Impala中的invalidate metadata 和refrsh
Impala中的invalidate metadata 和refrsh
Impala是啥子?
Impala是基于Hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata,意味着impala元数据都存储在Hive的metastore中。并且impala兼容Hive的sql解析,实现了Hive的SQL语义的子集,功能还在不断的完善中。
Impala的优点有哪些?
- Impala不需要把中间结果写入磁盘,省掉了大量的I/O开销。
- 省掉了MapReduce作业启动的开销。MapReduce启动task的速度很慢(默认每个心跳间隔是3秒钟),Impala直接通过相应的服务进程来进行作业调度,速度快了很多。
- Impala完全抛弃了MapReduce这个不太适合做SQL查询的范式,而是像Dremel一样借鉴了MPP并行数据库的思想另起炉灶,因此可做更多的查询优化,从而省掉不必要的shuffle、sort等开销。
- 通过使用LLVM来统一编译运行时代码,避免了为支持通用编译而带来的不必要开销。
- 用C++实现,做了很多有针对性的硬件优化,例如使用SSE指令。
- 使用了支持Data locality的I/O调度机制,尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销。
Impala功能有哪些?
- Impala可以根据Apache许可证作为开源免费提供。
- Impala支持内存中数据处理,它访问/分析存储在Hadoop数据节点上的数据,而无需数据移动。
- 使用类SQL查询访问数据。
- Impala为HDFS中的数据提供了更快的访问。
- 可以将数据存储在Impala存储系统中,如Apache HBase和Amazon s3。
- Impala支持各种文件格式,如LZO,序列文件,Avro,RCFile和Parquet。
Impala与Hive有什么关系?
Impala 与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很多的共同之处,如数据表元数据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资源池等。Impala与Hive在Hadoop中的关系如下图所示。Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给数据分析人员提供了快速实验、验证想法的大数 据分析工具。可以先使用hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进行快速的数据分析。
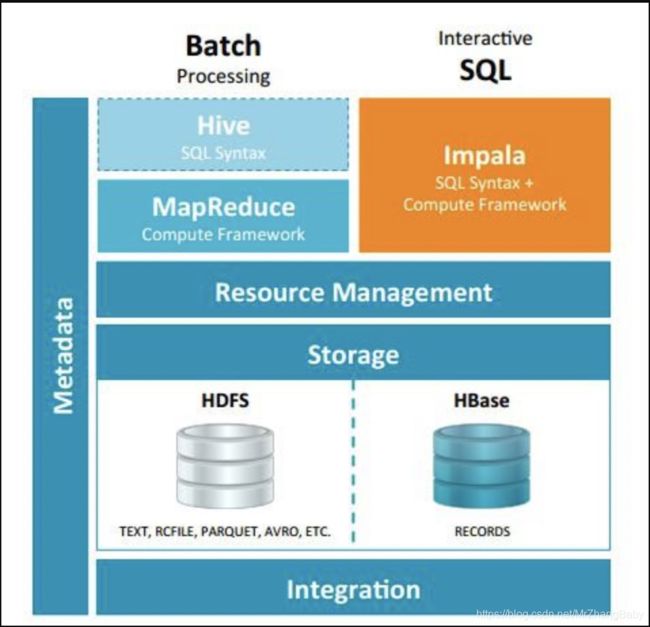
Impala没有使用 MapReduce进行并行计算,虽然MapReduce是非常好的并行计算框架,但它更多的面向批处理模式,而不是面向交互式的SQL执行。与 MapReduce相比:Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务,在分发执行计划后,Impala使用拉式获取 数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少的了把中间结果写入磁盘的步骤,再从磁盘读取数据的开销。Impala使用服务的方式避免 每次执行查询都需要启动的开销,即相比Hive没了MapReduce启动时间。
使用LLVM产生运行代码,针对特定查询生成特定代码,同时使用Inline的方式减少函数调用的开销,加快执行效率。充分利用可用的硬件指令(SSE4.2)。更好的IO调度,Impala知道数据块所在的磁盘位置能够更好的利用多磁盘的优势,同时Impala支持直接数据块读取和本地代码计算checksum。通过选择合适的数据存储格式可以得到最好的性能(Impala支持多种存储格式)。最大使用内存,中间结果不写磁盘,及时通过网络以stream的方式传递。
言归正传,为啥来扯invalid metadata 和refresh?
Impala采用了比较奇葩的多个impalad同时提供服务的方式,并且它会由catalogd缓存全部元数据,再通过statestored完成每一次的元数据的更新到impalad节点上,Impala集群会缓存全部的元数据,这种缓存机制就导致通过其他手段更新元数据或者数据对于Impala是无感知的,例如通过hive建表,直接拷贝新的数据到HDFS上等,Impala提供了两种机制来实现元数据的更新,分别是INVALIDATE METADATA和REFRESH操作,下面详细介绍这两个操作。
INVALIDATE METADATA
作废表的元数据和块的位置数据。下一次对元数据无效的表执行查询时,Impala会在查询之前重新加载相关的元数据。
invalid metadata是用于刷新全库或者某个表的元数据,包括表的元数据和表内的文件数据,它会首先清楚表的缓存,然后从metastore中重新加载全部数据并缓存,该操作代价比较重,主要用于在hive中修改了表的元数据,需要同步到impalad,例如create table/drop table/alter table add columns等。
INVALIDATE METADATA 语法:
INVALIDATE METADATA; //重新加载所有库中的所有表
INVALIDATE METADATA [table] //重新加载指定的某个表
REFRESH
刷新特定表的最新元数据和块的位置数据。
Refresh是用于刷新某个表或者某个分区的数据信息,它会重用之前的表元数据,仅仅执行文件刷新操作,它能够检测到表中分区的增加和减少,主要用于表中元数据未修改,数据的修改,例如INSERT INTO、LOAD DATA、ALTER TABLE ADD PARTITION、LLTER TABLE DROP PARTITION等,如果直接修改表的HDFS文件(增加、删除或者重命名)也需要指定REFRESH刷新数据信息。
REFRESH 语法:
REFRESH [table] //刷新某个表
REFRESH [table] PARTITION [partition] //刷新某个表的某个分区
原理剖析
INVALIDATE METADATA原理
对于INVALIDATE METADATA操作,由客户端将查询提交到某个impalad节点上,执行如下的操作:
- 获取需要执行INVALIDATE METADATA的表,如果没指定表则不设置表示全部表(不考虑这种情况)。
- 请求catalogd执行resetMetadata操作,并将isFresh参数设置为false。
- catalogd接收到该请求之后执行invalidateTable操作,将该表的缓存清除,然后重新生成该表的缓存对象,新生成的对象只包含表名+库名的信息,为新生成的表对象生成一个新的catalog版本号(假设新的version=1),将这部分信息返回给调用方(impalad),然后异步执行元数据和数据的加载。
- impalad收到catalogd的返回值,返回值是更新之后的表缓存对象+版本号,但是这是一个不完整的表元数据,impalad将这个元数据应用到本地元数据缓存。
- INVALIDATE METADATA执行完成。
INVALIDATE METADATA操作带来的副作用是生成一个新的未完成的元数据对象,对于操作请求的impalad(称它为impalad-A),能够立马获取到该对象,对于其它的impalad需要通过statestored同步,因此执行完该操作,处理该操作的impalad对于该表的缓存是一个新的但是不完整的对象,其余的impalad保存的是旧的元数据。
对于后续的该表查询操作,分为如下四种情况:
- 如果catalogd已经完成该表所有元数据加载,会对该表生成一个新的版本号(假设version=2),然后更新到statestored,由statestored广播到各个impalad节点上,此时所有的查询都查询到最新的元数据和数据。
- 如果catalogd尚未完成表的元数据加载或者statestored未广播完成,并且接下来请求到impalad-A(之前执行INVALIDATE METADATA的节点),此时impalad在执行语义分析的时候能够检测到表的元数据不完整(因为当前只有表名和库名,没有任何其余的元数据),impalad会直接请求catalogd获取该表最新的元数据,如果catalogd尚未完成元数据加载,则该请求会等到直到catalogd加载完成并返回impalad最新的元数据。
- 如果catalogd尚未完成表的元数据加载或statestored未广播完成,接下来请求到了其他的impalad节点,如果接受请求的impalad尚未通过statestored同步新的不完整的表元数据(version=1),则该impalad中缓存的关于该表的元数据是执行INVALIDATE METADATA之前的,因此根据旧的元数据处理该查询(可能因为文件被删除导致错误)。
- 如果catalogd尚未完成表的元数据加载,接下来请求到了其他的impalad节点,如果接受请求的impalad已经通过statestored同步新的不完整的表元数据(version=1),那么接下来会像第二种情况一样处理。
从INVALIDATE METADATA的实现来看,该操作不仅仅会全量加载表的元数据和分区、文件元数据,还会影响后面关于该表的查询。
REFRESH原理
对于REFRESH操作,由客户端将查询提交到某个impalad节点上,执行如下的操作:
- 获取需要执行REFRESH的表和分区信息。
- 请求catalogd执行resetMetadata操作,并将isFresh参数设置为true。
- catalogd接收到该请求之后判断是否指定分区,如果指定了分区则执行reload partition操作,如果未指定则执行reload table操作,对于reloadPartition则从metastore中读取partition最新的元数据,然后刷新该partition拥有的所有文件的元数据(大小,权限,数据分布等);对于reloadTable则从metadata中读取全部的partition信息,然后和缓存中的partition进行比对判断是否有分区需要增加和删除,对于其余的分区则执行元数据的更新。
- impalad收到catalogd的返回值,返回值是更新之后该表的缓存数据,impalad会将该数据更新到自己的缓存中。因此接受请求的impalad能够将当前元数据缓存。
- REFRESH执行完成。
对于后续的查询,分为如下两种情况:
- 如果查询提交到到执行REFRESH的impalad节点,那么查询能够使用最新的元数据。
- 如果查询提交到其他impalad节点,需要依赖于该表0更新后的缓存是否已经同步到impalad中,如果已经完成了同步则可以使用最新的元数据,如果未完成则使用旧的元数据。
可以看出REFRESH操作较之于INVALIDATE METADATA是轻量级的操作,如果更改只涉及到一个分区设置可以只刷新一个分区的元数据,并且它是同步的,对于之后查询的影响较小。
使用场景
invalid metadata
- 适用于当前Impala节点不知道的Hive表,如在Hive中
Create了新表或新库。 - 在Hive中
Drop了表或库。 - 可用于刷新整个库的所有表。
注意:在生产中应避免使用INVALIDATE METADATA什么都不加。对于具有大量数据或有许多分区的表而言,检索表的所有元数据可能非常耗时,且都加载到内存也非常浪费空间。
refresh
- 适用于当前Impala节点已经知道的Hive表。
- 在Hive中执行
ALTER TABLE,INSERT,LOAD DATA语句之后。如ALTER TABLE ADD/DROP PARTITION语句。 - Hive表在HDFS上某个分区目录数据发生变化后。
REFRESH必须指定一个表。即:不能用于刷新整个库的所有表。REFRESH是增量更新,比INVALIDATE METADATA代价要小很多,在既能使用REFRESH也能使用INVALIDATE METADATA的场景下,用REFRESH。
测试
Impala在各个业务使用中成为焦点,但是在Impala的使用上感觉一直不是很成熟,比如说 invalidate metadata操作,到底什么时候该使用-r参数,什么时候不使用,什么时候可以用refresh代替,什么时候不可以?最扯的是,搞了一波操作,找不到表了~
下面对各种操作进行了一个测试,结果如下
除了对hdfs进行操作外,只要通过impala的命令执行的数据修改,一律不需要进行元数据的同步工作,这就意味着,基本上所有脚本的-r参数都可以删除,查询语句的时候也不需要使用-r参数,如果害怕数据过期,那么断开重新连接即可。
**注意:**唯一需要注意的就是,只要对hdfs进行了操作,就需要执行元数据的更新的操作,根据Impala官方的建议,这种情况完全可以使用refresh tablename操作,而不必加-r参数。
参考链接:
https://blog.csdn.net/zhaodedong/article/details/51154205?utm_source=blogxgwz4
https://blog.csdn.net/yu616568/article/details/72780346