4.集成学习之1.Bagging
基于bagging思想的套袋集成技术
套袋方法是由柳.布莱曼在1994年的技术报告中首先提出并证明了套袋方法可以提高不稳定模型的准确度的同时降低过拟合的程度(可降低方差)。
套袋方法的流程如下:
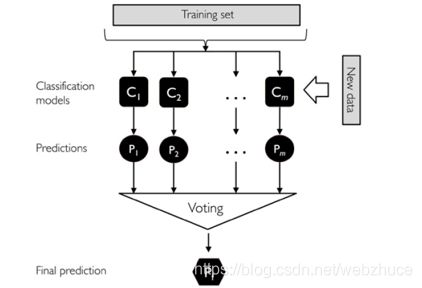
注意:套袋方法与投票方法的不同:
投票机制在训练每个分类器的时候都是用相同的全部样本,而Bagging方法则是使用全部样本的一个随机抽样,每个分类器都是使用不同的样本进行训练。其他都是跟投票方法一模一样!
- 对训练集随机采样
- 分别基于不同的样本集合训练n个弱分类器。
- 对每个弱分类器输出预测结果,并投票(如下图)
- 每个样本取投票数最多的那个预测为该样本最终分类预测。

我们使用葡萄酒数据集进行建模(数据处理):
## 我们使用葡萄酒数据集进行建模(数据处理)
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)
df_wine.columns = ['Class label', 'Alcohol','Malic acid', 'Ash','Alcalinity of ash','Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols','Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']
df_wine = df_wine[df_wine['Class label'] != 1] # drop 1 class
y = df_wine['Class label'].values
X = df_wine[['Alcohol','OD280/OD315 of diluted wines']].values
from sklearn.model_selection import train_test_split # 切分训练集与测试集
from sklearn.preprocessing import LabelEncoder # 标签化分类变量
le = LabelEncoder()
y = le.fit_transform(y)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y)
我们使用单一决策树分类:
## 我们使用单一决策树分类:
tree = DecisionTreeClassifier(criterion='entropy',random_state=1,max_depth=None) #选择决策树为基本分类器
from sklearn.metrics import accuracy_score
tree = tree.fit(X_train,y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pred)
tree_test = accuracy_score(y_test,y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))
输出结果
![]()
我们使用BaggingClassifier分类:
## 我们使用BaggingClassifier分类:
from sklearn.ensemble import BaggingClassifier
tree = DecisionTreeClassifier(criterion='entropy',random_state=1,max_depth=None) #选择决策树为基本分类器
bag = BaggingClassifier(base_estimator=tree,n_estimators=500,max_samples=1.0,max_features=1.0,bootstrap=True,
bootstrap_features=False,n_jobs=1,random_state=1)
from sklearn.metrics import accuracy_score
bag = bag.fit(X_train,y_train)
y_train_pred = bag.predict(X_train)
y_test_pred = bag.predict(X_test)
bag_train = accuracy_score(y_train,y_train_pred)
bag_test = accuracy_score(y_test,y_test_pred)
print('Bagging train/test accuracies %.3f/%.3f' % (bag_train,bag_test))
输出结果
![]()
我们可以对比两个准确率,测试准确率较之决策树得到了显著的提高
我们来对比下这两个分类方法上的差异:
## 我们来对比下这两个分类方法上的差异
x_min = X_train[:, 0].min() - 1
x_max = X_train[:, 0].max() + 1
y_min = X_train[:, 1].min() - 1
y_max = X_train[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=1, ncols=2,sharex='col',sharey='row',figsize=(12, 6))
for idx, clf, tt in zip([0, 1],[tree, bag],['Decision tree', 'Bagging']):
clf.fit(X_train, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx].contourf(xx, yy, Z, alpha=0.3)
axarr[idx].scatter(X_train[y_train==0, 0],X_train[y_train==0, 1],c='blue', marker='^')
axarr[idx].scatter(X_train[y_train==1, 0],X_train[y_train==1, 1],c='green', marker='o')
axarr[idx].set_title(tt)
axarr[0].set_ylabel('Alcohol', fontsize=12)
plt.tight_layout()
plt.text(0, -0.2,s='OD280/OD315 of diluted wines',ha='center',va='center',fontsize=12,transform=axarr[1].transAxes)
plt.show()
输出结果
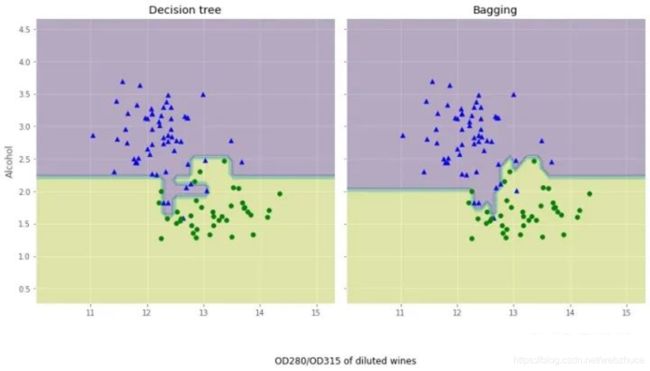
从结果图看起来,三个节点深度的决策树分段线性决策边界在Bagging集成中看起来更加平滑。