Python之pandas使用简介
2018/04/15 在我自己记录的时候,通过搜索相关的,发现了一些其他博主写的很全,因为我这里只是记录我遇到的,大家也可以看看其他博主的
https://blog.csdn.net/u011089523/article/details/60349591
http://blog.sina.com.cn/s/blog_154861eae0102xbsq.html
http://www.jb51.net/article/134615.htm
其实我主要也是为了加强自己的记忆,多多练习,有小伙伴也可以多多交流,最近在学机器学习= =要学得到东西是真的多
在pandas中有两类非常重要的数据结构,即序列Series和数据框DataFrame。Series类似于numpy中的一维数组,除了通吃一维数组可用的函数或方法,而且其可通过索引标签的方式获取数据,还具有索引的自动对齐功能;DataFrame类似于numpy中的二维数组,同样可以通用numpy数组的函数和方法,而且还具有其他灵活应用,后续会介绍到。
导入包
进入命令行,敲命令pip install pandas
创建pandas的数据结构
1、Series的创建
1)通过一维数组创建序列
pd.Series(数组)
2)通过字典的方式创建序列
pd.Series(字典)
2、DataFrame的创建
1)通过二维数组创建数据框
pd.DataFrame(数组)
以下以两种字典来创建数据框,一个是字典列表,一个是嵌套字典。
dic2 = {'a':[1,2,3,4],'b':[5,6,7,8],
'c':[9,10,11,12],'d':[13,14,15,16]}
df2 = pd.DataFrame(dic2)
'two':{'a':5,'b':6,'c':7,'d':8},
'three':{'a':9,'b':10,'c':11,'d':12}}
pd.DataFrame(dic3)
3)通过DtatFrame的方式创建数据框
df4 = df3[['one','three']]
s3 = df3['one']
查看索引 :df.index
查看列标签:df.columns
删除行索引重排:
ser.reset_index(drop = True)
df.reset_index(drop = True)
------------------------------------------
直接修列索引:
df = pd.DataFrame(df,columns = ['One','Two','Three'])
方法用法:
import pandas as pd
1、读取/保存为csv文件
df=pd.read_csv('cancer_data.csv')
df=pd.read_csv('cancer_data.csv',sep='分割号') 如果从csv读取的数据全部融合在一起,你需要用sep分隔
tips:如果是同样在当前的目录下,可以直接输入你的文件名,一般建议输入绝对路劲,我这个是因为使用了jupyter,所以直接放在当前目录下
pd.to_csv('cancer_data.csv')
获取行列数
列数 df.columns.size
行数 df.iloc[:,0].size
df.ix[[0]].values[0][0]#第一行第一列的值
df.ix[[1]].values[0][1]#第二行第二列的值
#获取特定行列的数据
df.iat[1,1] #第二行第二列的值
2、展示读取的文件(不填写展示前面五行)
df.head(20) ——展示20行
3、以数组形式返回标签
df.columns
tips:for i,v in enumerate(df.columns): 这样可以更直观看标签
返回数据框维度的元组(行数、列数)
df.shape
4、返回列的数据类型
tips:字符串在pandas中是以对象(Object)的方式存在
df.dtypes()
5、显示数据框的简明摘要,包括每列非空值的数量
df.info()
下列展示结果:
RangeIndex: 569 entries, 0 to 568 Data columns (total 32 columns): id 569 non-null int64 diagnosis 569 non-null object radius_mean 569 non-null float64 texture_mean 548 non-null float64 perimeter_mean 569 non-null float64 area_mean 569 non-null float64 smoothness_mean 521 non-null float64 compactness_mean 569 non-null float64 concavity_mean 569 non-null float64 concave_points_mean 569 non-null float64 symmetry_mean 504 non-null float64 fractal_dimension_mean 569 non-null float64 radius_SE 569 non-null float64 texture_SE 548 non-null float64 perimeter_SE 569 non-null float64 area_SE 569 non-null float64 smoothness_SE 521 non-null float64 compactness_SE 569 non-null float64 concavity_SE 569 non-null float64 concave_points_SE 569 non-null float64 symmetry_SE 504 non-null float64 fractal_dimension_SE 569 non-null float64 radius_max 569 non-null float64 texture_max 548 non-null float64 perimeter_max 569 non-null float64 area_max 569 non-null float64 smoothness_max 521 non-null float64 compactness_max 569 non-null float64 concavity_max 569 non-null float64 concave_points_max 569 non-null float64 symmetry_max 504 non-null float64 fractal_dimension_max 569 non-null float64 dtypes: float64(30), int64(1), object(1) memory usage: 142.3+ KB
6、返回每列数据的有效描述性统计(总数,均值,均差,最小——百分比位置——最大)
df.describe()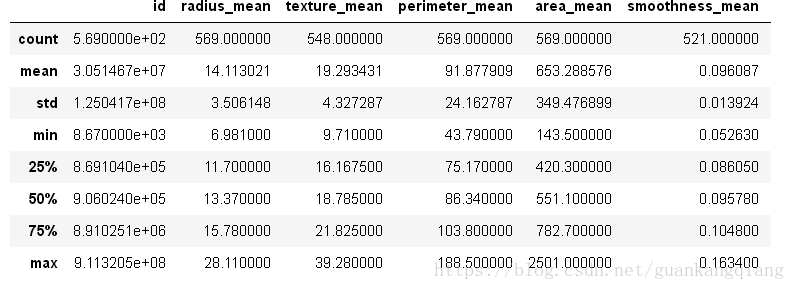
7、可以使用 loc 和 iloc 选择哪一行哪一列的数据
选择从 'id' 到最后一个均值列的所有列
df_means = df.loc[:,'id':'fractal_dimension_mean']
df_means.head()
用索引号重复以上步骤,所有行,0到10列,相当于【0:11)
df_means = df.iloc[:,:11]
df_means.head()
tips:如果想有跳转的查看
df_means = df.iloc[ [0:3,8,15] , [1,5:11] ]
8、查看哪一个位置是空,返回DataFrame,如果是NaN则是True,否则为false
df.isnull() 或者 pd.isnull(df)
求每列的空值和NaN数量
df.isnull().sum() df.isunll().sum(axis=1) 这个是求没一行的空值数量
判断哪些”列”存在缺失值
df.isnull().any()
返回二维数组,如果是NaN则是True,否则为false
df_08.isnull().values
返回所有缺失值的行的数据
df[df.isnull().any(axis=1)]
删除NaN所在的行:
删除表中全部为NaN的行
df.dropna(axis=0,how='all')
删除表中含有任何NaN的行
df.dropna(axis=0,how='any') #drop all rows that have any NaN values
删除表中全部为NaN的行
df.dropna(axis=1,how='all') or df=df.dropna(how='all')
删除表中含有任何NaN的行
df.dropna(axis=1,how='any') or df=df.drop()
9、查找数据的唯一值,返回一串唯一的数据数组
unique()
10、# 返回每列数据的有效描述性统计,先提取列,再调用describe()
df['header'].describe()
查看单列的数据,每一个唯一数据出现的次数
df['header'].value_counts()
小技巧:df['header'].value_counts().index 这样可以获取这一列的所有的唯一值,用来作为你画直方图得到时候的标签
11、查看数据行是否是重复的,冗余,返回一个队列,True表示有重复的
df.duplicated()
查看重复的行
df[df.duplicated()]
去掉重复的数据
df.drop_duplicates(inplace=True)
根据某行的一个,只判断一个标签是否是重复的
可参考:https://blog.csdn.net/weixin_37226516/article/details/72846687
12、发现有数据是空的,要根据实际情况,比如我们去他们的平均值填充进空值
mean=df['view_duration'].mean()
df[''view_duration].fillna(mean,inplace=True) inplace表示会实际修改数据并保存,默认为false
13、两个dataframe拼接
df1.appened(df2)
如果是不需要df2的index
df1.appened(df2,ignore_index=True)
14、修改列标签
old_lables = list(df.columns)
old_lables[index]='new_lable' #替换某个标签
df.columns = old_lables
df.columns = new_lables #全部重新替换
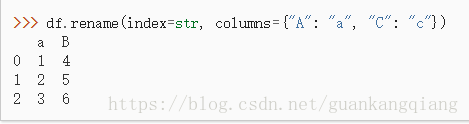
#利用自带的方法rename
df=df.rename(columns={'old_name':'new_name'})
#数据集中用下划线代替空格,并且将标签大写改为小写
df.rename(columns=lambda x: x.strip().lower().replace(" ", "_"), inplace=True) lambda函数会自动映射
提示:在使用lambda函数的时候,不用dict的形式去替代,直接替换就可以了 官方文档详情:点击打开链接


15、使用groupby方法进行分组
df.groupby(['列名1','列名2',...],as_index=False)
表示根据列名1,列名2....进行分组,as_index默认是True,如果是False,表示不用分组的列名来作为索引,索引还是0/1/2...
df.groupby(['列名1','列名2',...],as_index=False)['列名1','列名2'....]
后面添加的,表示我只想看到这几列数据
#根据A、B进行分组,对C进行求平均值
df = df.groupby(['A','B'],as_index = False)['C'].mean()也可以看看这个
https://www.cnblogs.com/zhangzhangwhu/p/7219651.html
https://blog.csdn.net/qq_24753293/article/details/78338263
16、cut函数
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3,include_lowest=False)
x——代表dataframe数据
bins : int,标量序列,或区间索引
如果bins取一个int整数,它定义了在x范围内的等宽bins的数量。然而,在这种情况下,x的范围在每一边扩展了0.1%,包含了x的最小值或最大值。如果bins是一个序列,它就定义了bins的边界即宽度,允许不均匀的bins宽度。在这种情况下没有扩展x的范围。
表明bins是否包括最右边缘。 如果right == True(默认值),则bin[1,2,3,4]表示(1,2],(2,3],(3,4]。
indicators ['ɪndə,ketɚ] n. 指示器(indicator的复数);指示灯
用作结果bins的标签。 必须与得到的bins的长度相同。 如果为False,则只返回bin的整数指示符。
retbins:boolean值,可选
是否返回bins? 如果bins是给定的一个标量,可以使用它。(自己:retbins就是return bins的缩写,即这个参数是表示是否返回bins参数的内容,true就返回,false就不返回)
precision :int,可选的
存储和显示bins标签的精度
include_lowest :bool,可选
left-inclusive interval 左闭合区间
第一个间隔是否应该是左边的。
17、清除不需要的列
df.drop(['列标签1','列标签2'...],axis=1, inplace=True)
如果axis=0,则沿着纵轴进行操作;axis=1,则沿着横轴进行操作。如果不填写,默认是全体操作
18、使用query查询,返回我们需要的数据,查询的结果其实是根据条件返回索引
# selecting malignant records in cancer data
df_m = df[df['diagnosis'] == 'M']
df_m = df.query('diagnosis == "M"')
# selecting records of people making over $50K
df_a = df[df['income'] == ' >50K']
df_a = df.query('income == " >50K"')19、从字符串中读取整数
df['B'].str.extract('(\d+)').astype(int)20、数据类型的转化
1)直接使用astype('数据类型')
df['']= df[''].astype('数据类型')
21、筛选出某列中存在你需要的数据,比如存在字符串的 '/'
hb = df[df['标签'].str.contains('/')] 该列中存在字符串/,就返回这一行


22、使用pandas自带的merge进行dataframe拼接
链接:merge
23、去掉、过滤数据集中的某些值或者某些行
1) 去掉某列存在的值的行
- df[(True-df['appPlatform'].isin([2]))]
解释:去掉'appPlatform'这一列存在值为2的行
- df[(True-df['appID'].isin([278,382]))]
解释:去掉'appID'这一列,存在值为278或者382的行
- df[(True-df['appID'].isin([278,382]))&(True-df['appPlatform'].isin([2]))]
解释:过滤掉appPlatform=2而且appID=278和appID=382的样本
2)过滤掉某个范围的值
- df[df['creativeID']<=10000]
23、情景:按年份分组后,求出不同电影类型数量的最大值
1、先对年份和电影类别进行分组,求出他们的同个年份不同电影类别的数量
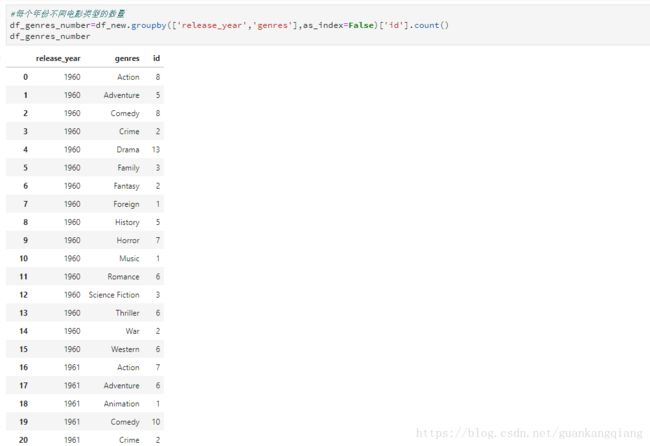
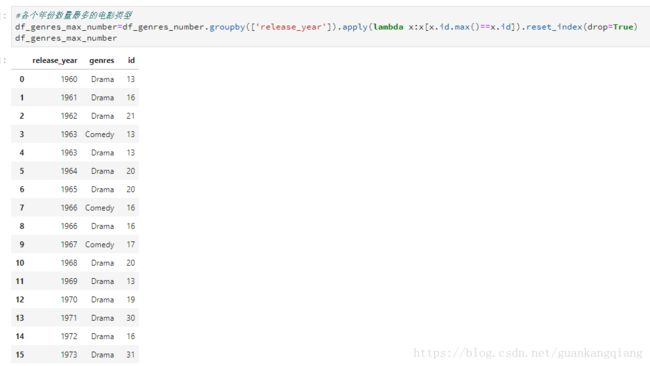
2、对数据取最大值
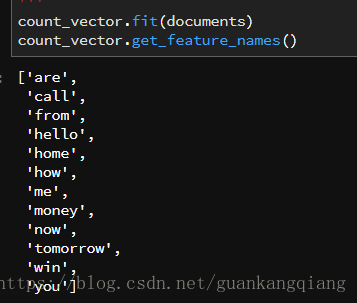
24、为了计算方便,我们需要统计某一列标签中出现的“字符串”次数
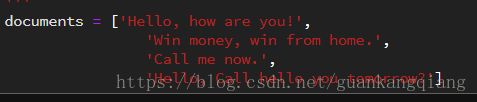
![]()
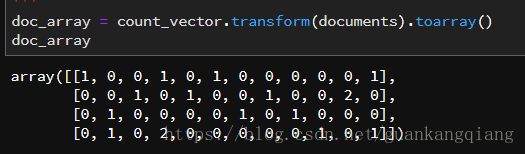
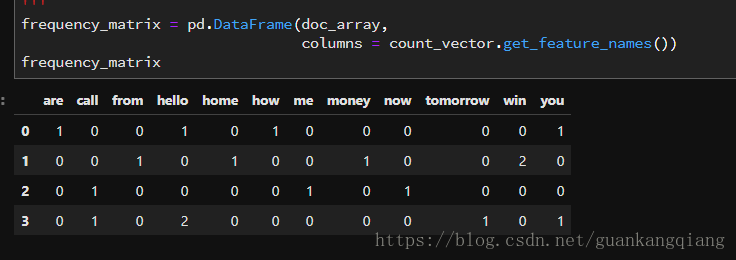
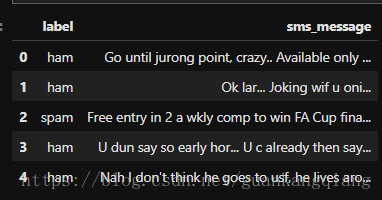
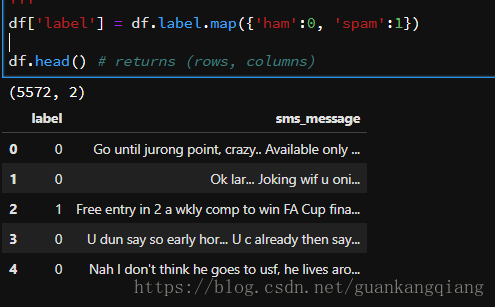
25、将label标签下的数据统一换成0/1