【GCN】: IntentGC算法框架
本篇论文是阿里发表在kdd2019的文章,是gcn在淘宝场景下的实际应用,还提供了源码,很具有可读性。
论文地址:https://arxiv.org/pdf/1907.12377.pdf
作者在论文里面附有对应的代码地址:https://github.com/peter14121/intentgc-models
论文提出了一个新的基于GCN的大规模推荐算法框架:IntentGC。该算法框架利用GCN来同时捕获用户偏好和辅助信息的异构关系。
文章提出了如下几点创新:
1.辅助信息的充分利用。作者捕获了大量的异构关系用于提升推荐系统的性能。为了便于建模和提升鲁棒性,作者将一阶相似的辅助关系转换成更加鲁棒的二阶加权关系。比如:如果user1提供了一个query词“Spiderman”,我们认为user1和“Spoderman"具有一阶相似。如果user1和user2都提供了query词“Spoderman","IronMan","Thor",我们认为user1和user2之间具有更加鲁棒的二阶关系。因为他们可能都是漫威的粉丝。对于不同类型的辅助对象,就可以生成二阶相似度的异构关系。异构关系能显著的提升模型性能。
2.更快的图卷机。为了避免在训练的时候构造mini-graph,提出了一个新的卷机网络:IntentNet。该算法比GraphSage更高效更有效。算法核心思想是通过将图卷机分为两部分来避免不必要的特征交互。
3.异构网络中的对偶图卷机。 为了保持user和item之间的异构性,设计了一个对偶图卷机模型用于网络表示学习。第一:利用IntentNet分别学习user节点和item节点。然后将对应的输出利用全联接网络映射到同一空间。这里作者也尝试将辅助信息作为节点的输入特征,但是共享了这些输入特征的节点,在经过复杂的神经网络映射后,在高层嵌入空间并不会很接近。而直接把这种辅助信息作为图中的一种关系,并利用IntentGC直接学习节点之间的关系,能显著提升性能。(这一点我也不是很理解,我的感觉是作为特征输入,不是应该会让节点直接具有更强的关联性吗?)
文章主要贡献如下:
1.提出框架IntentGC,一个有效的图卷机框架。且这是将用户显示偏好和异构关系统一在一个框架中的第一份工作。
2.设计了一个利用了faster gc 机制的图卷机算法IntentNet。
问题定义
1.Heterogeneous Information Network (HIN 异构信息网络) 指的是一个无向图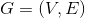 ,V是所有的节点集合,E是VxV的边的集合。每个节点可能属于不同类型,每条边也可能属于不同的类型,当节点类型大于1或者/并且边的类型大于1,就说该图为异构信息网络。V可以表示为
,V是所有的节点集合,E是VxV的边的集合。每个节点可能属于不同类型,每条边也可能属于不同的类型,当节点类型大于1或者/并且边的类型大于1,就说该图为异构信息网络。V可以表示为![]() ,其中
,其中![]() 表示类型r的节点集合。R是类型的总数量。
表示类型r的节点集合。R是类型的总数量。
2.User-Item Recommendation 针对推荐系统,文章将V1表示为user节点,V2表示为item节点,之后的V3 到VR再用来表示其他类型的节点(搜索词,品牌等等)。其中边的集合![]() 这里的
这里的![]() 表示user节点和item节点的边,剩下的边都都属于
表示user节点和item节点的边,剩下的边都都属于![]() 。然后就可以用历史行为构造 ,用未来的数据构造
。然后就可以用历史行为构造 ,用未来的数据构造![]() ,将推荐问题转化为链接预测问题。
,将推荐问题转化为链接预测问题。
文章的提出的方法包括三个关键点
1.Network Translation
将原始的图翻译成一个制定类型的HIN。
2.Faster Convolutional Network:IntentNet
采用向量维度的卷积方法来优化异构关系
3.Vector-wise convolution operation
在翻译的网络上,同时学习user和item的embedding表示。
Network Translation

如图2所示,异构节点和关系不仅提供来丰富的信息,但也引入来以兼容的语义信息和更多的挑战。在推荐系统中,我们只关心user和item的embedding表示。基于这个,文章采用来一个将原始的辅助关系翻译成user-user关系或者item-item关系。直观的,如果user1 和user2都和辅助节点Vr(r>2)有关联,那么user1和user2之间就存在一个非直接的关系,所以本文采用来这种二阶的相似度来捕获user之间或者item之间的相似度,相似度大小就直接由他们之间共有的相同类型下的相同邻域个数来表示。基于这种方法就可以把辅助节点带来的语义信息编码近异构的uu关系或者ii关系中。
先从简单的开始,如果只有一个类型的辅助节点,即![]() ,通过在原始的HIN中增加一个新的二阶关系,并移除原始的辅助关系就可以获得一个新的HIN
,通过在原始的HIN中增加一个新的二阶关系,并移除原始的辅助关系就可以获得一个新的HIN ![]() ,其中U和V表示user节点集合和item节点集合,
,其中U和V表示user节点集合和item节点集合,![]() 是user和item之间的交互,
是user和item之间的交互,![]() 和
和![]() 通过辅助信息生成的user之间或者item之间的链接。当前只考虑一种辅助信息的话,那么边的类型只有一种,否则的话边
通过辅助信息生成的user之间或者item之间的链接。当前只考虑一种辅助信息的话,那么边的类型只有一种,否则的话边![]() 和
和![]() 是由多种不同的类型组成。
是由多种不同的类型组成。
然后每条边![]() 的分配一个相似度权重
的分配一个相似度权重![]() ,item的同理。就可以为
,item的同理。就可以为![]() 和
和![]() 构造权重矩阵。并且定义
构造权重矩阵。并且定义![]() 为节点top P相似节点。
为节点top P相似节点。
现在进一步考虑![]() 含有R种类型的节点,对于每一种辅助节点类型,生成uu/ii边,通过这种方式就可以获得2R-4种类型的异构关系。表示为
含有R种类型的节点,对于每一种辅助节点类型,生成uu/ii边,通过这种方式就可以获得2R-4种类型的异构关系。表示为![]() ,并有对应的权重矩阵
,并有对应的权重矩阵![]() ,同样的,节点u和v对应的邻域表示为
,同样的,节点u和v对应的邻域表示为![]() 。这里翻译的图叫做user-item HIN,推荐问题就变成了给定user-item HIN G 预测
。这里翻译的图叫做user-item HIN,推荐问题就变成了给定user-item HIN G 预测![]() 。
。
Faster Convolutional Network:IntentNet
GCN的核心思想是通过局部过滤器对邻域的特征信息进行迭代聚合。但是存在高度的计算复杂度,所以为了应用本文算法在大规模推荐场景,文章提出了一个新的卷积方式
Vector-wise convolution operation
先只考虑一种类型的辅助关系,然后扩展方法到异构关系。这里只用user节点去阐述。图卷积的一层包括两部分:
1.聚合 2.卷积
聚合是一个pooling层,用于从邻域中聚合特征信息,如经典的GraphSage算法,可以形式化为

其中![]() 表示user a在第k-1层卷积后的embedding向量,而AGGREGATE函数就是一个mean pooling。通过这个聚合函数就可以获得节点u的一个统一的领域表示
表示user a在第k-1层卷积后的embedding向量,而AGGREGATE函数就是一个mean pooling。通过这个聚合函数就可以获得节点u的一个统一的领域表示![]()
聚合后的领域embedding和节点本身embedding就可以通过卷积函数进行合并,经典的卷积函数如下:

将聚合步骤获得的节点本身embedding向量和节点邻域embedding向量进行合并,再通过全联接网络获得新的节点embedding向量。本文把这种方式的卷积操作叫做‘bit-wise’卷积。
在表示学习中,卷机操作的目的主要有两个:
1.学习节点和邻域之间的交互,这决定了邻域如何提升结果。
2.学习embedding空间下不同维度的交互,这将自动提取有用的组合特征。
这里关键的点在于节点本身第i维度和邻域第j维度的交互带来的信息量很少,因此并不需要计算所以特征之间的交互。所以提出了一个基于‘vector-wise’的卷积函数

这里所有的参数都是基于向量维度的权重,针对向量维度进行加权。如下图所示

IntentNet
有了卷机操作就可以进一步堆叠卷积层来形成整个网络,一个卷积网络输出的是一个维度的embedding空间,如用户维度的embeding,所以IntentNet将不同网络输出的不同维度的embedding再送入三层全联接网络,学习不同维度的embedding之间的交互。
异构关系
我们进一步将IntentNet扩展去捕获模型中辅助信息的更多异构关系。那么上面的公式

就需要变成

其中![]() 表示第r种领域的聚合向量。
表示第r种领域的聚合向量。
Dual Graph Convolution in HIN
为了将user和item能在同一空间下进行度量,文章分别使用![]() 和
和![]() 去表示user u和item v。另外还对每个user-item链接采样了一个负样本item去形成一个完整的训练组
去表示user u和item v。另外还对每个user-item链接采样了一个负样本item去形成一个完整的训练组![]() 。为user和item分别构造两个IntentNet,
。为user和item分别构造两个IntentNet,![]() 和
和![]() 。通过迭代的运行q次卷积,就能通过
。通过迭代的运行q次卷积,就能通过![]() 和
和![]() 获得user和item的表示
获得user和item的表示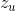 和
和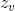 。
。
模型的目标是最小化triplet loss:
![]()
The IntentGC Framework
框架主要包括三部分:
1.网络翻译 2.训练 3.推理 。具体过程如下:

总结
这是最近看的阿里将GCN在大规模推荐场景中的实际应用论文,感觉作出这个框架确实需要一点功夫,希望能从文章获得一些经验,应用在自己的工作中。
完