全卷积神经网络FCN
卷积神经网络(CNN)介绍
传统CNN的强大之处就在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征:较浅的卷积层感知域较小,学习到一些局部特征;较深的卷积层感知域较大,能够学习到更加抽象的特征。这些抽象特征对物体的方向、大小、位置等敏感性更低,从而有助于识别性能的提高。
缺点:抽象的特征对分类很有帮助,可以判断出一幅图像中的物体属于哪一类。但由于抽象特征丢失了物体的一些细节,不能很好地给出物体的具体轮廓,无法指出每个像素具体属于哪个物体,因此做到精确的分割就很有难度。
全卷积神经网络(FCN)的提出
提出目标:从图像级别的分类进一步延展到像素级别的分类(即:从单目标分类变成多目标分类)
最开始的应用:图像分割
贡献:端到端、像素到像素、输入尺寸与输出尺寸一样大小
- 网络模型设计
网络模型
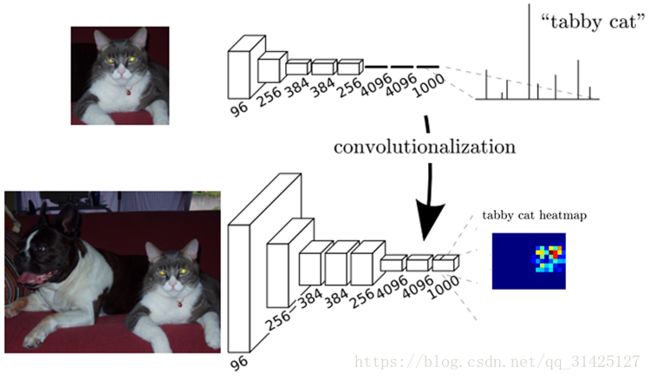
上幅图片中的第一个模型是AlexNet,第一次经过卷积池化后图片尺寸变小为输入的1/2,通道数变成96;第二次卷积池化后图片尺寸再一次变小为输入的1/4,通道数变成256;第三次、第四次……;第六次为全连接层,经过多次卷积后,将特征图的权值展开为1维与全连接的权值实现全连接,变成向量4096x1;最后使用softmax输出类别,因为标签有1000个类别,所以最后输出大小必须为1000x1,与标签相对应,以便做误差损失回传更新网络参数。
第二个模型就是FCN,前面的卷积层与AlexNet一样,区别就在于全连接层,FCN把全连接层全部替换成卷积层:
- 针对第一个连接区域是[7x7x512]的全连接层,令其滤波器尺寸为F=7,这样输出数据体就为[1x1x4096]了。
- 针对第二个全连接层,令其滤波器尺寸为F=1,这样输出数据体为[1x1x4096]。
- 对最后一个全连接层也做类似的,令其F=1,最终输出为[1x1x1000]
最后一层的1000可改,根据不同数据集的类别作相应修改。
二者区别:
(由单一分类到多分类,由粗糙分类到精细分类)
AlexNet的输出是一个1000维的向量,哪个值高代表输入图片属于该值对应的类别,它实现的是单一类别图片分类的功能。
FCN的输出是一个和输入同样大小的图片,FCN能判断输入图片中的物体有哪几类并把他们正确分类,它实现的是多类别图片归类的功能。
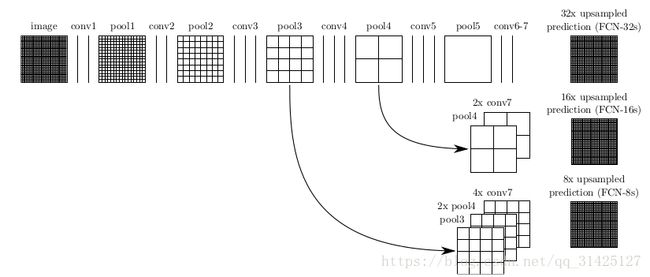
对原图像进行卷积conv1、pool1后原图像缩小为1/2;之后对图像进行第二次conv2、pool2后图像缩小为1/4;接着继续对图像进行第三次卷积操作conv3、pool3缩小为原图像的1/8,此时保留pool3的featureMap;接着继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的featureMap;最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32,然后把原来CNN操作中的全连接变成卷积操作conv6、conv7,图像的featureMap数量改变但是图像大小依然为原图的1/32
那么图1和图2有什么关系呢?
图1结构的代码:
# the base net
n.conv1_1, n.relu1_1 = conv_relu(n.data, 64, pad=100)
n.conv1_2, n.relu1_2 = conv_relu(n.relu1_1, 64)
n.pool1 = max_pool(n.relu1_2)
n.conv2_1, n.relu2_1 = conv_relu(n.pool1, 128)
n.conv2_2, n.relu2_2 = conv_relu(n.relu2_1, 128)
n.pool2 = max_pool(n.relu2_2)
n.conv3_1, n.relu3_1 = conv_relu(n.pool2, 256)
n.conv3_2, n.relu3_2 = conv_relu(n.relu3_1, 256)
n.conv3_3, n.relu3_3 = conv_relu(n.relu3_2, 256)
n.pool3 = max_pool(n.relu3_3)
n.conv4_1, n.relu4_1 = conv_relu(n.pool3, 512)
n.conv4_2, n.relu4_2 = conv_relu(n.relu4_1, 512)
n.conv4_3, n.relu4_3 = conv_relu(n.relu4_2, 512)
n.pool4 = max_pool(n.relu4_3)
n.conv5_1, n.relu5_1 = conv_relu(n.pool4, 512)
n.conv5_2, n.relu5_2 = conv_relu(n.relu5_1, 512)
n.conv5_3, n.relu5_3 = conv_relu(n.relu5_2, 512)
n.pool5 = max_pool(n.relu5_3)
# fully conv
n.fc6, n.relu6 = conv_relu(n.pool5, 4096, ks=7, pad=0)
n.drop6 = L.Dropout(n.relu6, dropout_ratio=0.5, in_place=True)
n.fc7, n.relu7 = conv_relu(n.drop6, 4096, ks=1, pad=0)
n.drop7 = L.Dropout(n.relu7, dropout_ratio=0.5, in_place=True)
n.score_fr = L.Convolution(n.drop7, num_output=21, kernel_size=1, pad=0,
param=[dict(lr_mult=1, decay_mult=1), dict(lr_mult=2, decay_mult=0)])
在图1后加一个上采样层就是模型FCN-32s:
n.upscore2 =L.Deconvolution(n.score_fr,convolution_param=dict(num_output=21, kernel_size=4, stride=2,bias_term=False),param=[dict(lr_mult=0)])对pooling4进行融合上采样就是模型FCN-16s:
n.score_pool4 = L.Convolution(n.pool4, num_output=21, kernel_size=1, pad=0,param=[dict(lr_mult=1, decay_mult=1), dict(lr_mult=2, decay_mult=0)])
n.score_pool4c = crop(n.score_pool4, n.upscore2)
n.fuse_pool4 = L.Eltwise(n.upscore2, n.score_pool4c,operation=P.Eltwise.SUM)
n.upscore_pool4 = L.Deconvolution(n.fuse_pool4,convolution_param=dict(num_output=21, kernel_size=4, stride=2,bias_term=False),param=[dict(lr_mult=0)])对pooling3进行融合上采样就是模型FCN-8s:
n.score_pool3 = L.Convolution(n.pool3, num_output=21, kernel_size=1, pad=0,param=[dict(lr_mult=1, decay_mult=1), dict(lr_mult=2,decay_mult=0)])
n.score_pool3c = crop(n.score_pool3, n.upscore_pool4)
n.fuse_pool3 = L.Eltwise(n.upscore_pool4, n.score_pool3c,operation=P.Eltwise.SUM)
n.upscore8 = L.Deconvolution(n.fuse_pool3,convolution_param=dict(num_output=21, kernel_size=16, stride=8,bias_term=False),param=[dict(lr_mult=0)])注意:这里融合上采样的步骤还是很有新意的!
- 优点与不足
1)得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。
2)对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。
官方论文代码:
https://github.com/shelhamer/fcn.berkeleyvision.org
推荐个使用自己的数据训练模型的文章:
https://www.jianshu.com/p/dfcce14c5018
这里有篇博文图画的不错:
https://blog.csdn.net/fate_fjh/article/details/53446630
但是这里有个地方我觉得解释的和原文的官方代码不一样,就是最后融合上采样的步骤与官方论文代码不一样,有待后期讨论!