指针理论篇
《目录》
- 指针的由来
- 指针类型在32位系统为什么占 4 字节 ?
- 科技公司的指针面试题,如何写的规范,讲的清晰,有木有工具辅助 ?
- 使用指针的注意事项,安全操作指南有没有呢 ?
- 单指针实现双指针的双链表
- 使用指针适合什么样的数据区间呢 ,为什么STL中所有算法的处理多是左闭右开区间[begin, end) ?
指针的由来
指针其实来源于民间的 织布机。
看上面俩张 织布机.gif,这俩张图代表了织布机 的原理。
织布机 的原理看起来很简单,一脚一脚踩下去针就一直缝下来。
仔细 TA 看设计的极为巧妙,轮子、线、针配合的如此神奇。
看第一幅图,轮子在上面的中间位置带着线开始向前,一直转到下半圈把线抛出去,这时线被一针的力量给拉上去......
指针和 织布机 的针 很像很像,也许会觉得很抽象吧。
纺织机我们明白其运作原理可能需要一些机器的知识,以 布 是怎么织出来的举个例子。
织布先要有线,把线条先纵向的排列好,一根接一根,这个叫 “经线”(竖着的线)
把线条再横向的排列好,一根接一根,这个叫 “纬线”(横着的线)
但纬线的排列还得一上一下,就是第一根压在经线上,下一根压在经线下,下下根压在经线上...,如此反复,当经线和纬线牢牢的锁住了,布就织好了。

不过,这样织出来的布颜色单一,且没有任何图案。
于是,人们把线染成不同的颜色,按照特定的手法就能形成一些有寓意的图案/花样,这个方法叫 “提花”。
历史上,那个时候的欧洲正从手工业转向机器大工业,人们开始大规模的使用各种机器代替人类的手工和体力劳动了。
因此,提花被制成了机器,就叫 “提花机”。
要组成一个有寓意的图案/花样,就需要经线和纬线在特定的位置穿过。
操作者需要记忆复杂的口诀,按照复杂的流程来操作,看起来十分复杂。
后来法国的纺织匠布修,发明了新的提花机,TA 在一条纸带的特定位置打上孔,而后用这些孔来控制经线的提起过程。

现在操作者就不需要背诵口诀,只需要不停的挪动这条纸带,这个纸带可以看成计算机的存储器。
纺织机打孔就是编程,布织出来了就是程序写好了;纺织的过程就是执行存储器中的程序指令。
纸带就提供了一个输入指令的方式,这个方式的好处就是,可以完整的写好一个指令,而后一次输入。
后来,经过几位发明家改进,最后在一位叫 雅卡尔 的人手里,完成了最终的改进。
雅卡尔织布机,就是一台可以编程的全自动织布机 。
 雅卡尔织布机
雅卡尔织布机
在商业活动和国家管理中,有很多复杂的计算工作要做。
有一个发明家叫巴贝奇,觉得计算工作完全可以交给机器来完成。他尝试制造了一台样机,通过各种齿轮的配合,这台机器能进行六位数的加法运算。
做出了这样一台机器之后,他信心满满,计划要造一个更大、更实用的计算机器。英国政府知道了这件事情,也很高兴,干脆给他下了个订单,说,“既然这样,你就给我们造一台吧。”
就在巴贝奇建造庞大计算机器的时候,埃达注意到了他的工作,也加入了进来。
雅卡尔织布机的影响没有局限在纺织这个领域内,也扩展到了其他的领域。
比如,他还影响了英国当时著名的大诗人拜伦,当然不是说,雅卡尔的织布机影响了拜伦的诗作,而是影响了他的女儿埃达。
埃达也很了不起,从某种意义上说,她比她父亲更了不起,因为她是世界上公认的第一位程序员。
她开始和巴贝奇反复讨论机器的各个细节,丰富巴贝奇的设计。
也许是对提花工艺非常熟悉的缘故,埃达突发奇想,觉得提花机上的那个纸带会派上大用处。
对提花机来说,纸带实际上提供了一个输入指令的方式,这个方式的好处是,您可以完整地写好一个指令,而后再一次性输入进去 。这比巴贝奇原来的想法(通过硬件一点点输入指令要好得多)。
埃达就在巴贝奇的分析机上,设计了第一个程序 --- 计算伯努利数,也因此被称为第一位程序员。
巴贝奇对此也非常满意。随后,埃达把他们的想法写成了论文。
埃达当时只有 27 岁,有着极高的数学造诣和研究热情。在她的帮助下(包括财力的资助),巴贝奇的工作取得了很大的进展,但不幸的是,她在 36 岁时英年早逝了。
埃达去世后,巴贝奇又独自坚持了 20 年,最终只完成了这台计算机的一小部分。因此他是带着遗憾离开人世的。所幸的是,巴贝奇和阿达留下了 30 种不同的设计方案,近 2100 张组装图和 50000 张零件图,清晰地告诉了后人他们的设计思想。
就这样,通过雅卡尔织布机成就了计算机,那指针又是如何来的 ?

摘自《32位、64位、128位系统是什么晷 ?》。
通过给每个地址编号,就可以准确的描述每一个地址;继而类似于 织布机 的穿针引线想出了一个可以指向任意内存地址的指针。
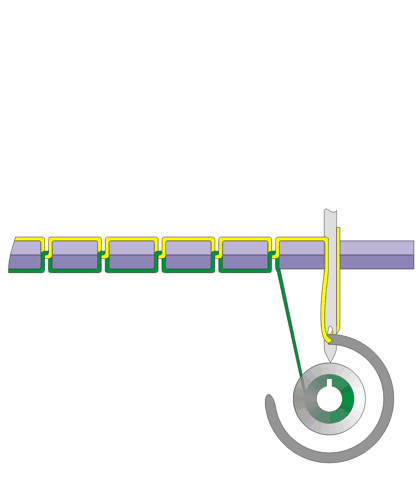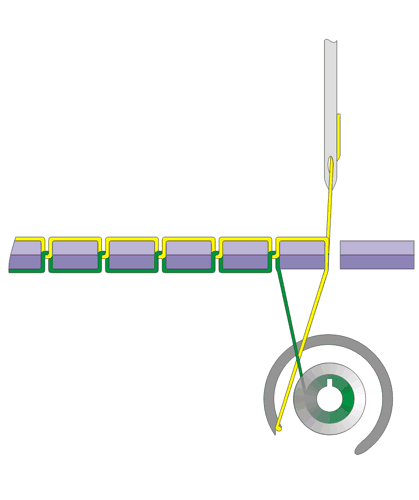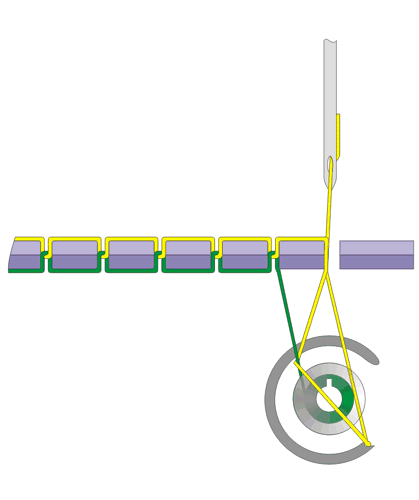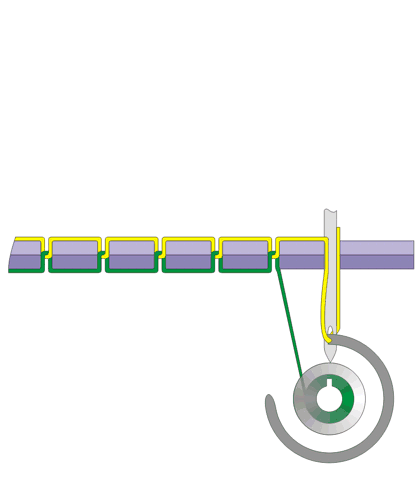
就这样,通过织布机也就创造了指针。
有木有觉得,织布机的图不太一样。就是第一、二副图和第四、五幅图工作的方式不太一样。
成就计算机的,的确是织布机;创造指针的,这个机器其实我也不知道叫什么,应该是叫 裁缝机,我这里一起说了您可能会有点混乱。
但世界上,第一台计算机不是 1946 年埃尼亚克 ,而是中国的算盘。

摘自《密码学》。
如果用一句话概括的话,算盘不仅有计算机的硬件,还有能够控制计算的指令集,也就是珠算口诀,相当于是计算机程序的基础,所以说,第一台计算机其实是中国的算盘。
从算盘,到帕斯卡、莱布尼茨,最后到 巴贝奇 和 埃达,计算机也从简单渐渐复杂......
指针类型在32位系统为什么占 4 字节 ?
记录在 《32位、64位、128位系统是什么晷 ?》的 32 位篇,不重述了。
科技公司的指针面试题,如何写的规范,讲的清晰,有木有工具辅助 ?
一般进去大公司,第一关就会遇到类似的题目:
![]()
在保证格式的前提下,用英文把答案写出来。
d is a pointer to a function that takes two parameters:
a reference to an int and
a pointer to a function that takes two parameters:■ a pointer to char and
■ a pointer to a pointer to a charand returns a pointer to a pointer to a char
and returns a pointer to a pointer to void
解释几个单词:
- pointer 是指针、function 是函数、takes two parameters 是俩个参数、reference 是引用、returns 是返回。
- ** 读作 a pointer to a pointe
- & 读作 a reference
- (*) 读作 a pointer to a function
OK,您可以试着念一遍,再翻译一遍。
那么,这份英文答案是怎么写出来的 ?
直接读,找到名字: d (未定义的标识符),d 不是 C/C++ 自带的关键字。
先往右看,是 " ) ",看到 " ) " 右边的 (int &, char **(*) (char *, char **)),显然 int & 和 char **(*) (...) 是 d 的俩个函数参数;
第二个函数参数 char **(*) (...) 还有俩个函数参数,char **(*) (...) 返回类型是 char **。
遇到括号就调转方向 ,返回类型就是 void ** ,翻译为英文如上所示了。
是不是觉得直接读,有点困难呢,这里我给您支个招 !!
C/C++ 中,复杂声明就是由各种声明嵌套而成的,有人从 C/C++ 标准的声明规定中归纳出一个法则。
C/C++ 标准的声明,是用来解决如何创建一个声明的,而这个法则就是用来如何辨识一个声明的,从嵌套的角度来说,俩种会逆。
这个法则叫 “右左法则”,首先从最里面的圆括号的未定义的标识符为起点,而后往右看,再往左看;
每当遇到圆括号时,就调转阅读方向;
如果圆括号里面的内容被解析完了,就跳出圆括号,重复这个过程直到整个声明结束。
写这个:int *(*(*fun) (int *)) [10] ,[fun] 是 最里面的圆括号的未定义的标识符。
- fun 和 * 结合,就是一个指针;
- fun 和 () 结合,就是一个函数;
- fun 和 [] 结合,就是一个数组;
建议随文字,画出分析过程:
使用 “右左法则”,以 [ fun ] 为起点,向右看就遇到括号 " ) ",遇到括号就调转方向,从右变左,看到 " * "。
- int * ( * (*fun) (int *) ) [10]
组成了 [ *fun ],是一个指针,继续往左看,遇到括号 " ( ",调转方向,从左变右,看到了另外的括号 " ( " ,说明 *fun 这个指针指向的是一个函数,这个函数的参数是 int * 也就是整型指针,再次调转方向,从右变左,看到一个 " * ",说明该指针所指的函数的返回值又是一个指针。
- int *( *(*fun) (int *) ) [10]
继续向左看,遇到括号 " ( ",调转方向,从左变右,又看到了括号 " ) ",至此内部的括号全部看完,把看完的当成一个整体后,您应该会觉得很简单了。
- int *( *(*fun) (int *) ) [10]
整理一下思路,这个声明可以这样说:
fun 是一个指针,该指针指向的是一个函数,该函数有一个整型指针的参数且返回值仍是一个指针;其返回值的指针指向的是一个拥有 10 个整型元素的数组。
推荐文章:《只需一招,彻底攻克C语言指针》。
其实变量的说明可以使用工具 :Cdecl 。
// Cdecl 源代码
#include
#include
#include
#include
#define MAXTOKENS 100
#define MAXTOKENLEN 64
enum type_tag { IDENTIFIER, QUALIFIER, TYPE };
struct token
{
char type;
char string[MAXTOKENLEN];
};
int top = -1;
struct token stack[MAXTOKENS];
struct token This;
#define pop stack[top--]
#define push(s) stack[++top] = s
/* figure out the identifier type */
enum type_tag classify_string(void)
{
char *s = This.string;
if (!strcmp(s, "const"))
{
strcpy(s, "read-only");
return QUALIFIER;
}
if (!strcmp(s, "volatile"))
return QUALIFIER;
if (!strcmp(s, "void"))
return TYPE;
if (!strcmp(s, "char"))
return TYPE;
if (!strcmp(s, "signed"))
return TYPE;
if (!strcmp(s, "unsigned"))
return TYPE;
if (!strcmp(s, "short"))
return TYPE;
if (!strcmp(s, "int"))
return TYPE;
if (!strcmp(s, "long"))
return TYPE;
if (!strcmp(s, "float"))
return TYPE;
if (!strcmp(s, "double"))
return TYPE;
if (!strcmp(s, "struct"))
return TYPE;
if (!strcmp(s, "union"))
return TYPE;
if (!strcmp(s, "enum"))
return TYPE;
return IDENTIFIER;
}
/* read next token into "this" */
void gettoken(void)
{
char *p = This.string;
/* read past any space */
while ((*p = getchar()) == ' ');
if (isalnum(*p))
{
/* it starts with A-Z, 0-9 read in identifier */
while (isalnum(*++p = getchar()));
ungetc(*p, stdin);
*p = '\0';
This.type = classify_string();
return;
}
if (*p == '&')
{
strcpy(This.string, "reference to");
This.type = '&';
return;
}
if (*p == '*')
{
strcpy(This.string, "pointer to");
This.type = '*';
return;
}
This.string[1] = '\0';
This.type = *p;
return;
}
/* the piece of code that understandeth all parsing */
void read_to_first_identifier()
{
gettoken();
while (This.type != IDENTIFIER )
{
push(This);
gettoken();
}
printf("%s is ", This.string);
gettoken();
}
void deal_with_arrays()
{
while (This.type == '[')
{
printf("array ");
gettoken(); /* a number or ']' */
if (isdigit(This.string[0]))
{
printf("0..%d ", atoi(This.string) - 1);
gettoken(); /* read the ']' */
}
gettoken(); /* read next past the ']' */
printf("of ");
}
}
void deal_with_function_args()
{
while (This.type != ')')
{
gettoken();
}
gettoken();
printf("function returning ");
}
void deal_with_pointers()
{
while (stack[top].type == '*')
{
printf("%s ", pop.string);
}
}
void deal_with_declarator()
{
/* deal with possible array/function following identifier */
switch (This.type)
{
case '[' : deal_with_arrays(); break;
case '(' : deal_with_function_args();
}
deal_with_pointers();
/* process tokens that we stacked while reading identifier */
while (top >= 0)
{
if (stack[top].type == '(')
{
pop;
gettoken(); /* read past ')' */
deal_with_declarator();
}
else
{
printf("%s ", pop.string);
}
}
}
void printM( )
{
/* put tokens on stack until we reach identifier */
read_to_first_identifier();
deal_with_declarator();
printf("\n");
}
int main( )
{
printM( );
return 0;
}
输入: void **(*d) (int &, char **(*) (char *, char **) )

输入:int *(*(*fun) (int *)) [10]

再修改修改,还可以倒过来解析;原理主要是数据结构的栈。
Linux 安装 Cdecl:sudo apt-get install cdecl 。
使用指针的注意事项,安全操作指南有没有呢 ?
- 指针变量一定要初始化为 NULL,因为任何指针变量刚被创建时不会自动成为NULL指针,TA的缺省值是随机的,有时会干扰程序。
- 当指针指向的内存被释放掉时,要将指针的值设置为 NULL,因为 free() 只是释放掉了内存,并为改变指针的值。

上图,释放内存后还让指针指向 NULL,为什么需要这么做呢 ?
自己做个实验。
#include
#include
int main( )
{
char *p; // 未初始化
printf(" 未初始化 p 的地址:%p\n\n", p);
p = NULL; // 初始化
printf(" 初始化 p 的地址:%p\n\n", p);
p = (char *)malloc( 1<<10 ); // 申请空间
if( NULL == p )
return -1;
printf(" 申请空间后 p 的地址:%p\n\n", p);
// 释放空间
free(p);
printf(" 释放空间后 p 的地址:%p\n\n", p);
// 释放空间后赋值为 NULL
p = NULL;
printf(" 释放空间后并赋值为 NULL,p 的地址:%p\n", p);
return 0;
} 运行结果:

发现 申请空间后的 p 、 释放空间后的 p 的内存地址是一样的。
那为什么需要多此一举,释放空间后再把 p 赋值为 NULL。
因为 free 掉了 p 后,0x7c20e30400 这块空间已经不是程序所有了,虽然 p 被释放后依然指向 0x7c20e30400;但是,如果我们再试图使用 p ,程序就会崩溃,因此最好赋值为 NULL,防止在写大型程序时不小心就引用导致错误。
单指针实现双指针的双链表
记录在《双链表》的单链表代双链表,不重述了。
使用指针适合什么样的数据区间呢 ,为什么STL中所有算法的处理多是左闭右开区间[begin, end) ?
我列出几点我认为的原因:
- 语言方面,C 语言的数组相当于是左闭右开的,for( int i = 0; i < len; i++ );
- 代码方面,左闭右开用来表达各种操作和算法的边界会简洁清晰很多,具体参见《C陷阱与缺陷》;
- 算法方面,像二分、快排,都是分治算法,一个左闭右开区间
[x,y),子区间可以分解为[x,y0),[y0,y1),[y1,y2)...[yn,y),父子同构,天然适合分治实现;在整数范围内,如果非要写为左闭右闭区间,也是可以的。[x,y]分解的子区间为[x,y0-1],[y0,y1-1],[y1,y2-1]...[yn,y]。但是无论怎么分,总有一个区间和其他不同,划分偏左或偏右一个元素,划分是不整齐的。要打各种边界处理补丁来弥补;假设是全开或全闭,写代码的时候就会出问题。
比如写二分法,区间为 [2,8],左右区间为 [2,5]、[5,8],5多了,算法的结果不准,有的人说可以这样写[2,5]、[6,8],是可以,但是在二分的时候还要对数据做处理才能分区间,不感觉别扭么。
C/C++ 的数组下标是 0 开始的,如果当时设计是从1开始,那么我们今天的可能是左开右闭了,比方说(0,5]、(5,10],而不是现在的[0,5),[5,10)。