如何让模型更具有日常对话的形式--对话系统的可控性
AI TIME欢迎每一位AI爱好者的加入!
对话系统的可控性对于实用系统来说是一个至关重要的问题。第三期AI Time PhD对话系统专题分享的直播间,我们邀请到清华大学计算机系博士后、交互式人工智能组成员郑银河,为大家介绍最新研究成果。
本次分享中,郑银河及其团队将在自然语言生成(NLG)和自然语言理解(NLU)两个方面讨论了对话系统的可控性:首先介绍如何在生成自然语言回复的过程中融入特定的个性化信息,然后讨论如何在自然语言理解模块中有效地识别用户的异常输入。

郑银河,清华大学计算机系与北京三星研究院联合培养博士后,交互式人工智能组(CoAI)成员,博士后合作导师是黄民烈副教授。主要研究方向为对话系统中的自然语言生成与自然语言理解。曾在AAAI, ENMLP, IEEE TASLP等顶级会议与期刊上发表数篇论文。

一、对话系统中的NLU和NLG
自然语言理解(NLU):对来自用户的自然语言描述进行识别,解析成结构化的信息;
自然语言生成(NLG):将结构化的语义数据转换成人可以理解的语言格式,如对话回复、文章、报告等。
NLP = NLU + NLG
NLU 负责理解内容,NLG 负责生成内容。

在本次分享中所提到的NLU的可控性和NLG的可控性包括以下部分:
NLU的可控性:准确地剔除输入中的无效指令和异常指令;
NLG的可控性:生成带有特定特征和内容的对话回复。
二、自然语言生成-个性化回复生成
a)
数据集
传统:PersonaChat 数据集 (“Personalizing Dialogue Agents I have a dog, do you have pets too”)
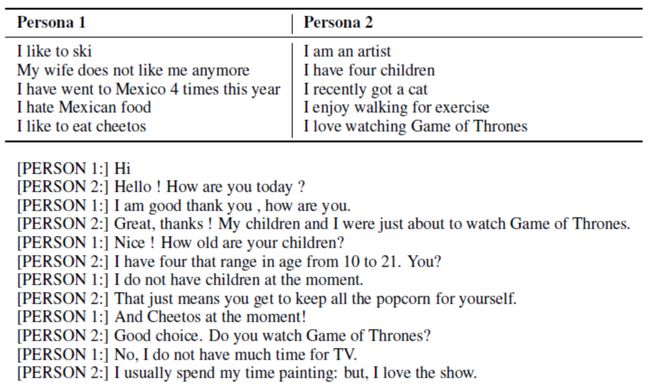
在PersonaChat的收集过程中,要求对话双方尽快地展现自己的个性化信息,因此使用这一数据集得到的对话模型会尽可能多地在回复中展现个性化属性。
现实使用的数据集:PersonaDialog

在真正的日常对话中,个性化信息是相对稀疏的,每一个对话中并不会都包含个性化信息。因此本文解决了以下两个问题:
在预训练对话模型中使用了个性化稀疏的对话数据集;
提出了注意力路由机制,通过这个机制可以控制所生成的回复中个性化特征的展现程度。
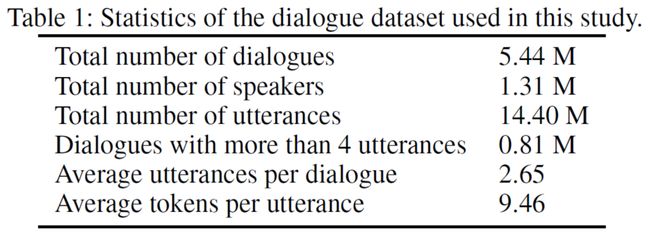
本文所使用的数据集来源为微博对话,有如下特点:
对话数量多,规模大
提供了发话人的三种个性化属性(“性别”,“地域”和“兴趣标签”)
使用了两个测试集:一个随机测试集和一个有偏的测试集
随机测试集包含一万条对话,这些对话是随机采样的,因此这些对话大多数都不包含个性化信息。因此,随机测试集提供的上下文是个性化信息稀疏的。而有偏数据集是经过人工筛选得到的,在有偏数据集中,我们保证所筛选出来的对话都是与个性化信息相关的。
b)
对话模型
任务描述:

输入包含两个:
当前的对话历史X。
回复者的个性化描述T。这一描述使用键值对的形式给出。
输出:
回复语句Y。我们可以选择是否在Y中展示个性化属性T。
模型:

个性化对话生成模型的框架。编码器和解码器共享相同的参数。使用编码器对话上下文和目标个性化属性进行独立编码,并将其编码结果输入到解码器中的注意路由模块。注意力路由模块同时还会接收一个动态权重预测器的输出来衡量每种输入的贡献。这一模型主要有两个创新点,分别是Attribute Embedding 属性嵌入和Attention Routing 注意力路由机制。
Attribute Embedding 属性嵌入:

1.词嵌入
2.位置嵌入
3.属性嵌入(性别嵌入,位置嵌入,标签嵌入)
编码器的输入包含有三部分,分别是单词嵌入,位置嵌入和属性嵌入。本文对三种类型的属性嵌入进行了独立建模,即性别嵌入,位置嵌入和兴趣标签嵌入。由于每个说话者可能具有几个兴趣标签,因此对对话者的所有兴趣标签表示的平均值作为兴趣标签嵌入。
Attention Routing 注意力路由机制:
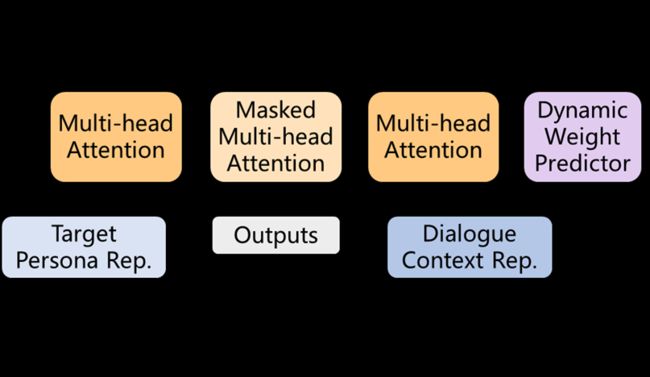
在这项研究中,研究者设计了一种动态权重预测器,在训练阶段根据对话上下文自动计算当前对话是否与个性化属性相关。
此外,还包含有三个平行的注意力路由,具体来说,每个路由分别接收如下输入:发话人个性化信息Et,对话上下文Ec和先前解码的标签E prev。通过施加不同的权重,调整发话人的个性化信息对解码的影响。
c)
模型性能评估:

表2和表3分别显示了随机和有偏测试集的性能。除了困惑度之外,模型在所有指标上的表现均表现优异。

展示过多的个性化信息会损害响应流畅性和上下文一致性。并且动态权重预测器可以在角色一致性和上下文一致性之间提供更好的平衡。
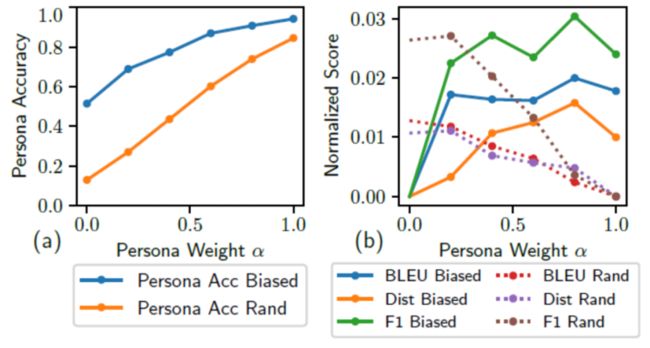
此外,本文进一步评估了角色权重α对生成的响应的影响。计算了个性化准确度,BLEU,F1和与不同α值相对应的独特性的得分。观察到:1)个性化准确度随α迅速增加(图a)。这表明当α较大时,更多的与个性化相关的特征将被合并到解码的响应中。2)当α增大时,随机测试集上的BLEU,F1和distinct分数降低(图b中的虚线)。3)在有偏的测试集上观察到BLEU,F1和与众不同的明显增加趋势,但是当α达到1时,性能会下降(图b中的实线)。这表明生成更多与个性化相关的响应会导致在个性化密集环境中获得更好的性能,但是仅追求个性化一致性可能会损害其他维度的性能。
三、自然语言理解- NLU中的异常输入检测
自然语言理解(NLU)是对话系统的重要组成部分,并且其异常输入检测(OOD)的能力在实际应用中至关重要,因为接受当前系统不支持的OOD输入可能导致灾难性的后果。但是,大多数现有的OOD检测方法都严重依赖手动标记的OOD样本,无法充分利用未标记的数据。这限制了这些模型在实际应用中的可行性。本研究中提出了一种可以生成伪OOD数据的方法。
a)
OOD数据生成模型:

生成伪OOD数据的模型包括:(1)编码器和解码器;(2)对抗生成网络;(3)辅助分类器。产生有效的伪OOD样本的想法源自这一观察结果:大多数OOD样本看起来与正常输入相似,但不属于任何正常输入所对应的意图。
b)
实验验证

对于OSQ数据集,将一万正常输入数据和250 OOD数据混合作用于Dmax;对于IPA数据集,从用户日志中提取两万未标记的对话,并将其用作Dmax。
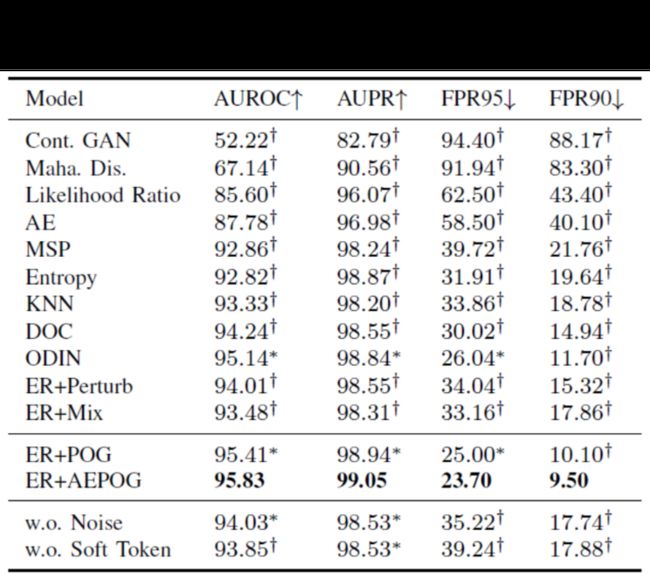
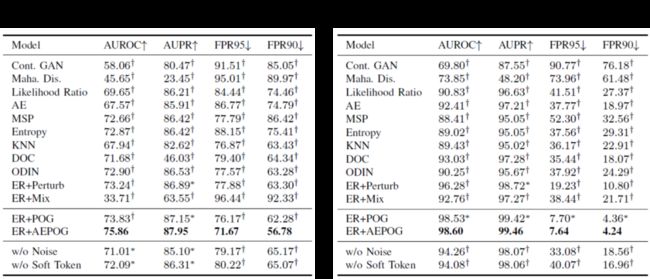
1)与OSQ数据集相比,在IPA数据集上检测OOD样本更加困难。这是因为IPA测试数据中的大多数OOD输入看起来都与正常输入相似。
2)提出的ER + POG模型在FPRN指标上获得了很大的改进。这表明由于FPRN直接反映了已部署模型的性能,因此所提出的模型更适合实际应用。
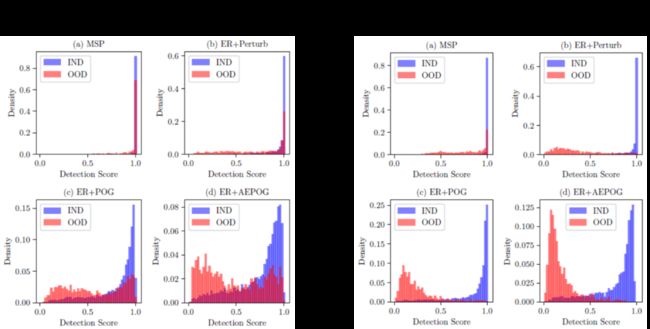
作者还分析了在OSQ和IPA数据集上从不同模型获得的检测分数的分布。用POG模型生成的伪OOD话语优化ER项时,可以观察到IND和OOD输入之间更好的检测分数分离,AEPOG生成的语句则扩大了这种分离使用模型。这表明模型生成的伪OOD语句有助于OOD检测,并且在利用未标记数据时可以进一步提高这些伪OOD语句的有效性。

对于OOD样本,通过ER项进行正则化的分类器可为IND和OOD样本提供更多可区分的特征(图b),并且由POG和AEPOG模型生成的语句增强了这种分离(图c和图d)。这有助于检测OOD输入。
c)
结论
模型可以产生更有效的伪OOD样本
提出的POG模型生成的伪OOD样本可用于提高OOD检测性能
IND样本的性能不受影响
整理:闫昊
审稿:郑银河
AI Time欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你,请将简历等信息发至[email protected]!
微信联系:AITIME_HY
AI Time是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注
(点击“阅读原文”下载本次报告ppt)
(直播回放:https://b23.tv/RrMrrC)