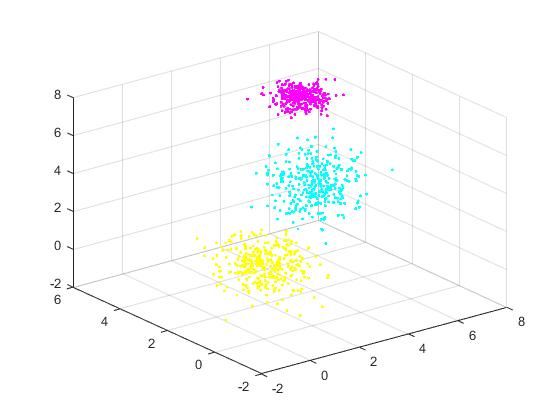
%参数区,可自行调整
K = 3; %高斯模型个数
dim = 3; %数据维度
N = 1000; %生成的样本个数
step = 4; %不同高斯模型均值之间的距离
%变量区
Phi = cell(K,1); %混合系数构成的cellArray
Mu=cell(K,1); %均值向量构成的cellArray
Sigma = cell(K,1); %协方差矩阵构成的cellArray
Dat = zeros(N,dim+1); %数据矩阵,其中最后一个维度为标签
for i =1:K
Phi(i)={1/K}; %默认每个模型的选择系数相同,可自行调整
end
Mu(1) = {ones(dim,1)};
for i =2:K
t = rand(dim,1);
t = t/norm(t,2)*step;
Mu(i)={Mu{i-1}+t};
end
for i =1:K
t = rand(dim);
t = orth(t);
tt = rand(dim,1);
Sigma(i) = {t'*diag(tt)*t};
end
%这里直接按系数比例生成样本,与直接按照高斯混合分布生成的样本大致是类似的
cnt = 0;
for i = 1:K
if i == K
n = N-cnt;
else
n = round(N*Phi{i});
end
t = mvnrnd(Mu{i}, Sigma{i}, n);
Dat(cnt+1:cnt+n,:) = [t ones(n, 1)*i];
cnt = cnt+n;
end
%存储数据部分
save('Dat.mat', 'Dat');
%画图部分
close all;
view(3);
hold on;
grid on;
mycolor = colorcube(20);
cnt = 0;
for i = 1:K
if i == K
n = N-cnt;
else
n = round(N*Phi{i});
end
t = Dat(cnt+1:cnt+n,:);
plot3(t(:,1), t(:,2), t(:,3), '.', 'Color', mycolor(i,:));
cnt = cnt+n;
end
hold off;
EM算法求解GMM
利用EM算法求解GMM的过程中涉及到参数初始化问题,比较高效的做法是利用Kmeans先做聚类,再把每一类样本的比例,均值和协方差矩阵作为初始参数,再利用EM算法进行微调。如果想观察EM算法求解GMM的收敛行为,可以使用随机初始化参数。在下面的代码中,我们利用迭代前后对数似然函数的相对偏差作为判断其是否收敛。
function []=main()
close all;
Eps = 1e-4; %当迭代前后两次对数似然函数值的相对偏差小于Eps时算法结束
flag = false; %是否使用kmeans初始化参数
load('Dat.mat'); %导入数据,Dat为N*(dim+1)维的矩阵,每行最后一个元素为其隐变量取值(实验中没有用到)
N = size(Dat, 1); %样本个数
dim = size(Dat, 2)-1; %数据维度
K = max(Dat(:,dim+1)); %高斯模型个数
%初始化参数部分
if flag
%用kmeans初始化参数
[PhiBar, MuBar, SigmaBar] = initByKmeans(Dat(:,1:dim), K);
else
%随机初始化参数
PhiBar = cell(K,1);
MuBar=cell(K,1);
SigmaBar = cell(K,1);
rPhi = rand(3,1);
rPhi = rPhi/(ones(1, 3)*rPhi);
for k=1:K
PhiBar(k) = {rPhi(k)};
MuBar(k) = {mean(Dat(:,1:dim))'.*(1+rand(dim, 1)*1)};
SigmaBar(k) = {eye(dim)};
end
end
logLikeBar = calLogLike(Dat(:,1:dim), K, PhiBar, MuBar, SigmaBar); %计算初始对数似然函数值
Phi= cell(K,1);
Mu=cell(K,1);
Sigma = cell(K,1);
%EM算法
cnt = 0;
while true
%E step:
Gamma = zeros(N, K);
for i = 1:N
Xi = Dat(i,1:dim)';
Pxi = 0;
for k = 1:K
Pxi = Pxi+PhiBar{k}*mvnpdf(Xi, MuBar{k}, SigmaBar{k});
end
for k = 1:K
Gamma(i,k) = PhiBar{k}*mvnpdf(Xi, MuBar{k}, SigmaBar{k})/Pxi;
end
end
%M step:
N_k = ones(1,N)*Gamma;
for k=1:K
Phi(k) = {N_k(k)/N};
mu = zeros(dim, 1);
for i = 1:N
mu = mu+Gamma(i,k)*Dat(i,1:dim)';
end
Mu(k) = {mu/N_k(k)};
sigma = zeros(dim);
for i = 1:N
sigma = sigma+Gamma(i,k)*(Dat(i,1:dim)'-Mu{k})*(Dat(i,1:dim)-Mu{k}');
end
Sigma(k) = {sigma/N_k(k)};
end
cnt = cnt+1;
logLike = calLogLike(Dat(:,1:dim), K, Phi, Mu, Sigma);
relGap = abs(logLike-logLikeBar)/abs(logLikeBar);
disp(['Iteration: ', num2str(cnt), ' RelativeGap: ', sprintf('%.6f LogLikelihood %.6f', relGap, logLike)]);
logLikeBar = logLike;
%绘图部分
% figure(cnt);
% view(3);
% hold on;
% grid on;
% mycolor = colorcube(20);
% for i = 1:N
% postP = 0;
% choose = 0;
% for k = 1:K %利用后验概率最大化准则
% temp = Phi{k}*mvnpdf(Dat(i,1:dim)', Mu{k}, Sigma{k});
% if temp > postP
% postP = temp;
% choose = k;
% end
% end
% plot3(Dat(i,1), Dat(i,2), Dat(i,3),'.', 'Color', mycolor(choose,:), 'markersize', 4);
% end
% for k =1:K
% plot3(Mu{k}(1), Mu{k}(2), Mu{k}(3), 'k.', 'markersize', 15);
% end
% saveas(gcf,sprintf('%d.jpg', cnt));
if relGap < Eps
break;
end
PhiBar = Phi;
MuBar = Mu;
SigmaBar = Sigma;
end
end
function [Phi, Mu, Sigma] = initByKmeans(X, K) %Kmeans随机初始化参数
N = size(X,1);
dim = size(X,2);
Phi= cell(K,1);
Mu=cell(K,1);
Sigma = cell(K,1);
for k=1:K
Phi(k) = {0};
Mu(k) = {zeros(dim, 1)};
Sigma(k) = {zeros(dim)};
end
[idx, C] = kmeans(X, K);
for k = 1:K
Mu{k} = C(k,:)';
end
for i = 1:N
k = idx(i);
Phi{k} = Phi{k}+1;
Sigma{k} = Sigma{k}+(X(i,:)'-Mu{k})*(X(i,:)-Mu{k}');
end
for k=1:K
Sigma{k}= Sigma{k}/Phi{k}+1e-6*ones(dim);
Phi{k} = Phi{k}/N;
end
end
function [logLike] = calLogLike(X, K, Phi, Mu, Sigma) %计算对数似然函数值
logLike = 0;
N = size(X,1);
for i =1:N
p = 0;
for k = 1:K
p = p+Phi{k}*mvnpdf(X(i,:)', Mu{k}, Sigma{k});
end
logLike = logLike+log(p);
end
end
参考文献
Christopher M… Bishop. Pattern recognition and machine learning. pp. 430-459
Andrew Ng. Machine Learning Lecture Notes.