Code::Blocks 中文乱码问题原因分析和解决方法
实验环境使用的IDE版本是Code::Blocks 12.11
Welcome to Code::Blocks 12.11!
今天安装好之后,写了如下几句简单代码:
#include
int
main() {
std::cout << “你好” << std::endl;
return 0;
} 编译执行结果如下图所示:

竟然出现中文乱码, 很是郁闷,于是google了一把
要解决这个问题,先要搞清楚有三个地方涉及到编码问题。
第一、Code::Blocks 编辑器保存源文件用的编码。
默认情况下,是保存为windows本地编码的,也就是WINDOWS-936字符集,也就是中文简体 Windows 系统使用的GBK编码。
但是,GCC编译器默认编译的时候是按照UTF-8解析的。如果你把源文件保存成GBK,但是GCC却把它当成UTF-8解析,这怎么能编译通过呢? 所以这两个地方编码不统一好,编译的时候报错:error: converting to execution character set: Illegal byte sequence,你根本连通过编译的可能性都没有!

其实要解决这个问题很简单,编写Code::Blocks的人只需要在调用编译器之前检测一下源文件是什么编码,然后就自动让编译器用什么编码进行解释,问题就解决了。只是很可惜,Code::Blocks编写的人可能还没有这么做,或许是对本地化认识不够吧,也可能是觉得没必要吧?
第二、GCC编译器编译的时候对输入的源文件解释用的编码
这个编译器可以设置-finput-charset=charset来指定编译器用什么编码解释输入源文件。比如如果源文件的字符集是GBk,那么就必须指定-finput-charset=GBK,如果不指定,一律当做UTF-8处理。
Code::Blocks 编辑器默认内码就是 WINDOWS-936,然后我们还要把 GCC 编译器设置,让它编译的时候,自动帮我们加入一些参数。Code::Blocks 只是一个IDE,实际还是调用 GCC编译器编译的,如果我们设置 -finput-charset 以及 -fexec -charset 选项,它自动会帮我们编译时自动添加参数如下
g++.exe -fexec-charset=GBK -finput-charset=UTF-8 -c D:\programming\oj\main.cpp -o obj\Release\main.o
g++.exe -o bin\Release\11.exe obj\Release\main.o -s除非你源文件真的是UTF-8,否则就会出现转换错误。
第三、编译好的执行文件所用编码
如果你在第一和第二两个地方的编码都能统一,那么编译时不会报错了,但是编译好了,运行一下看看,在控制台显示的依然是乱码!
那是因为控制台显示的时候缺省的是使用系统默认的字符集,比如windows下用的是GBK,但是默认情况下,编译之后的执行文件时编译成UTF-8的,所以又出现了不统一,乱码由此而生!
解决的方法和简单,就是给编译器加上选项:-fexec-charset=GBK,和windows默认的统一,就OK了。
搞懂了乱码产生的原因,那么不难得出结论,如何修改,你想修改成什么都OK,关键是要统一,并不是像网上一些人说的,修改成GBK就OK,其实你要修改成UTF-8都OK,关键是统一。
下面说说设置和修改的地方。
第一、如果所用的 IDE 是 Code::Blocks ,可以选择源代码的内码,如下图,Windows-936 就是 中文简体 Windows 系统用的 GBK。
修改源文件保存编码在:settings->Editor->gernal settings -> Other settings 看到下边的Encoding 了吗?如下图所示:
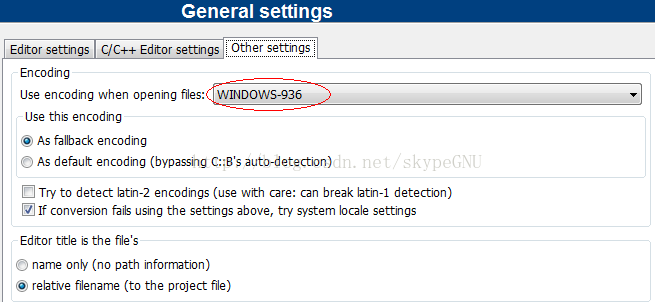
Use encoding when opening files: 这个表示打开文件用的格式,第一次保存文件的时候也会用这个格式。
As default encoding: 表示设置为文件缺省保存和打开编码格式
注意,要先设置好,然后保存文件,才有效。如果你已经保存了文件,无论你怎么修改这个设置,也不会改变你文件的格式了。你的文件还是保持第一次保存的时候的格式。所以,如果遇到无法生效,只能先设置好格式,再重新建文件了。
第二、修改编译器对源文件解释编码格式和生成执行文件执行时候采用的编码格式
是在settings->compiler and debugger settings里面,选择对应的GCC编译器,如下图所示:

在Other options里面加入:
-finput-charset=charset
-fexec-charset=charset
第一个参数表示编译的时候输入文件的编码解释格式,第二参数表示生成的执行文件执行的时候显示用的编码格式。这些参数如果和实际不吻合,必然产生乱码。只要吻合,就不会乱码了。
由于我的源文件格式是WINDOWS-936,但是这里设置成UTF-8,所以编译肯定报错!
只需要修改成-finput-charset=WINDOWS-936或者GBk,就编译通过了。如果不设置fexec-charset默认会认为执行环境是UTF-8,而windows下并不是,所以Linux下没问题,因为Linux就是UTF-8的,但是windows 下必然出现乱码。所以设置成GBk,就统一了。
网络上UTF-8 差不多已经统一天下了, 如果本地是GBK内码,上传到google的git服务器上,在线看就乱码。还有就是 Linux下默认是 Utf-8,GBK在Linux上显示也是乱码,所以,源代码最好是 UTF-8格式。
一切都那么简单,其实,只是因为编程的人做的不够完善,所以才会给使用的人带来困扰。希望这篇文章能帮到一些初学者。或者遇到同样问题的人。
参考:(写得非常好)
http://blog.csdn.net/softman11/article/details/6121538