机器学习决策树算法解决图像识别
算法介绍
什么是决策树算法
决策树又称判定树,是一个类似于流程图的树结构:其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布。树的最顶层是根结点。
构造决策树的基本算法
主要评估标准,准确率,速度,健壮性,可规模性,可解释性
样例:研究某人今天会不会出去玩?
历史数据:
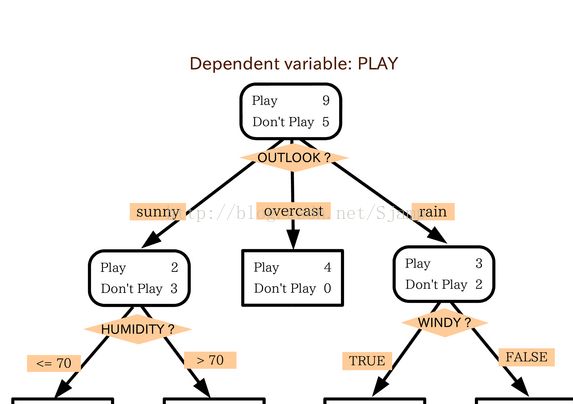
从图片中可以看出来,此人前14天中9天出去玩,5天没有出去玩,其中由于天气情况原因,晴天2天出去玩,3天没有出去玩,阴天4天出去玩,0天没有出去玩,雨天3天出去玩,2天没有出去玩,然后由于湿度和风力影响,又有了下一轮决策是否出去玩的情况。以此类推分析分类此人是否会出去玩。
2.1.3 熵
例子:猜世界杯冠军,假如一无所知,假如每个队夺冠的几率都是相等的,那么需要猜多少次?
过程:是否是在前16只队伍中,32/2,用二分法可知,需要猜5次。
熵的单位是bit
info(D) = -(1/32*log(1/32)+1/32*log(1/32)+1/32*log(1/32) +1/32*log(1/32)+1/32*log(1/32)...)累加32次
info(D)= 5bit
结论:数据量越大,熵值越大,不准确率越高
熵的差值则为有条件后的概率优化程度,以前面的案例分析,如果直接猜测某人会不会出去玩。结果为:
如果加上天气情况分析,结果为:
所以在已知天气情况的条件下,数据准确率优化了0.246
2.1.4 算法优缺点
优点:直观,便于理解,小规模数据集有效
缺点:处理连续变量不好,类别较多时,错误增加的比较快,可规模性一般
2.2 逻辑分析
此时不得不让我非常开心,那如何利用决策树来做图像识别呢?对此还是让很多人无法理解,现在就慢慢向大家阐述。
再次对上述案例进行分析
| 天气 |
湿度 |
风力 |
是否出去玩 |
| sunny |
<=70 |
无 |
玩 |
| sunny |
<=70 |
无 |
玩 |
| sunny |
>70 |
无 |
不玩 |
| sunny |
>70 |
无 |
不玩 |
| sunny |
>70 |
无 |
不玩 |
| overcast |
无 |
无 |
玩 |
| overcast |
无 |
无 |
玩 |
| overcast |
无 |
无 |
玩 |
| overcast |
无 |
无 |
玩 |
| rain |
无 |
风 |
不玩 |
| rain |
无 |
风 |
不玩 |
| rain |
无 |
没风 |
玩 |
| rain |
无 |
没风 |
玩 |
| rain |
无 |
没风 |
玩 |
然后程序化上述程序:
天气为三维,设置晴天为[1,0,0],那么多云为[0,1,0],雨天为[0,0,1]
湿度为三维,设置<=70为[1,0,0],那么>70为[0,1,0],无为[0,0,1]
风力为三维,设置有风为[1,0,0],那么无风为[0,1,0],无为[0,0,1]
是否出去玩为二维,设置玩为[1],不玩为[0]
由此可知第一项则为 [1,0,0,1,0,0,0,0,1],结果为[1]
以此类推。
之后得出矩阵的计算其最优单位向量个数,
[1,0,0,1,0,0,0,0,1
1,0,0,1,0,0,0,0,1
1,0,0,0,1,0,0,0,0]
每三列则为一个特征向量,然后进行计算熵值最小情况下哪些向量所占权重最大。
但是如何去分析图像相似还是有很大距离,在图像中会有很大像素,例如60*60像素的图片,每个像素点会转换为类似[255,200,10]RGB类型,本报告进行简单分析,首先将图片进行灰度图化,转化为例如[245],然后对下个像素点大小与之比较,大则为0,小则为1,由于图像像素点大,之后会转换为复杂矩阵,之后再对矩阵进行特征向量切割,例如:
[1,0,0,1,0,0,0,0,1
1,0,1,1,0,1,0,0,1
1,0,0,0,1,0,0,0,0]
此矩阵特征向量则为2,1,2,3,1分列,然后在进行熵值计算,权重比对,计算出最合理向量权重占比,之后再对测试图像中的向量进行比对,就可以进算出其相似度。
图像分析结果相当出众,可以对动态相似图片与其他图片有比较大的区分。
6.3 代码实现
编程语言为python ,利用Anaconda2环境编写,测试图片见附录
| # -*- coding: utf-8 -*- |