dpdk学习之cache line设计
此文章主要是整理的网上的资料,转载
http://www.cnblogs.com/cyfonly/p/5800758.html
http://ifeve.com/falsesharing/
最近公司框架需要优化,接触到了false sharing。
一、基础概念介绍
1.1 伪共享
缓存系统中是以缓存行(cache line)为单位存储的,当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
1.2 cpu缓存
Cpu缓存解决什么问题?
解决cpu运算速度和内存读写速度不匹配的问题。
Cpu运算->一级缓存 ->二级缓存-> 三级缓存 ->内存
1.3 MESI 协议及 RFO 请求
现在主流的处理器都是用它来保证缓存的相干性和内存的相干性。M、E、S和
I 代表使用 MESI协议时缓存行所处的四个状态:
M(修改,Modified):本地处理器已经修改缓存行,即是脏行,它的内容与内存中的内容不一样,并且此cache 只有本地一个拷贝(专有);
E(专有,Exclusive):缓存行内容和内存中的一样,而且其它处理器都没有这行数据;
S(共享,Shared):缓存行内容和内存中的一样,有可能其它处理器也存在此缓存行的拷贝;
I(无效,Invalid):缓存行失效,不能使用。
初始化状态,本地读,远程读,远程写着几个操作对上述四个状态的改变。
1.4 falseSharing 场景
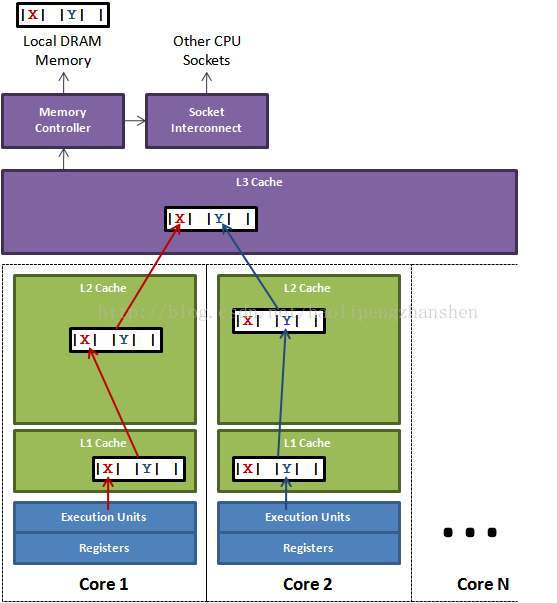
上图中,一个运行在处理器 core1上的线程想要更新变量 X 的值,同器时另外一个运行在处理 core2 上的线程想要更新变量 Y 的值。但是,这两个频繁改动的变量都处于同一条缓存行。两个线程就会轮番发送 RFO 消息,占得此缓存行的拥有权。当 core1 取得了拥有权开始更新 X,则 core2 对应的缓存行需要设为 I 状态。当 core2 取得了拥有权开始更新 Y,则 core1 对应的缓存行需要设为 I 状态(失效态)。轮番夺取拥有权不但带来大量的 RFO 消息,而且如果某个线程需要读此行数据时,L1 和 L2 缓存上都是失效数据,只有 L3 缓存上是同步好的数据。从前一篇我们知道,读 L3 的数据非常影响性能。更坏的情况是跨槽读取,L3 都要 miss,只能从内存上加载。
表面上 X 和 Y 都是被独立线程操作的,而且两操作之间也没有任何关系。只不过它们共享了一个缓存行,但所有竞争冲突都是来源于共享。
1.5 dpdk 的解决办法
cache预取原理
cache之所以能够提高系统性能,主要是程序执行存在局部性,时间局部性和空间局部性。
1)时间局部性:程序即将用到的指令/数据,可能就是当前正在使用的指令/数据。例子:循环语句
2)空间局部性:程序即将用到的指令/数据,可能是与目前正在使用的指令/数据在空间上相邻或相近。例子:需要顺序处理的数组
cache一致性
cache一致性的出现的原因,是在一个多处理器系统中,每个处理器核心有自己的cache系统,多个处理器核心都能够独立的执行计算机指令,从而可能同时对同一个内存块进行读写操作,导致一个内存块可能有多个备份,有的已经回写到内存中,有的在不同处理器核心的一级、二级、三级缓存中,我们不知道那个备份是最新的。
解决cache一致性的方法是使用MESI协议,对于某块内存,当其在多个cache中保留了一个备份时,只有部分状态是允许的。
dpdk如何保证cache一致性
cache这个问题的最根本原因是处理器内部不止一个核,当两个或多个核访问内存中同一个cache行的内容时,就会因为多个cache同时缓存了该内容引起同步的问题。
dpdk的解决方法:避免多个核访问同一个内存地址或者数据结构,每个核都尽量避免和其他核共享数据,从而减少因为false sharing导致的cache一致性的开销。
比如
struct lcore_conf {
uint16_t nb_rx_queue;
struct lcore_rx_queue rx_queue_list[MAX_RX_QUEUE_PER_LCORE];
uint16_t tx_queue_id[RTE_MAX_ETHPORTS];
struct buffer tx_mbufs[RTE_MAX_ETHPORTS];
struct ipsec_ctx inbound;
struct ipsec_ctx outbound;
struct rt_ctx *rt4_ctx;
struct rt_ctx *rt6_ctx;
} __rte_cache_aligned;
static struct lcore_conf lcore_conf[RTE_MAX_LCORE];
上面的数据结构struct lcore_conf 总是以Cache行对齐,这样就不会出现该数据结构横跨两个Cache行的问题。而定义的数组 lcore_conf[RTE_MAX_LCORE];
DPDK对每个核心进行编号,这样核n就只需访问lcore_conf[n],核m就只需访问lcore_conf[m],这样就避免了多个核访问同一个结构体。