贝叶斯公式的理解(先验后验的区别)和极大似然估计
目录
-
- 一、贝叶斯公式的理解
-
- 1、条件概率
- 2、全概率公式
- 3、贝叶斯公式
- 4、先验概率和后验
- 二、极大似然估计
-
- 例子
- 参考文章:
一、贝叶斯公式的理解
一直容易把最基础的贝叶斯公式里的概念搞混(主要是先验后验)。先上核心知识,贝叶斯公式是
P(B|A)=P(A|B)P(B)/P(A)
贝叶斯公式就是当已知结果,问导致这个结果的第i原因的可能性是多少?执果索因!
先验概率是指根据以往经验和分析得到的概率,如全概率公式,它往往作为"由因求果"问题中的"因"出现.(一般在计算中已知的原因和结果就是先验)
后验概率是指依据得到"结果"信息所计算出的最有可能是那种事件发生,如贝叶斯公式中的,是"执果寻因"问题中的"因".(一般未知需根据结果和原因求的是后验)
【重要】:
不是根据"模样"来判断是先验还是后验,而是根据该数据能否"直接得到"且不经过"贝叶斯理论"计算才认为是先验的,也就是说,一个东西是不是先验,光看P(A|B)这种形式是定不下来的,需要看上下文。
下面从介绍几个概念开始:
1、条件概率
这个很简单,学过概率理论的人都知道条件概率的公式:
P(AB)=P(A)P(B|A)=P(B)P(A|B);
即事件A和事件B同时发生的概率等于在发生A的条件下B发生的概率乘以A的概率。
举个例子,比如让你背对着一个人,让你猜猜背后这个人是女孩的概率是多少?直接猜测,肯定是只有50%的概率,假如现在告诉你背后这个人是个长头发,那么女的概率就变为90%。所以条件概率的意义就是,当给定条件发生变化后,会导致事件发生的可能性发生变化。
条件概率由文氏图出发,比较容易理解:
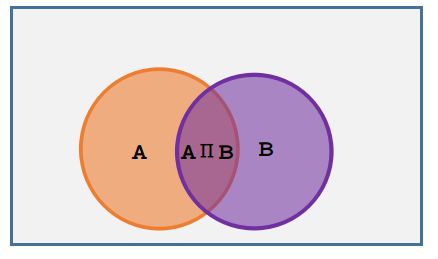
P(A|B) 表示B发生后A发生的概率,由上图可以看出B发生后,A再发生的概率就是
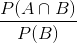 ,
,
因此:
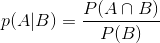
由:
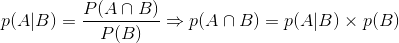
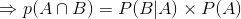
得:
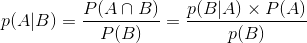
这就是条件概率公式。
假如事件A与B相互独立,那么:
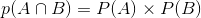
注:
相互独立:表示两个事件发生互不影响。而互斥:表示两个事件不能同时发生,(两个事件肯定没有交集)。互斥事件一定不独立(因为一件事的发生导致了另一件事不能发生);独立事件一定不互斥,(如果独立事件互斥, 那么根据互斥事件一定不独立,那么就矛盾了)
2、全概率公式
假设B是由相互独立的事件组成的概率空间{B1,b2,…bn}。则P(A)可以用全概率公式展开:
P(A)=P (A|B1)P(B1)+P(A|B2)P(B2)+…P(A|Bn)P(Bn)。
举个例子,小张从家到公司上班总共有三条路可以直达(如下图),但是每条路每天拥堵的可能性不太一样,由于路的远近不同,选择每条路的概率如下:
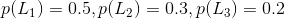
每天上述三条路不拥堵的概率分别为:
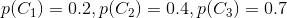
假设遇到拥堵会迟到,那么小张从Home到Company不迟到的概率是多少?

其实不迟到就是对应着不拥堵,设事件C为到公司不迟到,事件 为选择第i条路,则:
为选择第i条路,则:
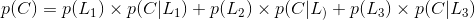
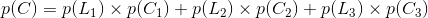
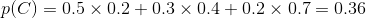
全概率就是表示达到某个目的,有多种方式(或者造成某种结果,有多种原因),问达到目的的概率是多少(造成这种结果的概率是多少)?
全概率公式:
设事件 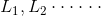 是一个完备事件组,则对于任意一个事件C,若有如下公式成立:
是一个完备事件组,则对于任意一个事件C,若有如下公式成立:

那么就称这个公式为全概率公式。
3、贝叶斯公式
仍旧借用上述的例子,但是问题发生了改变,问题修改为:到达公司未迟到选择第1条路的概率是多少?
可不是 p(L1)=0.5 因为0.5这个概率表示的是,选择第一条路的时候并没有靠考虑是不是迟到,只是因为距离公司近才知道选择它的概率,而现在我们是知道未迟到这个结果,是在这个基础上问你选择第一条路的概率,所以并不是直接就可以得出的。
故有:
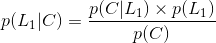

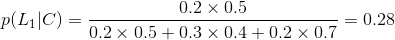
所以选择第一条路的概率为0.28.
贝叶斯公式就是当已知结果,问导致这个结果的第i原因的可能性是多少?执果索因!
贝叶斯公式:
在已知条件概率和全概率的基础上,贝叶斯公式是很容易计算的:
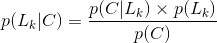


4、先验概率和后验
在贝叶斯法则中,每个名词都有约定俗成的名称:
P(A)是A的先验概率或边缘概率。之所以称为"先验"是因为它不考虑任何B方面的因素。
P(A|B)是已知B发生后A的条件概率,也由于得自B的取值而被称作A的后验概率。
P(B|A)是已知A发生后B的条件概率,也由于得自A的取值而被称作B的后验概率。
P(B)是B的先验概率或边缘概率,也作标准化常量(normalized constant)。
按这些术语,Bayes法则可表述为:
后验概率 = (似然度 * 先验概率)/标准化常量 也就是说,后验概率与先验概率和似然度的乘积成正比。
另外,比例P(B|A)/P(B)也有时被称作标准似然度(standardised likelihood),Bayes法则可表述为:
后验概率 = 标准似然度 * 先验概率
(这也是把极大似然估计放到一篇文章的缘故,详细可参考https://blog.csdn.net/u011508640/article/details/72815981)
总结:
贝叶斯公式在在机器学习中重要的原因可能是:很多问题是需要计算机在已知条件下做出最佳决策的决策,而贝叶斯公式就是对人脑在已知条件下做出直觉判断的一种数学表示.。
贝叶斯定理或者说统计,更多的是给了我们一种认识世界的世界观和方法论。关于概率论和统计学我比较喜欢的两句话:
“概率论只不过是把常识用数学公式表达了出来”—拉普拉斯
统计的方法论就是能够帮助我们透视 不确定性 (probability)以及 数据背后的原理 (inference),从而找到最好的应对方式。
二、极大似然估计
极大似然估计,通俗理解来说,就是利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值!
换句话说,极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。EM算法的M步就是将似然函数最大化以获得新的参数值。
当模型满足某个分布,它的参数值我通过极大似然估计法求出来的话。最常见的比如正态分布中公式如下:
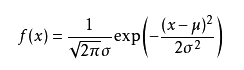
如果我通过极大似然估计,得到模型中参数 μ \mu μ和 σ \sigma σ的值,那么这个模型的均值和方差以及其它所有的信息我们就知道了。
极大似然估计中采样需满足一个重要的假设,就是所有的采样都是独立同分布的。
举例说明前先说一下似然函数,取自上面的博客文章

例子
假如有一个罐子,里面有黑白两种颜色的球,数目多少不知,两种颜色的比例也不知。我 们想知道罐中白球和黑球的比例,但我们不能把罐中的球全部拿出来数。现在我们可以每次任意从已经摇匀的罐中拿一个球出来,记录球的颜色,然后把拿出来的球 再放回罐中。这个过程可以重复,我们可以用记录的球的颜色来估计罐中黑白球的比例。假如在前面的一百次重复记录中,有七十次是白球,请问罐中白球所占的比例最有可能是多少?
很多人马上就有答案了:70%。而其后的理论支撑是什么呢?
我们假设罐中白球的比例是p,那么黑球的比例就是1-p。因为每抽一个球出来,在记录颜色之后,我们把抽出的球放回了罐中并摇匀,所以每次抽出来的球的颜 色服从同一独立分布。
这里我们把一次抽出来球的颜色称为一次抽样。题目中在一百次抽样中,七十次是白球的,三十次为黑球事件的概率是P(样本结果|Model)。
如果第一次抽象的结果记为x1,第二次抽样的结果记为x2…那么样本结果为(x1,x2…,x100)。这样,我们可以得到如下表达式:
P(样本结果|Model)
= P(x1,x2,…,x100|Model)
= P(x1|Mel)P(x2|M)…P(x100|M)
= p70(1-p)30.
好的,我们已经有了观察样本结果出现的概率表达式了。那么我们要求的模型的参数,也就是求的式中的p。
那么我们怎么来求这个p呢?
不同的p,直接导致P(样本结果|Model)的不同。
好的,我们的p实际上是有无数多种分布的。如下:

那么求出 p70(1-p)30为 7.8 * 10^(-31)
p的分布也可以是如下:

那么也可以求出p70(1-p)30为2.95* 10^(-27)
那么问题来了,既然有无数种分布可以选择,极大似然估计应该按照什么原则去选取这个分布呢?
答:采取的方法是让这个样本结果出现的可能性最大,也就是使得p70(1-p)30值最大,那么我们就可以看成是p的方程,求导即可!
那么既然事情已经发生了,为什么不让这个出现的结果的可能性最大呢?这也就是最大似然估计的核心。
我们想办法让观察样本出现的概率最大,转换为数学问题就是使得:
p70(1-p)30最大,这太简单了,未知数只有一个p,我们令其导数为0,即可求出p为70%,与我们一开始认为的70%是一致的。其中蕴含着我们的数学思想在里面。
参考文章:
1、https://blog.csdn.net/u010164190/article/details/81043856
2、https://zhuanlan.zhihu.com/p/26614750
3、https://blog.csdn.net/u011508640/article/details/72815981
4、https://blog.csdn.net/zouxy09/article/details/8537620(从最大似然到EM算法浅解)