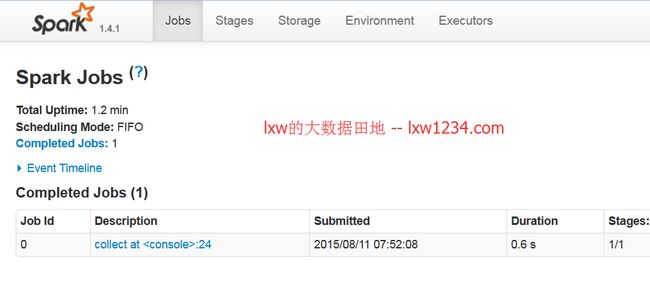
leetcode核心思想:双指针,数字小的那个指针移动classSolution{public:intmaxArea(vector&height){intleft=0;intright=height.size()-1;intmaxArea=0;while(left
Kubernetes数据持久化
看清所苡看轻
kubernetes(k8s)emptyDirHostPathpvpvckubernetes
在k8s中,Volume(数据卷)存在明确的生命周期(与包含该数据卷的容器组(pod)相同)。因此Volume的生命周期比同一容器组(pod)中任意容器的生命周期要更长,不管容器重启了多少次,数据都被保留下来。当然,如果pod不存在了,数据卷自然退出了。此时,根据pod所使用的数据卷类型不同,数据可能随着数据卷的退出而删除,也可能被真正持久化,并在下次容器组重启时仍然可以使用。从根本上来说,一个数
Vue3 vant组件库自动导入
不叫虎子
Vuevue.js前端javascript前端框架typescript
实现:完整使用vant组件库文档安装:#Vue3项目,安装最新版Vantnpmivant#通过yarn安装yarnaddvant#通过pnpm安装pnpmaddvant【一】按需引入:https://vant-contrib.gitee.io/vant/#/zh-CN/quickstart#fang-fa-er.-an-xu-yin-ru-zu-jian-yang-shi【二】批量引入在基于vit
leetcode刷题day13|二叉树Part01(递归遍历、迭代遍历、统一迭代、层序遍历)
小冉在学习
leetcode算法职场和发展
递归遍历思路:使用递归的方式比较简单。1、递归函数的传参:因为最后输出一个数组,所以需要传入根节点和一个容器,本来想写数组,但发现长度不能确定,所以选择list。2、终止条件:当访问的节点为空时,return3、递归函数的逻辑:先访问一个节点,递归访问其他节点144.二叉树的前序遍历代码如下:classSolution{publicListpreorderTraversal(TreeNoderoo
Hadoop
傲雪凌霜,松柏长青
后端大数据hadoop大数据分布式
ApacheHadoop是一个开源的分布式计算框架,主要用于处理海量数据集。它具有高度的可扩展性、容错性和高效的分布式存储与计算能力。Hadoop核心由四个主要模块组成,分别是HDFS(分布式文件系统)、MapReduce(分布式计算框架)、YARN(资源管理)和HadoopCommon(公共工具和库)。1.HDFS(HadoopDistributedFileSystem)HDFS是Hadoop生
Kubernetes的3种数据持久化方式
Seal^_^
【云原生】容器化与编排技术持续集成#Kuberneteskubernetes容器云原生EmptyDir面试HostPath
Kubernetes的3种数据持久化方式1.EmptyDir2.HostPath3.PersistentVolume(PV)TheBegin点点关注,收藏不迷路Kubernetes提供了几种数据持久化方式,以满足不同场景的需求:1.EmptyDir用途:临时数据存储,Pod内容器间共享。特点:生命周期与Pod相同,Pod删除时数据也删除。2.HostPath用途:访问宿主机特定文件或目录。特点:增
【K8s】专题十一:Kubernetes 集群证书过期处理方法
行者Sun1989
Kuberneteskubernetes云原生容器
本文内容均来自个人笔记并重新梳理,如有错误欢迎指正!如果对您有帮助,烦请点赞、关注、转发、订阅专栏!专栏订阅入口Linux专栏|Docker专栏|Kubernetes专栏往期精彩文章【Docker】(全网首发)KylinV10下MySQL容器内存占用异常的解决方法【Docker】(全网首发)KylinV10下MySQL容器内存占用异常的解决方法(续)【Docker】MySQL源码构建Docker镜
Java面试笔记记录6
今天背八股了吗
java面试笔记
1.Spring是什么?特性?有哪些模块?Spring是一个轻量级、非入侵式的控制反转Ioc和面向切面AOP的框架。特性:1.Ioc和DISpring的核心就是一个大的工厂容器,可以维护所有对象的创建和依赖关系,Spring工厂用于生成Bean,并且管理Bean的生命周期,实现高内聚低耦合的设计理念。2.AOP编程Spring提供面向切面编程,可以方便实现对程序进行权限拦截、运行监控等切面功能。3
分享一个基于python的电子书数据采集与可视化分析 hadoop电子书数据分析与推荐系统 spark大数据毕设项目(源码、调试、LW、开题、PPT)
计算机源码社
Python项目大数据大数据pythonhadoop计算机毕业设计选题计算机毕业设计源码数据分析spark毕设
作者:计算机源码社个人简介:本人八年开发经验,擅长Java、Python、PHP、.NET、Node.js、Android、微信小程序、爬虫、大数据、机器学习等,大家有这一块的问题可以一起交流!学习资料、程序开发、技术解答、文档报告如需要源码,可以扫取文章下方二维码联系咨询Java项目微信小程序项目Android项目Python项目PHP项目ASP.NET项目Node.js项目选题推荐项目实战|p
Docker学习十一:Kubernetes概述
爱打羽球的程序猿
Docker学习系列dockerkubernetes学习
一、Kubernetes简介2006年,Google提出了云计算的概念,当时的云计算领域还是以虚拟机为代表的云平台。2013年,Docker横空出世,Docker提出了镜像、仓库等核心概念,规范了服务的交付标准,使得复杂服务的落地变得更加简单,之后Docker又定义了OCI标准,Docker在容器领域称为事实的标准。但是,Docker诞生只是帮助定义了开发和交付标准,如果想要在生产环境中大批量的使
Halo 开发者指南——容器私有化部署
SHENHUANJIE
DockerHalo华为云SWRRegistry
华为云SWR私有化部署镜像构建dockerbuild-thalo-dev/halo:2.20.0.上传镜像镜像标签sudodockertag{镜像名称}:{版本名称}swr.cn-south-1.myhuaweicloud.com/{组织名称}/{镜像名称}:{版本名称}sudodockertaghalo-dev/halo:2.20.0swr.cn-south-1.myhuaweicloud.co
小白 | 华为云docker设置镜像加速器
伏一
工具安装华为云docker容器
一、操作场景通过dockerpull命令下载镜像中心的公有镜像时,往往会因为网络原因而需要很长时间,甚至可能因超时而下载失败。为此,容器镜像服务提供了镜像下载加速功能,帮助您获得更快的下载体验。二、约束与限制构建镜像的客户端所安装的容器引擎(Docker)版本必须为1.11.2及以上。“华北-乌兰察布一”、“亚太-雅加达”、“拉美-墨西哥城一”、“拉美-墨西哥城二”和“拉美-圣保罗一”区域不支持该
docker改容器IP的两种方法
redmond88
linuxdockertcp/ip容器
最简单实用的方法:docker默认的内网网段为172.17.0.0/16,如果公司内网网段也是172.17.x.x的话,就会发生路由冲突。解决办法改路由比较办法,可以一开始就将docker配置的bip改成169.254.0.1/24,可以避免冲突。在daemon配置文件里加个"bip":“169.254.0.1/24”,重启docker就可以了1234[root@st-dev6~]#vim/etc
java获取applicationcontext,SpringBoot获取ApplicationContext的3种方式
花儿街参考
ApplicationContext是什么?简单来说就是Spring中的容器,可以用来获取容器中的各种bean组件,注册监听事件,加载资源文件等功能。ApplicationContext获取的几种方式1直接使用Autowired注入@ComponentpublicclassBook1{@AutowiredprivateApplicationContextapplicationContext;pub
(k8s)Kubernetes 从0到1容器编排之旅
道不贱卖,法不轻传
kubernetskubernetes容器云原生
一、引言在当今数字化的浪潮中,Kubernetes如同一艘强大的航船,引领着容器化应用的部署与管理。它以其卓越的灵活性、可扩展性和可靠性,成为众多企业和开发者的首选。然而,要真正发挥Kubernetes的强大威力,仅仅掌握基本操作是远远不够的。本文将带你深入探索Kubernetes使用过程中的奇技妙法,为你开启一段优雅的容器编排之旅。二、高级资源管理之精妙艺术1.资源配额与限制:雕琢资源之美•Ku
SpringBoot 获取 ApplicationContext
loveLifeLoveCoding
springbootspringbootjavaspring
1.概念ApplicationContext是什么?简单来说就是Spring中的容器,可以用来获取容器中的各种bean组件,注册监听事件,加载资源文件等功能2.获取ApplicationContext的方式2.1.创建工具类通过此工具类,可以方便的获取bean组件,获取配置信息等importorg.springframework.beans.BeansException;importorg.spr
docker 安装、运行nginx shell脚本
三希
dockernginx容器
以下是一个简单的用于安装和运行DockerNginx的shell脚本:bash#!/bin/bash#安装Docker(如果还未安装)#请根据实际情况调整安装命令#拉取Nginx镜像dockerpullnginx#运行Nginx容器dockerrun-d--namemynginx-p80:80nginx
Spark 组件 GraphX、Streaming
叶域
大数据sparkspark大数据分布式
Spark组件GraphX、Streaming一、SparkGraphX1.1GraphX的主要概念1.2GraphX的核心操作1.3示例代码1.4GraphX的应用场景二、SparkStreaming2.1SparkStreaming的主要概念2.2示例代码2.3SparkStreaming的集成2.4SparkStreaming的应用场景SparkGraphX用于处理图和图并行计算。Graph
docker项目切换(nginx)、重启shell 脚本
懒惰的小蜗牛
dockerdockernginx容器
docker项目切换、重启脚本背景具体操作nginx配置配置文件1配置文件2编写nginx替换脚本(用来执行端口替换)编写启动脚本dockerfile文件正常编写给脚本授权执行./start脚本背景项目部署docker中,更新项目时,需要将原原来的容器停止,再启动新的容器,这样会有一个空窗期,导致不可用解决方案:映射不同的端口并启动新的容器,将nginx转发到新容器,停止旧容器具体操作说明ngin
Servlet容器的作用、HttpServlet的工作机制流程图
烟雨国度
servlet流程图hive
HttpServletRequest解析过程是否GETPOST其他方法Servlet生命周期init-初始化Servletservice-处理请求destroy-销毁ServletgetMethod返回HTTP方法getRequestURI返回请求URIgetQueryString返回查询字符串getParameter返回特定参数值客户端发送HTTP请求服务器接收请求Web容器创建ServletR
apache ftpserver-CentOS config
gengzg
apache
<server xmlns="http://mina.apache.org/ftpserver/spring/v1"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://mina.apache.o
优化MySQL数据库性能的八种方法
AILIKES
sqlmysql
1、选取最适用的字段属性 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快。因此,在创建表的时候,为了获得更好的 性能,我们可以将表中字段的宽度设得尽可能小。例如,在定义邮政编码这个字段时,如果将其设置为CHAR(255),显然给数据库增加了不必要的空间,甚至使用VARCHAR这种类型也是多余的,因为CHAR(6)就可以很
JeeSite 企业信息化快速开发平台
Kai_Ge
JeeSite
JeeSite 企业信息化快速开发平台
平台简介
JeeSite是基于多个优秀的开源项目,高度整合封装而成的高效,高性能,强安全性的开源Java EE快速开发平台。
JeeSite本身是以Spring Framework为核心容器,Spring MVC为模型视图控制器,MyBatis为数据访问层, Apache Shiro为权限授权层,Ehcahe对常用数据进行缓存,Activit为工作流
通过Spring Mail Api发送邮件
120153216
邮件main
原文地址:http://www.open-open.com/lib/view/open1346857871615.html
使用Java Mail API来发送邮件也很容易实现,但是最近公司一个同事封装的邮件API实在让我无法接受,于是便打算改用Spring Mail API来发送邮件,顺便记录下这篇文章。 【Spring Mail API】
Spring Mail API都在org.spri
Pysvn 程序员使用指南
2002wmj
SVN
源文件:http://ju.outofmemory.cn/entry/35762
这是一篇关于pysvn模块的指南.
完整和详细的API请参考 http://pysvn.tigris.org/docs/pysvn_prog_ref.html.
pysvn是操作Subversion版本控制的Python接口模块. 这个API接口可以管理一个工作副本, 查询档案库, 和同步两个.
该
在SQLSERVER中查找被阻塞和正在被阻塞的SQL
357029540
SQL Server
SELECT R.session_id AS BlockedSessionID ,
S.session_id AS BlockingSessionID ,
Q1.text AS Block
Intent 常用的用法备忘
7454103
.netandroidGoogleBlogF#
Intent
应该算是Android中特有的东西。你可以在Intent中指定程序 要执行的动作(比如:view,edit,dial),以及程序执行到该动作时所需要的资料 。都指定好后,只要调用startActivity(),Android系统 会自动寻找最符合你指定要求的应用 程序,并执行该程序。
下面列出几种Intent 的用法
显示网页:
Spring定时器时间配置
adminjun
spring时间配置定时器
红圈中的值由6个数字组成,中间用空格分隔。第一个数字表示定时任务执行时间的秒,第二个数字表示分钟,第三个数字表示小时,后面三个数字表示日,月,年,< xmlnamespace prefix ="o" ns ="urn:schemas-microsoft-com:office:office" />
测试的时候,由于是每天定时执行,所以后面三个数
POJ 2421 Constructing Roads 最小生成树
aijuans
最小生成树
来源:http://poj.org/problem?id=2421
题意:还是给你n个点,然后求最小生成树。特殊之处在于有一些点之间已经连上了边。
思路:对于已经有边的点,特殊标记一下,加边的时候把这些边的权值赋值为0即可。这样就可以既保证这些边一定存在,又保证了所求的结果正确。
代码:
#include <iostream>
#include <cstdio>
重构笔记——提取方法(Extract Method)
ayaoxinchao
java重构提炼函数局部变量提取方法
提取方法(Extract Method)是最常用的重构手法之一。当看到一个方法过长或者方法很难让人理解其意图的时候,这时候就可以用提取方法这种重构手法。
下面是我学习这个重构手法的笔记:
提取方法看起来好像仅仅是将被提取方法中的一段代码,放到目标方法中。其实,当方法足够复杂的时候,提取方法也会变得复杂。当然,如果提取方法这种重构手法无法进行时,就可能需要选择其他
为UILabel添加点击事件
bewithme
UILabel
默认情况下UILabel是不支持点击事件的,网上查了查居然没有一个是完整的答案,现在我提供一个完整的代码。
UILabel *l = [[UILabel alloc] initWithFrame:CGRectMake(60, 0, listV.frame.size.width - 60, listV.frame.size.height)]
NoSQL数据库之Redis数据库管理(PHP-REDIS实例)
bijian1013
redis数据库NoSQL
一.redis.php
<?php
//实例化
$redis = new Redis();
//连接服务器
$redis->connect("localhost");
//授权
$redis->auth("lamplijie");
//相关操
SecureCRT使用备注
bingyingao
secureCRT每页行数
SecureCRT日志和卷屏行数设置
一、使用securecrt时,设置自动日志记录功能。
1、在C:\Program Files\SecureCRT\下新建一个文件夹(也就是你的CRT可执行文件的路径),命名为Logs;
2、点击Options -> Global Options -> Default Session -> Edite Default Sett
【Scala九】Scala核心三:泛型
bit1129
scala
泛型类
package spark.examples.scala.generics
class GenericClass[K, V](val k: K, val v: V) {
def print() {
println(k + "," + v)
}
}
object GenericClass {
def main(args: Arr
素数与音乐
bookjovi
素数数学haskell
由于一直在看haskell,不可避免的接触到了很多数学知识,其中数论最多,如素数,斐波那契数列等,很多在学生时代无法理解的数学现在似乎也能领悟到那么一点。
闲暇之余,从图书馆找了<<The music of primes>>和<<世界数学通史>>读了几遍。其中素数的音乐这本书与软件界熟知的&l
Java-Collections Framework学习与总结-IdentityHashMap
BrokenDreams
Collections
这篇总结一下java.util.IdentityHashMap。从类名上可以猜到,这个类本质应该还是一个散列表,只是前面有Identity修饰,是一种特殊的HashMap。
简单的说,IdentityHashMap和HashM
读《研磨设计模式》-代码笔记-享元模式-Flyweight
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashMap;
import java.util.List;
import java
PS人像润饰&调色教程集锦
cherishLC
PS
1、仿制图章沿轮廓润饰——柔化图像,凸显轮廓
http://www.howzhi.com/course/retouching/
新建一个透明图层,使用仿制图章不断Alt+鼠标左键选点,设置透明度为21%,大小为修饰区域的1/3左右(比如胳膊宽度的1/3),再沿纹理方向(比如胳膊方向)进行修饰。
所有修饰完成后,对该润饰图层添加噪声,噪声大小应该和
更新多个字段的UPDATE语句
crabdave
update
更新多个字段的UPDATE语句
update tableA a
set (a.v1, a.v2, a.v3, a.v4) = --使用括号确定更新的字段范围
hive实例讲解实现in和not in子句
daizj
hivenot inin
本文转自:http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2842855.html
当前hive不支持 in或not in 中包含查询子句的语法,所以只能通过left join实现。
假设有一个登陆表login(当天登陆记录,只有一个uid),和一个用户注册表regusers(当天注册用户,字段只有一个uid),这两个表都包含
一道24点的10+种非人类解法(2,3,10,10)
dsjt
算法
这是人类算24点的方法?!!!
事件缘由:今天晚上突然看到一条24点状态,当时惊为天人,这NM叫人啊?以下是那条状态
朱明西 : 24点,算2 3 10 10,我LX炮狗等面对四张牌痛不欲生,结果跑跑同学扫了一眼说,算出来了,2的10次方减10的3次方。。我草这是人类的算24点啊。。
然后么。。。我就在深夜很得瑟的问室友求室友算
刚出完题,文哥的暴走之旅开始了
5秒后
关于YII的菜单插件 CMenu和面包末breadcrumbs路径管理插件的一些使用问题
dcj3sjt126com
yiiframework
在使用 YIi的路径管理工具时,发现了一个问题。 <?php
对象与关系之间的矛盾:“阻抗失配”效应[转]
come_for_dream
对象
概述
“阻抗失配”这一词组通常用来描述面向对象应用向传统的关系数据库(RDBMS)存放数据时所遇到的数据表述不一致问题。C++程序员已经被这个问题困扰了好多年,而现在的Java程序员和其它面向对象开发人员也对这个问题深感头痛。
“阻抗失配”产生的原因是因为对象模型与关系模型之间缺乏固有的亲合力。“阻抗失配”所带来的问题包括:类的层次关系必须绑定为关系模式(将对象
学习编程那点事
gcq511120594
编程互联网
一年前的夏天,我还在纠结要不要改行,要不要去学php?能学到真本事吗?改行能成功吗?太多的问题,我终于不顾一切,下定决心,辞去了工作,来到传说中的帝都。老师给的乘车方式还算有效,很顺利的就到了学校,赶巧了,正好学校搬到了新校区。先安顿了下来,过了个轻松的周末,第一次到帝都,逛逛吧!
接下来的周一,是我噩梦的开始,学习内容对我这个零基础的人来说,除了勉强完成老师布置的作业外,我已经没有时间和精力去
Reverse Linked List II
hcx2013
list
Reverse a linked list from position m to n. Do it in-place and in one-pass.
For example:Given 1->2->3->4->5->NULL, m = 2 and n = 4,
return
Spring4.1新特性——页面自动化测试框架Spring MVC Test HtmlUnit简介
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
Hadoop集群工具distcp
liyonghui160com
1. 环境描述
两个集群:rock 和 stone
rock无kerberos权限认证,stone有要求认证。
1. 从rock复制到stone,采用hdfs
Hadoop distcp -i hdfs://rock-nn:8020/user/cxz/input hdfs://stone-nn:8020/user/cxz/运行在rock端,即源端问题:报版本
一个备份MySQL数据库的简单Shell脚本
pda158
mysql脚本
主脚本(用于备份mysql数据库): 该Shell脚本可以自动备份
数据库。只要复制粘贴本脚本到文本编辑器中,输入数据库用户名、密码以及数据库名即可。我备份数据库使用的是mysqlump 命令。后面会对每行脚本命令进行说明。
1. 分别建立目录“backup”和“oldbackup” #mkdir /backup #mkdir /oldbackup
300个涵盖IT各方面的免费资源(中)——设计与编码篇
shoothao
IT资源图标库图片库色彩板字体
A. 免费的设计资源
Freebbble:来自于Dribbble的免费的高质量作品。
Dribbble:Dribbble上“免费”的搜索结果——这是巨大的宝藏。
Graphic Burger:每个像素点都做得很细的绝佳的设计资源。
Pixel Buddha:免费和优质资源的专业社区。
Premium Pixels:为那些有创意的人提供免费的素材。
thrift总结 - 跨语言服务开发
uule
thrift
官网
官网JAVA例子
thrift入门介绍
IBM-Apache Thrift - 可伸缩的跨语言服务开发框架
Thrift入门及Java实例演示
thrift的使用介绍
RPC
POM:
<dependency>
<groupId>org.apache.thrift</groupId>