python初学之内置数据结构集合与字典
01 一山不容二虎的集合
1.通俗来说,集合(set)是一个无序的不重复元素序列,就是一个用来存放数据的容器。
1)集合里面的元素是不可重复的:
如:
s = {1,2,3,4,1,2,3}
print(s,type(s))
{1, 2, 3, 4} 
2)如何定义一个空集合:
s1 = {} #这种定义的是空字典
print(s1,type(s1))
{}
s2 = set([]) #定义一个空集合
print(s2,type(s2))
set()
s3 = set() #也是定义空集合
print(s3,type(s3))
set() 
2.集合的创建: 使用大括号 { } 或者 set() 函数创建集合;
- 创建一个空集合必须用 set() 而不是 { }.{ } 是用来创建一个空字典;
- 集合里面的元素必须是不可变的数据类型;(列表是可变数据类型)
s3 = {1, 3.14, True, 'hello', [1, 2, 3], (1, 2, 3)} #列表是可变数据类型 Traceback (most recent call last): File "E:\software-python\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py", line 2961, in run_code exec(code_obj, self.user_global_ns, self.user_ns) File "", line 1, in s3 = {1, 3.14, True, 'hello', [1, 2, 3], (1, 2, 3)} TypeError: unhashable type: 'list' #这样定义集合是错误的,集合里面的元素必须是不可变数据类型 
-
s3 = {1, 3.14, True, 'hello',(1, 2, 3)} #删除了可变的列表类型之后,集合定义成功 print(s3,type(s3)) {1, 3.14, 'hello', (1, 2, 3)}
- 通过set方法可以将列表/元组/字符串转换成集合数据类型。
s4 = set('abracadabra')
print(s4,type(s4))
{'r', 'c', 'b', 'd', 'a'} 
s5 = {'apple','orange','apple','pear','orange','banana'}
print(s5,type(s5))
{'orange', 'banana', 'pear', 'apple'} 
3.集合的特性:
集合是一个无序的数据类型。最后增加的元素不一定存储在集合最后。
可以从索引, 切片, 重复, 连接, 成员操作符和for循环来看其特性
集合支持的特性只有成员操作符,索引,切片,重复,连接,均不支持!
s = {1,3,5,7}
print(1 in s)
True
print(1 not in s)
False
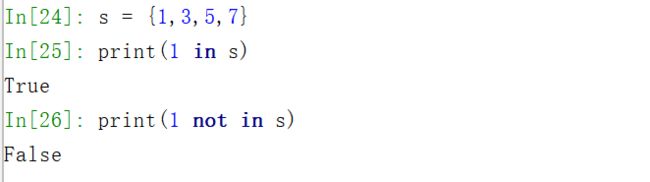
4,集合的内置方法:

1)增加:集合是可变, 无序数据类型,添加的顺序, 和在集合中存储的顺序不同
(add:增加一个,update:增加多个)
s = {2,3,4,3,5}
s.add(1) #增加一个
print(s)
{1, 2, 3, 4, 5}
s.update({7,8,9}) #增加多个
print(s)
{1, 2, 3, 4, 5, 7, 8, 9}
2)删除:
1>pop(随机弹出并返回删除的值)
s = {6,7,3,1,2,4}
print(s)
{1, 2, 3, 4, 6, 7}
s.pop()
Out[41]: 1
print(s)
{2, 3, 4, 6, 7}
2>.remove(如果元素存在, 直接删除, 如果不存在, 抛出异常KeyError)
s = {6,7,3,1,2,3}
print(s)
{1, 2, 3, 6, 7}
s.remove(6) #删除指定的元素
print(s)
{1, 2, 3, 7}
3>discard:(如果元素存在, 直接删除, 如果不存在, do nothing)只能删除单个元素。
s1 = {1,2,3,4,5}
s1.discard(3,4) #.discard一次只能删除一个元素
Traceback (most recent call last):
File "E:\software-python\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py", line 2961, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "", line 1, in
s1.discard(3,4)
TypeError: discard() takes exactly one argument (2 given)
s1 = {1,2,3,4,5}
s1.discard(3)
print(s1)
{1, 2, 4, 5} 
3)交集、并集、差集
1>并集:
s1 = {1,2,3}
s2 ={4,5,6}
print("并集:",s1.union(s2))
并集: {1, 2, 3, 4, 5, 6}
print("并集:",s1|s2)
并集: {1, 2, 3, 4, 5, 6}
2>交集:
s1 = {1,2,3}
s2 = {2,3,4}
print("交集:",s1.intersection(s2))
交集: {2, 3}
print("交集:",s1&s2)
交集: {2, 3} 
3>差集:
s1 = {1,2,3}
s2 ={3,4,5}
print("差集1--2:",s1.difference(s2))
差集1--2: {1, 2}
print("差集2--1:",s2.difference(s1))
差集2--1: {4, 5}
print("差集1--2:",s1-s2)
差集1--2: {1, 2}
print("差集2--1:",s2-s1)
差集2--1: {4, 5}
4> 对等差分:并集-交集:
s1 = {1,2,3}
s2 = {2,3,4}
print("对等差分:",s1.symmetric_difference((s2)))
对等差分: {1, 4}
print("对等差分:",s1^s2)
对等差分: {1, 4}
5>子集,负集、交集判断:
s3 = {1,2}
s4 = {1,2,3}
print(s3.issubset(s4)) #s3是s4的子集
True
print(s3.issuperset(s4)) #s3是s4的父集
False
print(s3.isdisjoint(s4)) #s3与s4不想交
False
5.集合应用案例:(列表去重)
案例1: URL地址去重:
>方法1:列表遍历,用.append()追加
代码 如下:
urls = [
'http://www.baidu.com',
'http://www.qq.com',
'http://www.qq.com',
'http://www.163.com',
'http://www.csdn.com',
'http://www.csdn.com',
]
# 用来存储去重的url地址
analyze_urls = []
# 依次遍历所有的url
for url in urls:
# 如果url不是analyze_urls列表成员, 则追加到列表最后。
# 如果url是analyze_urls列表成员,不做任何操作。
if url not in analyze_urls:
analyze_urls.append(url)
print("去重之后的url地址: ", analyze_urls)测试结果:

>方法2:集合的性质去重:
代码如下:(此处的urls定义为集合urls{}同样可以完成,效果一致)
urls = [
'http://www.baidu.com',
'http://www.qq.com',
'http://www.qq.com',
'http://www.163.com',
'http://www.csdn.com',
'http://www.csdn.com',
]
print("去重之后的url地址: ",set(urls)) #设置输出的格式为集合类型测试结果:

案例2: 判断列表去重前后元素长度是否一致:即是否存在重复元素的判断
如下:
nums = [1,2,3,4,2,3] #如果此处nums是用集合{}定义的,结果永远都是false
# 存在重复元素: 判断nums的长度和去重之后的长度是否一致,
# 如果不一致, 则有重复的元素, 返回True
# 如果一致, 则没有重复的元素, 返回False
print(len(nums) != len(set(nums)))测试:

nums = [1, 2, 3, 4]
# 存在重复元素: 判断nums的长度和去重之后的长度是否一致,
# 如果不一致, 则有重复的元素, 返回True
# 如果一致, 则没有重复的元素, 返回False
print(len(nums) != len(set(nums)))
案例3:华为笔试编程题: 明明的随机数(去重与排序)
题目:明明想在学校中请一些同学一起做一项问卷调查,为了实验的客观性,他先用计算机生成了N个1到1000之间的 随机整数(N≤1000),对于其中重复的数字,只保留一个,把其余相同的数去掉,不同的数对应着不同的学 生的学号。然后再把这些数从大到小排序,按照排好的顺序去找同学做调查。请你协助明明完成“去重”与 “排序”的工作(同一个测试用例里可能会有多组数据,希望大家能正确处理)。
思路:
- 1). 生成了N个1到1000之间的随机整数(N≤1000)
- 2). 去重: 其中重复的数字,只保留一个,把其余相同的数去掉
- 3). 从大到小排序
代码如下:
-
import random # 2). 去重: 其中重复的数字,只保留一个,把其余相同的数去掉.生成一个空集合 nums = set() N = int(input('N: ')) # 1). 生成了N个1到1000之间的随机整数(N≤1000) for count in range(N): num = random.randint(1, 1000) nums.add(num) # 3). 从大到小排序, li.sort()智能对列表进行排序; sorted()方法可以对任意数据类型排序。 print(sorted(nums, reverse=True))测试结果:
-

案例4:两个数组的交集:
示例 1:
输入: nums1 = [1,2,2,1], nums2 = [2,2]
输出: [2]
示例 2:
输入: nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出: [9,4]
说明:输出结果中的每个元素一定是唯一的。
我们可以不考虑输出结果的顺序。
代码如下:
class Solution:
def intersection(self, nums1, nums2):
a = set(nums1)
b = set(nums2)
c = a & b
return list(c)测试结果:

02 frozenset
- frozenset 是 set 的不可变版本,因此 set 集合中所有能改变集合本身的方法(如 add、 remove、discard、xxx_update 等),frozenset都不支持;
- set 集合中不改变集合本身的方法,fronzenset 都支持。
- frozenset 的这些方法和 set 集合同名方法的功能完全相同。
- 当集合元素不需要改变时,使用 frozenset 代替 set 更安全。
- 当某些 API 需要不可变对象时,必须用 frozenset 代替set。比如 dict 的 key 必须 是不可变对象,因此只能用 frozenset;
- 再比如 set 本身的集合元素必须是不可变 的,因此 set 不能包含 set,set 只能包含 frozenset。
如:
set1 = frozenset({1,2,3,4})
print(set1,type(set1))
frozenset({1, 2, 3, 4})
set2 = {1,2,set1}
print(set2)
{1, 2, frozenset({1, 2, 3, 4})} 
03 字典
1.字典的创建于删除





students = {
'user1': [100, 100, 100],
'user2': [98, 100, 100],
'user3': [100, 89, 100],
}
# 字典的查看
# 通过字典的key获取对应的value值;
print(students['user1'])
# print(students['user4']) # KeyError: 'user4', 因为key值在字典中不存在
# 特别重要: get方法: 如果key存在获取对应的value值, 反之, 返回默认值(如果不指定,默认返回的是None)
print(students.get('user1')) # [100, 100, 100]
print(students.get('user4', 'no user')) # 'no user'
# 查看所有的key值/value值/key-value值
print(students.keys())
print(students.values())
print(students.items()) # key-value值 [(key1, value1),(key2, value2)]
运行结果:
[100, 100, 100]
[100, 100, 100]
no user
dict_keys(['user1', 'user2', 'user3'])
dict_values([[100, 100, 100], [98, 100, 100], [100, 89, 100]])
dict_items([('user1', [100, 100, 100]), ('user2', [98, 100, 100]), ('user3', [100, 89, 100])])2>.循环遍历字典:
# for循环字符串
# for item in 'abc':
# print(item)
# for循环元组
# for item in (1, 2, 3):
# print(item)
# # for循环集合
# for item in {1, 2, 3}:
# print(item)
students = {
'user1': [100, 100, 100],
'user2': [98, 100, 100],
'user3': [100, 89, 100],
}
# 字典遍历时默认遍历的时字典的key值
for key in students:
print(key, students[key])
# 遍历字典key-value建议的方法
for key,value in students.items(): # [('user1', [100, 100, 100]), ('user2', [98, 100, 100]), ('user3', [100, 89, 100])]
# key,value = ('user1', [100, 100, 100])
# key,value = ('user2', [98, 100, 100])
# key,value = ('user3', [100, 89, 100])
print(key, value)
运行结果:
user1 [100, 100, 100]
user2 [98, 100, 100]
user3 [100, 89, 100]
user1 [100, 100, 100]
user2 [98, 100, 100]
user3 [100, 89, 100]
- 如果key存在, 修改key-value
- 如果key不存在, 增加key-value
import pprint
students = {
'user1': [100, 100, 100],
'user2': [98, 100, 100],
'user3': [100, 89, 100],
}
students['user4'] = [90, 99, 89]
print(students)
结果:
{'user1': [100, 100, 100], 'user2': [98, 100, 100], 'user3': [100, 89, 100], 'user4': [90, 99, 89]}如果key存在, 不做任何操作
如果key不存在, 增加key-valueimport pprint
students = {
'user1': [100, 100, 100],
'user2': [98, 100, 100],
'user3': [100, 89, 100],
}
students.setdefault('user1', [100, 89, 88])
print(students)
结果为:
{'user1': [100, 100, 100], 'user2': [98, 100, 100], 'user3': [100, 89, 100], 'user4': [90, 99, 89]}3). update方法: 批量添加key-value
如果key存在, 修改key-value
如果key不存在, 增加key-valueimport pprint
students = {
'user1': [100, 100, 100],
'user2': [98, 100, 100],
'user3': [100, 89, 100],
}
new_student = {
'westos':[100, 100, 100],
'root':[100, 100, 100],
'user1':[0, 0, 0]
}
students.update(new_student)
pprint.pprint(students)
结果为:
{'root': [100, 100, 100],
'user1': [0, 0, 0],
'user2': [98, 100, 100],
'user3': [100, 89, 100],
'westos': [100, 100, 100]}4>字典的删除
1). del dict[key]
# 如果key存在, 删除对应的value值
# 如果key不存在, 抛出异常KeyError
students = {
'user1': [100, 100, 100],
'user2': [98, 100, 100],
'user3': [100, 89, 100],
}
del students['user1']
print(students)
结果:
{'user2': [98, 100, 100], 'user3': [100, 89, 100]}2). pop方法
#如果key存在, 删除对应的value值
#如果key不存在,如果没有提供默认值, 则抛出异常KeyErrorstudents = {
'user1': [100, 100, 100],
'user2': [98, 100, 100],
'user3': [100, 89, 100],
}
delete_item = students.pop('user6', 'no user')
print("删除的元素是: ", delete_item)
print(students)
结果是:
删除的元素是: no user
{'user1': [100, 100, 100], 'user2': [98, 100, 100], 'user3': [100, 89, 100]}3). popitem方法: 随机删除字典的key-value值students = {
'user1': [100, 100, 100],
'user2': [98, 100, 100],
'user3': [100, 89, 100],
}
key, value = students.popitem()
print("随机删除的内容: ", key, value)
结果:
随机删除的内容: user3 [100, 89, 100]3.英文文本预处理:英文词频统计器
from collections import Counter
text = """
Introducing Red Hat Enterprise Linux 7
Red Hat Enterprise Linux 7 showcases the latest features in an enterprise operating system
Introducing Red Hat Enterprise Linux 7
Red Hat Enterprise Linux 7 showcases the latest features in an enterprise operating system
Introducing Red Hat Enterprise Linux 7
Red Hat Enterprise Linux 7 showcases the latest features in an enterprise operating system
Introducing Red Hat Enterprise Linux 7
Red Hat Enterprise Linux 7 showcases the latest features in an enterprise operating system
Enterprise architects will appreciate new capabilities such as lightweight application isolation.
Application developers will welcome an updated development environment and application-profiling tools. Read more at the Red Hat Developer Blog.
System administrators will appreciate new management tools and expanded file-system options with improved performance and scalability.
Deployed on physical hardware, virtual machines, or in the cloud, Red Hat Enterprise Linux 7 delivers the advanced features required for next-generation architectures.
Where to go from here:
Red Hat Enterprise Linux 7 Product Page
The landing page for Red Hat Enterprise Linux 7 information. Learn how to plan, deploy, maintain, and troubleshoot your Red Hat Enterprise Linux 7 system.
Red Hat Customer Portal
Your central access point to finding articles, videos, and other Red Hat content, as well as manage your Red Hat support cases.
Documentation
Provides documentation related to Red Hat Enterprise Linux and other Red Hat offerings.
Red Hat Subscription Management
Web-based administration interface to efficiently manage systems.
Red Hat Enterprise Linux Product Page
Provides an entry point to Red Hat Enterprise Linux product offerings.
"""
# 1. 先拿出字符串里面的所有单词;
words = text.split() # ['hello', 'world', 'hello', 'python', 'hello', 'java']
"""
text = "hello world hello python hello java"
words = ['hello', 'world', 'hello', 'python', 'hello', 'java']
word_count_dict = {
'hello': 3,
'world': 1,
'python':1,
'java':1
}
"""
# 2. 统计每个单词出现的次数
# 1). 如何存储统计好的信息: 字典存储{'hello':3, 'world':1, 'python':1, 'java':1}
# 2). 如何处理?
word_count_dict = {}
for word in words:
if word not in word_count_dict:
word_count_dict[word] = 1
else:
word_count_dict[word] += 1
print(word_count_dict)
# 3. 排序,获取出现次数最多的单词
counter = Counter(word_count_dict)
print(counter.most_common(5))结果:
{'Introducing': 4, 'Red': 21, 'Hat': 21, 'Enterprise': 16, 'Linux': 15, '7': 12, 'showcases': 4, 'the': 7, 'latest': 4, 'features': 5, 'in': 5, 'an': 6, 'enterprise': 4, 'operating': 4, 'system': 4, 'architects': 1, 'will': 3, 'appreciate': 2, 'new': 2, 'capabilities': 1, 'such': 1, 'as': 3, 'lightweight': 1, 'application': 1, 'isolation.': 1, 'Application': 1, 'developers': 1, 'welcome': 1, 'updated': 1, 'development': 1, 'environment': 1, 'and': 6, 'application-profiling': 1, 'tools.': 1, 'Read': 1, 'more': 1, 'at': 1, 'Developer': 1, 'Blog.': 1, 'System': 1, 'administrators': 1, 'management': 1, 'tools': 1, 'expanded': 1, 'file-system': 1, 'options': 1, 'with': 1, 'improved': 1, 'performance': 1, 'scalability.': 1, 'Deployed': 1, 'on': 1, 'physical': 1, 'hardware,': 1, 'virtual': 1, 'machines,': 1, 'or': 1, 'cloud,': 1, 'delivers': 1, 'advanced': 1, 'required': 1, 'for': 2, 'next-generation': 1, 'architectures.': 1, 'Where': 1, 'to': 6, 'go': 1, 'from': 1, 'here:': 1, 'Product': 2, 'Page': 2, 'The': 1, 'landing': 1, 'page': 1, 'information.': 1, 'Learn': 1, 'how': 1, 'plan,': 1, 'deploy,': 1, 'maintain,': 1, 'troubleshoot': 1, 'your': 2, 'system.': 1, 'Customer': 1, 'Portal': 1, 'Your': 1, 'central': 1, 'access': 1, 'point': 2, 'finding': 1, 'articles,': 1, 'videos,': 1, 'other': 2, 'content,': 1, 'well': 1, 'manage': 2, 'support': 1, 'cases.': 1, 'Documentation': 1, 'Provides': 2, 'documentation': 1, 'related': 1, 'offerings.': 2, 'Subscription': 1, 'Management': 1, 'Web-based': 1, 'administration': 1, 'interface': 1, 'efficiently': 1, 'systems.': 1, 'entry': 1, 'product': 1}
[('Red', 21), ('Hat', 21), ('Enterprise', 16), ('Linux', 15), ('7', 12)]
Process finished with exit code 04.前 K 个高频元素:

from collections import Counter
nums = [1, 1, 1, 2, 2, 3, 3, 3, 3]
k = 2
counter = Counter(nums)
result = counter.most_common(k)
top_k = []
for item, count in result:
top_k.append(item)
print(top_k)
结果:
[3, 1]
Process finished with exit code 05.列表去重方法三
li = [1,2,3,4,65,1,2,3]
print({}.fromkeys(li).keys())
结果为:
dict_keys([1, 2, 3, 4, 65])
6.switch语句实现

grade = input('Grade: ')
if grade =='A':
print("优秀")
elif grade == 'B':
print("良好")
elif grade == 'C':
print("合格")
else:
print('无效的成绩')
运行结果:
Grade: D
无效的成绩
Grade: A
优秀
2)新方法(更加的简化)
grade = input('Grade: ')
grades_dict = {
'A': '优秀',
'B': '良好',
'C': '及格',
'D': '不及格',
}
print(grades_dict.get(grade, "无效的等级"))
# if grade in grades_dict:
# print(grades_dict[grade])
# else:
# print("无效的等级")
运行结果:
Grade: B
良好
Grade: C
及格
04 defaultdict(默认字典)
1.当我使用普通的字典时,用法一般是dict={},添加元素的只需要dict[element] =value即,调用的时候也是如此,dict[element] = xxx,但前提是element在字典里,如果不在字典里就会报错,如:

2.这时defaultdict就能排上用场了,defaultdict的作用是在于,当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值。
- collections.defaultdict类,本身提供了默认值的功能, 默认值可以是整形,列表,集合等.
- defaultdict 是 dict 的子类。但它与 dict 最大的区别在于,如果程序试图根据不存在的 key 访问 value,会引发 KeyError 异常;
- 而 defaultdict 提供default_factory 属性,为该不存在的 key 来自动生成生成默认的 value。
from collections import defaultdict
info = defaultdict(int)
info['a'] += 1
print(info['a'])
运行结果:
1
from collections import defaultdict
info = defaultdict(list)
info['a'].append(1)
print(info['a'])
结果为:
[1]
from collections import defaultdict
info = defaultdict(set)
info['a'].add(1)
print(info['a'])
结果为:
{1}
3. 案例练习:
from collections import defaultdict
# 1). 随机生成50个1-100之间的随机数
import random
nums = []
for count in range(50):
nums.append(random.randint(1, 100))
# 2). 把list中大于66的元素和小于66的元素分类存储
sort_nums_dict = defaultdict(list) # 创建一个默认字典, 默认的value为空列表[]
for num in nums:
if num > 66:
sort_nums_dict['大于66的元素'].append(num)
else:
sort_nums_dict['小于66的元素'].append(num)
print(sort_nums_dict)
运行结果为:
defaultdict(, {'小于66的元素': [64, 39, 13, 1, 21, 9, 33, 27, 54, 8, 19, 36, 7, 7, 32, 54, 4, 20, 27, 17, 41, 6, 35, 60, 2, 21, 51, 23, 17, 49, 29, 7, 53, 56], '大于66的元素': [89, 70, 81, 91, 78, 98, 82, 87, 90, 100, 85, 71, 95, 80, 93, 82]}) 05 内置数据结构总结
1.可变与不可变数据类型
- 可变数据类型允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象;
- 变量引用的对象的地址也不会变化,不过对 于相同的值的不同对象,在内存中则会存在不同的对象;
- 即每个对象都有自己的地址,相当于内存中对 于同值的对象保存了多份;
- 这里不存在引用计数,是实实在在的对象。
不可变数据类型:不可以增删改。
- python中的不可变数据类型,不允许变量的值发生变化;
- 如果改变了变量的值, 相当于是新建了一个对象;
- 而对于相同的值的对象,在内存中则只有一个对象,内部会有一个引用计数来记录有多少个变量引用这个对象。
2. 有序序列和无序序列
有序序列拥有的特性: 索引、切片、连接操作符、重复操作符以及成员操作符等特性。
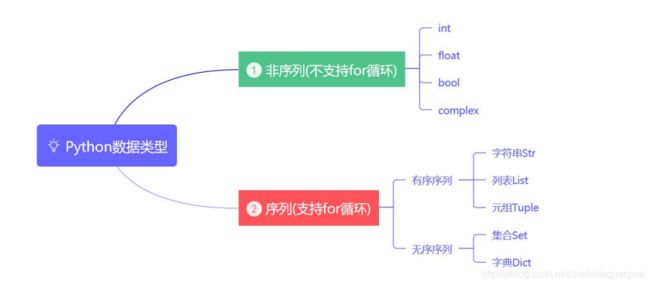
所以:列表、字符串、元组是python的有序序列;
集合、字典是python的无序序列。
小练习1:
a=input("请输入一个列表:")
alist=a.split(",")
a1 = [int(alist[i]) for i in range(len(alist))]
a2=a1.pop(0)
a1.append(a2)
print(a1)
结果:
请输入一个列表:1,2,3,4,5,6,7,8,9,0
[2, 3, 4, 5, 6, 7, 8, 9, 0, 1]06 MD5在线加密解密工具
- https://www.cmd5.com/, 本项目针对md5、sha1等全球通用公开的加密算法进行反向查询,
- 通过穷举字符组合的方式,创建了明文密文对应查询数据库,创建的记录约90万亿条,占用硬盘超过500TB,查询成功率95%以上,
- 很多复杂密文只有本站才可查询。已稳定运行十余年,国内外享有盛誉。
1.MD5简介
- MD5消息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,
- 可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传 输完整一致。
- MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,
- 通常用一个32位的16进制字符串表示。
import hashlib
password = b'python123'
md5_password = hashlib.md5(password).hexdigest()
md5_password
Out[7]: 'affaf271b3ebb2db157a04874259cdcb'

3.MD5解密
- MD5目前人类是无法解密的,目前人类的MD5解密方法是建立一个大型数据库,
- 将各 个人的MD5数据存储在这个数据库里面,然后将所需要解密的密码放入该库对比找到同样原码,
- 如果没有对比到数据,说明该密没有被记录过,也就是说没有办法解密了。
1)MD5在线加密解密工具

(1)批量加密程序
实例1:
from string import digits
# Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。hashlib库进行md5加密,操作如下
import hashlib
# 显示程序运行的进度条
from tqdm import tqdm
import json
db = {}
for item1 in tqdm(digits):
for item2 in digits:
for item3 in digits:
for item4 in digits:
for item5 in digits:
for item6 in digits:
passwd1 = item1 + item2 + item3 + item4 + item5 + item6
# md5加密需要的字符串时bytes类型, 将utf-8的编码格式编码成bytes类型
passwd = passwd1.encode('utf-8')
md5_passwd = hashlib.md5(passwd).hexdigest()
db[md5_passwd] = passwd1
# 将db字典的信息以json的格式存储到md5.json文件中
json.dump(db, open('md5.json', 'w'))
print("生成数据库成功.......")
运行结果为:
100%|██████████| 10/10 [00:01<00:00, 6.39it/s]
生成数据库成功.......
运行结果图:

实例2:
import hashlib;import json
filename = 'md5.json'
db = json.load(open(filename))
choice = input("请选择你的操作(0-加密 1-解密):")
if choice == '0':
password = input("请输入需要加密的字符串:").encode(encoding='utf-8')
md5_password = hashlib.md5(password).hexdigest()
print("%s加密后密码为: %s" %(password,md5_password))
elif choice == '1':
md5_password = input("请输入要解密的字符串:")
password = db.get(md5_password)
if password:
print("%s 解密后的明文字符串为: %s" %(md5_password,password))
else:
print("%s 当前不能解密" %(md5_password))
else:
print("请输入正确的选择")
运行结果:
请选择你的操作(0-加密 1-解密):0
请输入需要加密的字符串:python is beautiful and simple
b'python is beautiful and simple'加密后密码为: ee665372659e7fc615e0f78ec2c5c66a
运行结果图:
