map和set
map和set是两个主要的关联容器。关联容器究竟是什么?它和顺序容器有什么区别?
关联容器中的元素是按照关键字来保存和访问的;顺序容器中的元素是按照它们在容器中的位置来顺序保存和访问的。
map和set的底层都是通过红黑树来实现的,即中序遍历得到的序列是关键字的升序排列。然而关联容器还会由map和set衍生出一些类型。
multimap:关键字可以重复的map;
multiset:关键字可以重复的set;
unordered_map:用哈希函数组织的map(无序)
unordered_set:用哈希函数组织的set;
unordered_multimap:关键字可以重复,用哈希组织的map;
unordered_multiset:关键字可以重复,用哈希组织的set。
set
容器中只含有关键字,并且关键字不可以重复。通过下边的代码,我们来具体看一下set怎么使用,以及set中一些函数的作用,参数以及返回值。
void PrintSet(set<int>& s)
{
//set::const_iterator iteSet = s.begin();
set<int>::iterator iteSet = s.begin();
while(iteSet != s.end())
{
//*iteSet = 50;
cout<<*iteSet<<" ";
++iteSet;
}
cout<void PrintMulSet(multiset<int>& m)
{
multiset<int>::iterator iteMulSet = m.begin();
while(iteMulSet != m.end())
{
cout<<*iteMulSet<<" ";
++iteMulSet;
}
cout<void TestSet()
{
set<int> setName;
setName.insert(10);
setName.insert(5);
setName.insert(12);
setName.insert(20);
setName.insert(10);
PrintSet(setName);
cout<10)<//如果给定的值存在,返回1;如果不存在,返回0
setName.erase(12);
if(setName.find(12) == setName.end())
{
cout<<"12不存在"< 程序的输出结果是:

set是不像顺序容器那样可以支持下标操作,set不支持下标操作.
关于find函数,如果要找到的关键字存在,返回指向该关键字的迭代器;如果不存在,返回容器中最后一个元素的下一个位置。
set的关键字是const类型的,所以,关键字是不可以改变的,但是在vs2008下可以改变,vs2013以及以上版本不可以改变。
上边我们说过,按照顺序打印的结果都是按照关键字升序排列的,可是如何使得打印出的结果是降序的,我们有几种方法:仿函数;反向迭代器。下边我们给出反向迭代器的代码:
void ReversePrintSet(set<int> s)
{
set<int>::reverse_iterator reIte = s.rbegin();
while(reIte != s.rend())
{
cout<<*reIte<<" ";
++reIte;
}
cout<multiset
其实multiset是和set很像的,只是set中不允许重复的关键字。下边代码:
void PrintMulSet(multiset<int>& m)
{
multiset<int>::iterator iteMulSet = m.begin();
while(iteMulSet != m.end())
{
cout<<*iteMulSet<<" ";
++iteMulSet;
}
cout<void TestMultiset()
{
multiset<int> multSet;
multSet.insert(10);
multSet.insert(5);
multSet.insert(12);
multSet.insert(10);
multSet.insert(18);
multSet.insert(12);
multSet.insert(12);
PrintMulSet(multSet);
multSet.insert(30);
multSet.insert(30);
multSet.insert(30);
PrintMulSet(multSet);
//如果进行查找30,会找到哪一个,验证
multiset<int>::iterator ret = multSet.find(30);
multSet.erase(ret);
PrintMulSet(multSet);//会打印出2个30,说明查找到的30是左下角的30
cout<12)<//count计算的是给定值在multset中出现的次数
}
代码运行结果:
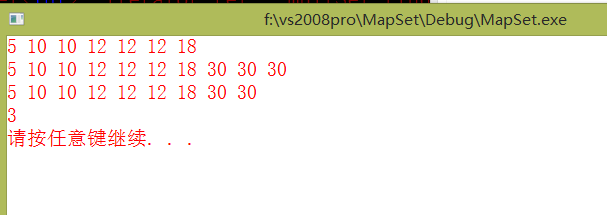
在multiset在find一个关键字,返回的是指向中序遍历遇到的第一个关键字的结点(代码中已经予以验证);在multiset中插入一个已经存在的关键字,插在相同关键字的左或者右,都是无所谓的,因为有红黑树旋转的支撑。
map
map中存储的就不仅仅是关键字,还会存在关键字所对应的值。也就是之前说过的key-value类型。所以map中的每一个元素都是pair类型,pair是一个结构体,里边有两个成员,K类型的first,V类型的second。创建pair类型的对象有以下几种方法:
pair<string,int>("小杨同学",21);
make_pair("小杨同学",21);
pair<string,int> p = {"小杨同学",21};下边我们通过map的一些函数的使用代码来学习一下如何使用map:
void TestMap()
{
map<string,int> mapName;
//insert
mapName.insert(pair<string,int>("小杨",1));
mapName.insert(pair<string,int>("小吴",3));
mapName.insert(pair<string,int>("小白",2));
mapName.insert(pair<string,int>("小赵",2));
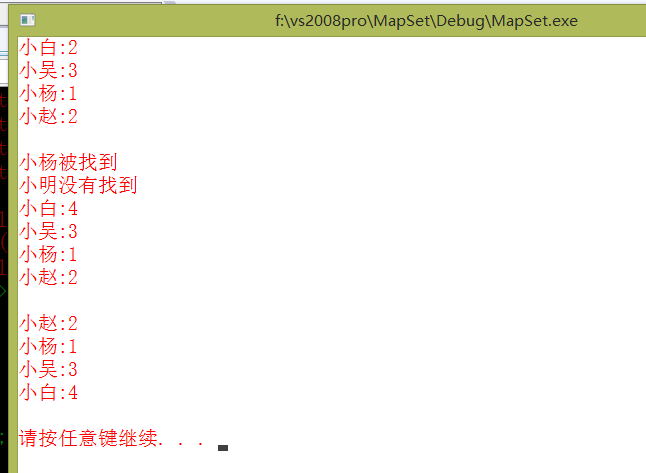
PrintMap(mapName);
//find
map<string,int> ::iterator ite1;
ite1 = mapName.find(string("小杨"));
if(ite1 != mapName.end())
cout<<"小杨被找到"<string("小明"));
if(ite1 == mapName.end())
cout<<"小明没有找到"<//修改某个key的value
map<string,int> ::iterator ite2;
ite2 = mapName.find(string("小白"));
if(ite2 != mapName.end())
{
ite2->second = 4;//将小白改成4号
}
PrintMap(mapName);
ReversePrintMap(mapName);
} void PrintMap(const map<string,int>& m)
{
map<string,int>::const_iterator iteMap = m.begin();
while(iteMap != m.end())
{
cout<<(*iteMap).first<<":"<<(*iteMap).second<cout<//使用反向迭代器使打印结果变成降序
void ReversePrintMap(map<string,int> m)
{
map<string,int>::reverse_iterator reIte = m.rbegin();
while(reIte != m.rend())
{
cout<first<<":"<second<cout< 程序运行结果是:
map经常被用在很多方面,比如,统计一篇文章中单词出现的次数,统计班级同学喜欢吃的水果以及喜欢该水果的人数等等。下边给出代码:
//统计班级学生喜欢吃的水果
void CountFavoriteFruits_1(vector<string> v)
{
map<string ,int> countMap;
for(size_t i = 0; i < v.size(); ++i)
{
map<string,int>::iterator ret = countMap.find(v[i]);//先查找v[i]是否已经存在
if(ret != countMap.end())//已经存在
{
ret->second++;
}
else//没有存在,进行插入
{
countMap.insert(pair<string,int>(v[i],1));
}
}
}这种方法是可以统计出结果的,但是整个过程会遍历map两次(find遍历一次,insert遍历一次)。先查找,如果原来已经存在,那么给对应的second加1即可,如果不存在,将其插入。
void CountFavoriteFruits_2(vector<string> v)
{
map<string,int> countMap;
for(size_t i = 0; i< v.size(); ++i)
{
//insert的实现原理:如果存在,则返回要插入元素所在的位置,以及false;如果不存在,则进行插入
pair<map<string,int>::iterator,bool> ret = countMap.insert(pair<string,int>(v[i],1));
if(ret.second == false)//表明没有插入成功
{
ret.first->second ++;
}
}
}这种方法中 ,我们巧用insert的返回值,如果不存在,插入,返回指向插入位置的迭代器以及true;如果存在,返回指向已经存在位置的迭代器 和flase,然后将其second加1即可。
void CountFavoriteFruits_3(vector<string> v)
{
map<string,int> countMap;
for(size_t i = 0; i < v.size(); ++i)
{
//operator[],没有则进行插入,有则返回value的引用
countMap[v[i]]++;
}
SelectTop3(countMap);
}我们知道operator[]执行两个操作:1是读(读取关键字),2是写(修改second的值)。operator[]的参数是给定的关键字key,返回的是key对应 的pair的second的类型的引用。
at操作:访问所给关键字的元素,带参数检查,如果所给关键字不在map中,则会抛出异常~
通过以上3种方法,我们求出了各种水果出现过的次数,那么如果要求求出出现次数最多的几种水果,我们可以采取以下的方法:
bool SortByM1( const pair<string,int> &v1, const pair<string,int> &v2)
{
return v1.second > v2.second;//降序排列
}
void SelectTop3(map<string , int>& m)
{
map<string,int>::iterator ite = m.begin();
vectorstring ,int>>v;
while(ite != m.end())
{
//v.push_back(pair((*ite).first,(*ite).second));
v.push_back(*ite);
++ite;
}
std::sort(v.begin(),v.end(),SortByM1);
}这种方法是在vector种放入的是pair类型,一定要注意sort的参数。我们不能直接对map进行调用sort,因为 查库就知道了~~~
pair是一个结构体,push操作效率不高,我们可以在vector中放指向map的迭代器~代码如下:
void SelectTop3(map<string , int>& m)
{
map<string,int>::iterator ite = m.begin();
vector<map<string,int>::iterator> v;
while(ite != m.end())
{
v.push_back(ite);
++ite;
}
struct Compare
{
bool operator()(map<string,int>::iterator l,map<string,int>::iterator r)
{
return l->second > r->second;
}
};
std::sort(v.begin(),v.end(),Compare());
}迭代器就类似于指针,赋值操作时比较快的,所以,下边的一种方法是优于上边的方法。
其实map和vector,list一样都有clear函数,只是vector的clear不会清理空间,而map的clear会清理空间。
multimap
关键字可以重复的map,下边用代码来进行学习:
void PrintMultimap(multimap<string,int>& mulMapName)
{
multimap<string,int>::iterator IteMultimap = mulMapName.begin();
while(IteMultimap != mulMapName.end())
{
//IteMultimap->first = "new key";//错误,不可以编译通过,
//因为map(multimap)中的关键字是const的,second可以改变
IteMultimap->second = 10;
cout<first<<":"<second<cout<void TestMultimap()
{
multimap<string,int> mulMapName;
mulMapName.insert(pair<string,int>("小红",12));
mulMapName.insert(pair<string,int>("小明",13));
mulMapName.insert(pair<string,int>("Lily",12));
mulMapName.insert(pair<string,int>("小杨",14));
mulMapName.insert(pair<string,int>("小白",11));
mulMapName.insert(pair<string,int>("小红",12));
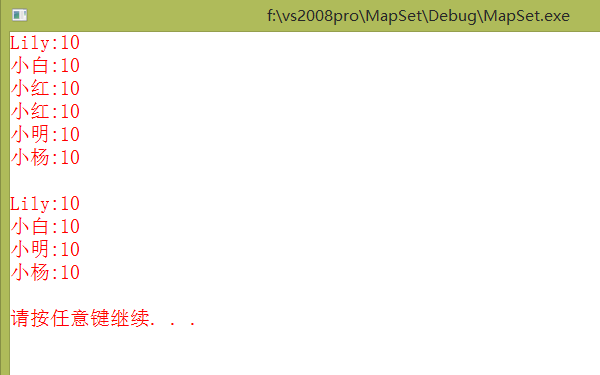
PrintMultimap(mulMapName);
mulMapName.erase("小红");
PrintMultimap(mulMapName);
} 有些未测试的操作比如find,都是类似于map的 。上边代码的运行结果如下:
multimap中的insert操作:始终可以插入成功,除非计算机的内存不足。
但是multimap有不同于map的地方:multimap没有operator[]操作,原因;因为multimap中的关键字是可以重复的,所以最终的结果是不确定的。
在本文开头给出了几种关联容器,下边的四种操作时c++11中的标准,所以,我们换到vs2015的IDE下进行测试:
unordered_set
void PrintunOrderSet(unordered_set<int>& unOrderSet)
{
unordered_set<int>::iterator itUnOrderSet = unOrderSet.begin();
while (itUnOrderSet != unOrderSet.end())
{
cout << *itUnOrderSet << " ";
++itUnOrderSet;
}
cout << endl;
}
void TestUnorderSet()
{
cout << endl << endl;
unordered_set<int> unOrderSet;
unOrderSet.insert(12);
unOrderSet.insert(10);
unOrderSet.insert(24);
unOrderSet.insert(85);
unOrderSet.insert(40);
PrintunOrderSet(unOrderSet);
unOrderSet.erase(10);
PrintunOrderSet(unOrderSet);
}程序运行结果:

根据运行结果和测试代码:我们可以看出,打印出的结果既不是插入顺序,也不是升序。究竟是什么顺序呢?我们知道unordered_set的底层是哈希表,其实是按照每个值在哈希表中的顺序逐个打印出来的。
unordered_map
是无序的map,底层是通过哈希表实现的。下边通过代码来熟悉其中的一些函数:
void PrintUnorderMap(unordered_map<string, int>& m)
{
unordered_map<string, int>::iterator itUnMap = m.begin();
while (itUnMap != m.end())
{
cout << itUnMap->first << ":" << itUnMap->second << endl;
++itUnMap;
}
cout << endl;
}
void TestUnorderMap()
{
cout << endl << endl;
unordered_map<string,int> unOrderMap;
unOrderMap.insert({ "小红", 12});
unOrderMap.insert({ "小白",16 });
unOrderMap.insert({ "小李",13 });
unOrderMap.insert({ "小红",12 });
unOrderMap.insert({ "小明",15 });
PrintUnorderMap(unOrderMap);
unOrderMap["小明"] = 19;
PrintUnorderMap(unOrderMap);
unOrderMap["小红"] = 19;
PrintUnorderMap(unOrderMap);
unOrderMap.erase("小明");
PrintUnorderMap(unOrderMap);
}程序的运行结果如下:

同样,打印出的结果是按照在哈希表中的顺序打的~
关于后边的两个容器,这里就不会给出代码~
我们知道,unordered类型的容器的底层是哈希表,哈希表的优缺点前边已经说过:查找和插入很快,但是如果数据量比较大,就会产生哈希冲突,在这几个容器的底层处理哈希冲突的方法是拉链法(前边文章有叙述)。如果,如果可以选择set和unordered_set,我们优先选择unordered_set,因为效率 问题,如果冲突比较多的情况(超过一半的元素都会出现在一个链上,查找效率就是比较低的),我们可以利用红黑树来替代链表,提高查找效率 ~
如果我们打开map和set的底层实现,我们会发现,前边四个容器底层是共用一个红黑树,如果是mul系列的,insert时调用insert_equal版本,如果不是mul系列,则调insert_unique版本。set是关键字类型和值类型一样的map,所以,可以map和set可以复用代码。
底层实现文件中的 几个类型及含义:
key_type:此容器的关键字类型
mapped_type:map系列容器的值类型
value_type:对于set类容器,指代的是关键字类型;
对于map类容器,指代的是pair类型。
关于map和set,就整理到这里~