np2016课程总结
- 项目总览
- 项目地址托管
- 项目功能
- 项目依赖
- 运行环境安装如果已安装上述依赖项目可跳过
- 安装numpy
- 安装opencv
- 安装pytesseract
- 安装Flask框架
- 安装mongodb
- 安装Tensorflow基于 VirtualEnv 的安装
- 模块说明
- view
- imageFilter
- tf_predict
- 运行演示
- 运行
- 打开浏览器
- 选择图片
- 生成报告
- 预测
- 心得总结
- 学习心得
- 神经网络
- 总结
项目总览
项目地址托管
本项目为多人开发,采用GitCoding进行代码托管和版本控制
coding.net: [ 血常规检验报告OCR ]
项目功能
本次项目为神经网络程序设计,利用深度学习等机器学习相关算法与框架实现一个医学辅助诊断的专家系统原型,具体切入点为对血常规检验报告的OCR识别、深度学习与分析。受时间所限目前只完成了通过对血常规检验报告分析预测年龄和性别。
项目依赖
- numpy
- opencv
- pytesseract
- Flask
- mongodb
- tensorflow
运行环境安装(如果已安装上述依赖项目可跳过)
安装numpy
$ sudo apt-get install python-numpy
安装opencv
$ sudo apt-get install python-opencv
安装pytesseract
$ sudo apt-get install tesseract-ocr
$ sudo pip install pytesseract
$ sudo apt-get install python-tk
$ sudo pip install pillow
安装Flask框架
$ sudo pip install Flask
安装mongodb
sudo apt-get install mongodb
sudo service mongodb restart
sudo pip install pymongo
安装Tensorflow(基于 VirtualEnv 的安装)
首先, 安装所有必备工具:
$ sudo apt-get install python-pip python-dev python-virtualenv
接下来, 建立一个全新的 virtualenv 环境. 为了将环境建在 ~/tensorflow 目录下, 执行:
$ virtualenv –system-site-packages ~/tensorflow
$ cd ~/tensorflow
然后, 激活 virtualenv:
$ source bin/activate
(tensorflow)$ # 终端提示符应该发生变化
在 virtualenv 内, 安装 TensorFlow:
(tensorflow)$ pip install –upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.12.0rc0-cp27-none-linux_x86_64.whl
模块说明
view
基于Flask框架搭建web端、维护Mongodb数据库,与用户进行交互。下图是该模块函数图。

代码的主要部分
# 将矫正后图片与图片识别结果(JSON)存入数据库
def save_file(file_str, f, report_data):
content = StringIO(file_str)
try:
mime = Image.open(content).format.lower()
print 'content of mime is:', mime
if mime not in app.config['ALLOWED_EXTENSIONS']:
raise IOError()
except IOError:
abort(400)
c = dict(report_data=report_data, content=bson.binary.Binary(content.getvalue()), filename=secure_filename(f.name),
mime=mime)
db.files.save(c)
return c['_id'], c['filename']
'''
定义file_str存储矫正后的图片文件f的内容(str格式),方便之后对图片做二次透视以及将图片内容存储至数据库中
'''
file_str = f.read()
'''
使用矫正后的图片,将矫正后图片与识别结果(JSON数据)一并存入mongoDB,
这样前台点击生成报告时将直接从数据库中取出JSON数据,而不需要再进行图像透视,缩短生成报告的响应时间
'''
fid, filename = save_file(file_str, f, report_data)
print 'fid:', fid
if fid is not None:
templates = " " % (
fid)
data = {
"templates": templates,
}
return jsonify(data)
return jsonify({"error": "No POST methods"})
'''
根据图像oid,在mongodb中查询,并返回Binary对象
'''
'''
直接从数据库中取出之前识别好的JSON数据,并且用bson.json_util.dumps将其从BSON转换为JSON格式的str类型
'''
@app.route('/report/
" % (
fid)
data = {
"templates": templates,
}
return jsonify(data)
return jsonify({"error": "No POST methods"})
'''
根据图像oid,在mongodb中查询,并返回Binary对象
'''
'''
直接从数据库中取出之前识别好的JSON数据,并且用bson.json_util.dumps将其从BSON转换为JSON格式的str类型
'''
@app.route('/report/')
def get_report(fid):
# print 'get_report(fid):', fid
try:
file = db.files.find_one(bson.objectid.ObjectId(fid))
if file is None:
raise bson.errors.InvalidId()
print 'type before transform:\n', type(file['report_data'])
report_data = bson.json_util.dumps(file['report_data'])
print 'type after transform:\n', type(report_data)
if report_data is None:
print 'report_data is NONE! Error!!!!'
return jsonify({"error": "can't ocr'"})
return jsonify(report_data)
except bson.errors.InvalidId:
flask.abort(404)
@app.route("/predict", methods=['POST'])
def predict():
print ("predict now!")
data = json.loads(request.form.get('data'))
ss = data['value']
arr = numpy.array(ss)
arr = numpy.reshape(arr, [1, 22])
sex, age = tf_predict.predict(arr)
result = {
"sex":sex,
"age":int(age)
}
return json.dumps(result)
imageFilter
基于opencv与pytesseract实现对图片进行处理并识别。图片处理的主要过程有:灰度化、二值化、腐蚀、膨胀、直方图均衡化、中值滤波等前期操作;边缘检测、轮廓提取、画线、透视变换、精准定位、裁剪等中期操作;最后则是OCR识别。
下图是该模块函数图。

代码的主要部分
class ImageFilter:
'''
perspect函数用于透视image,他会缓存一个透视后的opencv numpy矩阵,并返回该矩阵
透视失败,则会返回None,并打印不是报告
@param 透视参数
'''
def perspect(self, param=default):
#载入参数
gb_param = param[0] #必须是奇数
canny_param_upper = param[1]
canny_param_lower = param[2]
ref_lenth_multiplier = param[3]
ref_close_multiplier = param[4]
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(3, 3))
# 载入图像,灰度化,开闭运算,描绘边缘
img_sp = self.img.shape
ref_lenth = img_sp[0] * img_sp[1] * ref_lenth_multiplier
img_gray = cv2.cvtColor(self.img, cv2.COLOR_BGR2GRAY)
img_gb = cv2.GaussianBlur(img_gray, (gb_param, gb_param), 0)
closed = cv2.morphologyEx(img_gb, cv2.MORPH_CLOSE, kernel)
opened = cv2.morphologyEx(closed, cv2.MORPH_OPEN, kernel)
edges = cv2.Canny(opened, canny_param_lower , canny_param_upper)
# 调用findContours提取轮廓
contours, hierarchy = cv2.findContours(edges, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
def getbox(i):
rect = cv2.minAreaRect(contours[i])
box = cv2.cv.BoxPoints(rect)
box = np.int0(box)
return box
def distance(box):
delta1 = box[0]-box[2]
delta2 = box[1]-box[3]
distance1 = np.dot(delta1,delta1)
distance2 = np.dot(delta2,delta2)
distance_avg = (distance1 + distance2) / 2
return distance_avg
# 将轮廓变为线
line = []
for i in found:
box = i[1]
point1, point2, lenth = getline(box)
line.append([point1, point2, lenth])
# 由三条线来确定表头的位置和表尾的位置
line_upper, line_lower = findhead(line[2],line[1],line[0])
def detectmiss(line, line_lower, ref_angle):
vector = []
j = 0
if linecmp(line[1], line_lower):
j = 1
elif linecmp(line[2], line_lower):
j = 2
lenth = len(line)
for i in range(lenth):
if i != j:
vector.append([line[j][0]-line[i][0], line[j][1]-line[i][1]])
vect1 = vector[0][0]
vect2 = vector[0][1]
vect3 = vector[1][0]
vect4 = vector[1][1]
angle1 = (math.acos(np.dot(vect3, vect1) / ((np.dot(vect1, vect1) ** 0.5) * (np.dot(vect3, vect3)**0.5))))/math.pi*180
angle2 = (math.acos(np.dot(vect4, vect2) / ((np.dot(vect2, vect2) ** 0.5) * (np.dot(vect4, vect4)**0.5))))/math.pi*180
if angle1 > ref_angle or angle2 > ref_angle:
return 1
return 0
# 通过计算夹角来检测是否有缺失一角的情况
ref_angle = 1
if detectmiss(line, line_lower, ref_angle):
print "it is not a complete Report!"
return None
# 由表头和表尾确定目标区域的位置
#设定透视变换的矩阵
points = np.array([[line_upper[0][0], line_upper[0][1]], [line_upper[1][0], line_upper[1][1]],
[line_lower[0][0], line_lower[0][1]], [line_lower[1][0], line_lower[1][1]]],np.float32)
standard = np.array([[0,0], [1000, 0], [0, 760], [1000, 760]],np.float32)
'''
autocut函数用于剪切ImageFilter中的img成员,剪切之后临时图片保存在out_path,
如果剪切失败,返回-1,成功返回0
@num 剪切项目数
@param 剪切参数
'''
def autocut(self, num, param=default):
if self.PerspectiveImg is None:
self.PerspectivImg = self.filter(param)
# 仍然是空,说明不是报告
if self.PerspectiveImg is None:
return -1
#输出年龄
img_age = self.PerspectiveImg[15 : 70, 585 : 690]
cv2.imwrite(self.output_path + 'age.jpg', img_age)
#输出性别
img_gender = self.PerspectiveImg[15 : 58, 365 : 420]
cv2.imwrite(self.output_path + 'gender.jpg', img_gender)
#输出时间
img_time = self.PerspectiveImg[722 : 760, 430 : 630]
cv2.imwrite(self.output_path + 'time.jpg', img_time)
#输出图片
if num <= 13 and num > 0:
for i in range(num):
getobjname(int(i), 25, startpoint[1])
getobjdata(int(i), startpoint[0], startpoint[1])
startpoint[1] = startpoint[1] + 40
elif num > 13:
for i in range(13):
getobjname(int(i), 25, startpoint[1])
getobjdata(int(i), startpoint[0], startpoint[1])
startpoint[1] = startpoint[1] + 40
startpoint = [700, 135]
for i in range(num-13):
getobjname(int(i+13), 535, startpoint[1])
getobjdata(int(i+13), startpoint[0], startpoint[1])
startpoint[1] = startpoint[1] + 40
# 识别检测项目编号及数字
for i in range(num):
item = read('temp_pics/p' + str(i) + '.jpg')
item_num = classifier.getItemNum(item)
image = read('temp_pics/data' + str(i) + '.jpg')
image = imgproc.digitsimg(image)
digtitstr = image_to_string(image)
digtitstr = digtitstr.replace(" ", '')
digtitstr = digtitstr.replace("-", '')
digtitstr = digtitstr.strip(".")
data['bloodtest'][item_num]['value'] = digtitstr
json_data = json.dumps(data,ensure_ascii=False,indent=4)
return json_data
tf_predict
基于tensorflow,实现模型训练并完成预测。
下图是该模块函数图。

代码的主要部分
'''
参数
'''
learning_rate = 0.005
display_step = 100
n_input = 22
n_hidden_1_age = 32
n_hidden_2_age = 16
n_classes_age = 1
n_hidden_1_sex = 16
n_hidden_2_sex = 8
n_classes_sex = 2
data = np.loadtxt(open("./data.csv", "rb"), delimiter=",", skiprows=0)
'''
建立年龄模型
'''
x_age = tf.placeholder("float", [None, n_input])
y_age = tf.placeholder("float", [None, n_classes_age])
def multilayer_perceptron_age(x_age, weights_age, biases_age):
# Hidden layer with RELU activation
layer_1 = tf.add(tf.matmul(x_age, weights_age['h1']), biases_age['b1'])
layer_1 = tf.nn.relu(layer_1)
# Hidden layer with RELU activation
layer_2 = tf.add(tf.matmul(layer_1, weights_age['h2']), biases_age['b2'])
layer_2 = tf.nn.relu(layer_2)
# Output layer with linear activation
out_layer = tf.matmul(layer_2, weights_age['out']) + biases_age['out']
return out_layer
weights_age = {
'h1': tf.Variable(tf.random_normal([n_input, n_hidden_1_age])),
'h2': tf.Variable(tf.random_normal([n_hidden_1_age, n_hidden_2_age])),
'out': tf.Variable(tf.random_normal([n_hidden_2_age, n_classes_age]))
}
biases_age = {
'b1': tf.Variable(tf.random_normal([n_hidden_1_age])),
'b2': tf.Variable(tf.random_normal([n_hidden_2_age])),
'out': tf.Variable(tf.random_normal([n_classes_age]))
}
pred_age = multilayer_perceptron_age(x_age, weights_age, biases_age)
'''
建立性别模型
'''
'''
共同的初始化
'''
saver = tf.train.Saver()
init = tf.global_variables_initializer()
with tf.Session() as sess:
saver.restore(sess, "./model.ckpt")
print ("load model success!")
p_sex = sess.run(pred_sex, feed_dict={x_sex: data_predict})
p_age = sess.run(pred_age, feed_dict={x_age: data_predict})
if p_sex[0][0] > p_sex[0][1]:
sex_result = 1
else:
sex_result = 0
age_result = p_age[0][0] * 50 +50
return sex_result,age_result
运行演示
运行
$ cd BloddTestReportOCR
$ python view.py
打开浏览器
打开浏览器,输入http://0.0.0.0:8080

选择图片
选择图片并提交
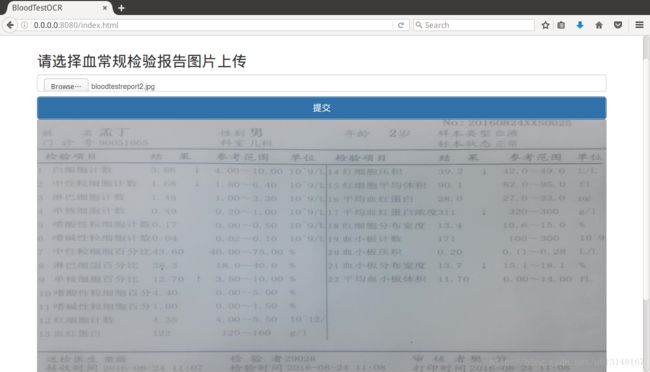
生成报告
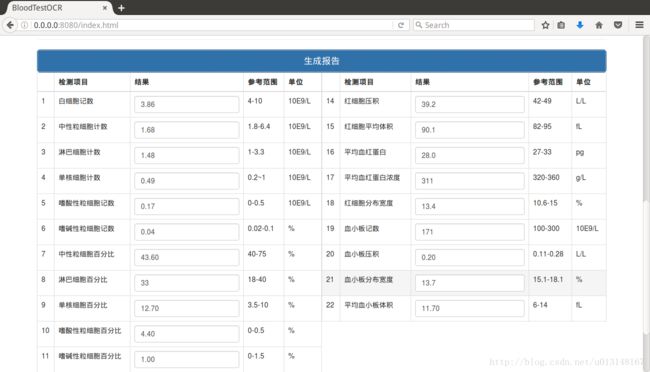
预测
点击predict获取结果

心得总结
学习心得
本次课程第一次接触python和神经网络。开始上课时觉得新鲜富有挑战性,而且老师介绍的前景也非常炫酷。A1任务做下来感觉挺轻松的,虽然并没有给老师检查。然而A2才是正真的开始:图像处理OCR识别。图像处理opencv虽然没在python下做过,但至少在C++里接触过,但是OCR却是听一次听说了,于是只能去百度了(听说正真的大神从来都只是google)。从此走上了百度、google的不归路,不停地配环境、看代码、运行调bug。然而每当我刚弄清楚,准备完成项目要求或者正在完成中,早已有大神pull request并合并了。这样当然会受到打击,但是打击归打击,课程还是要继续,毕竟我是一个noob,别的不行,抗打击能力还是有的。于是一边按照自己的计划追赶,一遍无奈的fork最新的代码,研读运行。研读大神的代码,学习他们的思路,同时又暗暗希望找出可以改进的地方,pull上去获取commit。结果当然一如往常,并没有我的事。于是就这样读代码读到了课程结束。整个项目中,我作为一份子,并不能做多少贡献,仅仅总结了一下Mxnet的环境配置,获得了一次commit,当了一次吃瓜群众。

神经网络
为了得到一张给定图片属于某个特定数字类的证据(evidence),我们对图片像素值进行加权求和。如果这个像素具有很强的证据说明这张图片不属于该类,那么相应的权值为负数,相反如果这个像素拥有有利的证据支持这张图片属于这个类,那么权值是正数。下面的图片显示了一个模型学习到的图片上每个像素对于特定数字类的权值。红色代表负数权值,蓝色代表正数权值。

总结
总的来说,项目驱动的确是学习的最快方式,能够时时激励者我学习。随着项目跟进,你会被需求和问题驱动着不停去学习新的知识,不断去提高自己的效率;而实践的成果,又会让你感觉每时每刻都在进步。这样的授课方式非常适合我们软院。多人协作与精准详细的周计划给人已巨大的压力同时又能使能力者收获成功的快感与荣耀。这样的授课方式既能使有能力者突出表现,又能使普罗大众不虚度,使得不同水平的同学都能有所收获。