Spring Cloud微服务篇
第二章 SpringCloud篇
Spring Cloud是一个基于Spring Boot实现的云原生应用开发工具,它为基于JVM的云原生应用开发中涉及的配置管理、服务发现、熔断器、智能路由、微代理、控制总线、分布式会话和集群状态管理等操作提供了一种简单的开发方式。
Ribbon、Zuul、Config分别负责spring cloud项目的负载均衡、网关和统一配置
ELK(elasticsearch、logstash、kibana) + kafka来搭建一个日志系统
Elasticsearch是分布式搜索引擎。
mycat是分布式数据库中间件。
JMeter是Apache组织开发的基于Java的压力测试工具,高并发测试和代码规范性测试
Eureka 是Netflix 出品的用于实现服务注册和发现的工具。 Spring Cloud 集成了 Eureka,并提供了开箱即用的支持
Hystrix是一个库,通过添加延迟容忍和容错逻辑,帮助你控制这些分布式服务之间的交互
Ribbon简介1. 负载均衡框架,支持可插拔式的负载均衡规则2. 支持多种协议,如HTTP、UDP等3. 提供负载均衡客户端
zuul 是netflix开源的一个API Gateway 服务器, 本质上是一个web servlet应用。 Zuul 在云平台上提供动态路由,监控,弹性,安全等边缘服务的框架。
Feign接口调用
Sonar Qube代码检测(代码质量管理平台)
sleuth是微服务追踪:随着微服务数量不断增长,需要跟踪一个请求从一个微服务到下一个微服务的传播过程,Spring Cloud Sleuth 正是解决这个问题,它在日志中引入唯一ID,以保证微服务调用之间的一致性,这样你就能跟踪某个请求是如何从一个微服务传递到下一个。
2.1 实战大觅网–微服务架构简介
一个抢票网站

VUE是前端的一个渐进式的javascript框架
使用的技术:

私服仓库:Nexus(读音/neksers/)
项目管理中使用高效的敏捷开发、git版本管理、sonar Qube代码检测(代码质量管理平台)
敏捷管理工具Scrum(jira也是基于scrum)
用rabbitMQ实现分布式事务,完美解决高并发问题;
发布采用jenkins+docker进行CI/CD的自动化运维部署,以实现Devops的先进理念






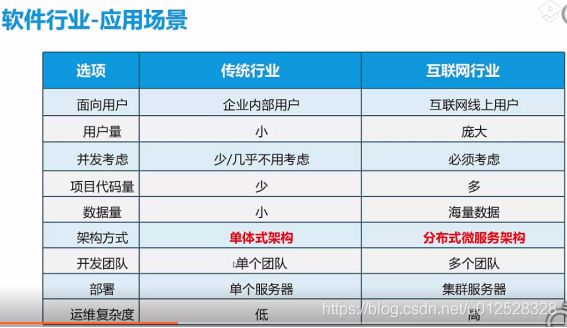

当前很多企业已经逐渐把duboo框架替换成spring cloud框架!!!
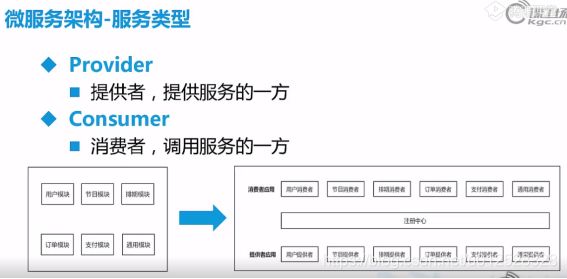

平台无关的话可以用不同编程语言也可以
dubbox在当当网的改进下也支持restful。

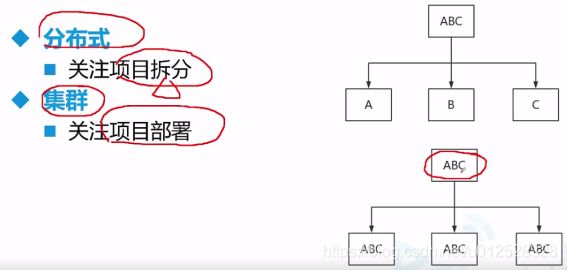

 Eureka是注册中心,消费应用(consumer)和服务应用(provider)都去它那儿注册
Eureka是注册中心,消费应用(consumer)和服务应用(provider)都去它那儿注册
Sleuth是微服务追踪,每隔固定时间去看一下谁调用了谁
Hystrix是容错处理,服务调用失败了该给用户什么样的反馈
Config对整个项目进行统一配置

Feign([fein])接口管理
Ribbon([ˈrɪbən])负载均衡
Eureka([juˈrikə])注册中心
jenkins是管发布的,只需要点一个按钮就可以发布。


敏捷管理是一种团队的管理方式

像svn这种集中式版本控制系统就没有中间这些本地版本服务器
而git这种属于分布式版本控制系统,目前国内外比较主流的就是用git
一旦中央版本服务器挂了,本地版本还在,可以对其修复。


findbugs是sonar的子集,在sonar平台中可以直接导入findbugs的规则集。sonar比findbugs高了一个层级,多出了sonar不仅关注了常规静态bug,还关注到了如代码质量、包与包,类与类之间的依赖情况、代码耦合情况、类,方法。文件的复杂度、代码中是否包含大量复制粘贴的代码是质量低下的,关注到了项目代码整体的健康情况。不过个人在使用过程中findbugs本身的规则比sonar的官方规则更加实用,high级别的bug都是较为实用的bug,且能覆盖到一些性能方面的问题,sonar的规则,50%bug都是主要级别,其实危害不大。前期轻量级的静态bugs扫描可以选用findbugs,当项目持续稳定后可以选用sonar进行更深层次的代码质量控制


 比如说Product Backlog有十个任务,通过Sprint Planning开会讨论分成阶段性的小任务,比如这周先做两个(Sprint Backlog),然后scrum团队里的每个人就来认领这些小人物,通过Daily Scrum(站例会)的方式,每天汇报你做了什么,遇到什么问题。Sprint Review就是检查代码,评审代码,比如每隔一周领导来检查一下你的代码。如果没问题,就提到increment,也就是增加了一个功能。Sprint Retrospective就是进行一次回顾和总结。
比如说Product Backlog有十个任务,通过Sprint Planning开会讨论分成阶段性的小任务,比如这周先做两个(Sprint Backlog),然后scrum团队里的每个人就来认领这些小人物,通过Daily Scrum(站例会)的方式,每天汇报你做了什么,遇到什么问题。Sprint Review就是检查代码,评审代码,比如每隔一周领导来检查一下你的代码。如果没问题,就提到increment,也就是增加了一个功能。Sprint Retrospective就是进行一次回顾和总结。
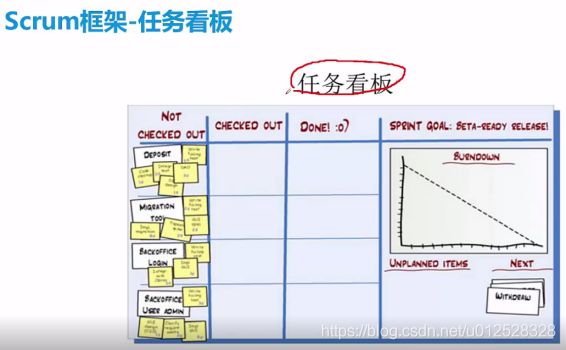
没认领的,已经认领的,已经完成的,一般还有延期的,右边是然见图
2.1.1 CI/CD自动化部署
在软件开发中经常会提到 持续集成(Continuous Integration)(CI)和 持续交付(Continuous Delivery)(CD)这几个术语。但它们真正的意思是什么呢?
工厂里的装配线以快速、自动化、可重复的方式从原材料生产出消费品。同样,软件交付管道以快速、自动化和可重复的方式从源代码生成发布版本。如何完成这项工作的总体设计称为“持续交付”(CD)。启动装配线的过程称为“持续集成”(CI)。确保质量的过程称为“持续测试”,将最终产品提供给用户的过程称为“持续部署”。一些专家让这一切简单、顺畅、高效地运行,这些人被称为 运维开发(DevOps)践行者。
“持续”用于描述遵循我在此提到的许多不同流程实践。这并不意味着“一直在运行”,而是“随时可运行”。
2.1.2 DevOps
DevOps(英文Development和Operations的组合)是一组过程、方法与系统的统称,用于促进开发(应用程序/软件工程)、技术运营和质量保障(QA)部门之间的沟通、协作与整合。它的出现是由于软件行业日益清晰地认识到:为了按时交付软件产品和服务,开发和运营工作必须紧密合作。
2.2 实战大觅网–Eureka、Feign、Hystrix组件的使用



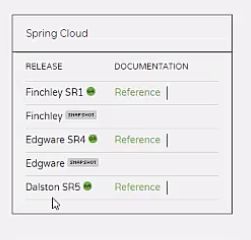
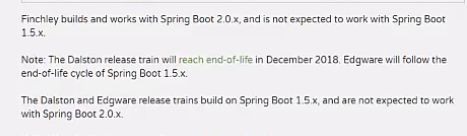
 springcloud的版本以伦敦地铁站名字命名,从A-Z,这里到了F了,项目里用的Dalston.SR4,兼容springboot版本为1.5.6.RELEASE。
springcloud的版本以伦敦地铁站名字命名,从A-Z,这里到了F了,项目里用的Dalston.SR4,兼容springboot版本为1.5.6.RELEASE。

2.2.1 Eureka注册中心

Eureka Server是注册中心;Eureka Client是注册进来的哪些服务。
写Eureka server代码了:

本地主代码dm-eureka-server


想给管理界面加个密码限制:

启动类关键注解:

管理界面地址:http://localhost:7776/
自我保护可以开启和关闭,这里我关闭了:理由是开发测试环境关闭,生产环境开启

这是管理界面式样:

2.2.2 Eureka客户端
provider
本地主代码:dm-user-provider

主要依赖:

接口功能提供:

consume
本地主代码:dm-user-consumer
启动注解:

使用Feign来调用provider的接口,它干了dubbo干的事,很牛,就这个Feign
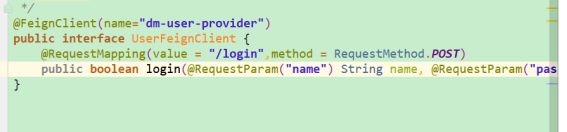
后面写一个controller掉UserFeignClient这个接口就行了。

用postman调都没问题的,这里都是用的post请求
common
本地主代码:dm-common-model
公共基础类,里面有个User的javabean,别人要使用就引用dm-common-model依赖,
com.example
dm-common-model
1.0-SNAPSHOT
最后搞好了用lifeCycle里的install就到把jar包放到本地了,别人就可以添加这个依赖了
比如说provider想用这个User,就加入上面的依赖,
为了方便部署到docker,这里我不想用这个外部的公共模块,知道就可以,这里我把它放到provider和consumer的项目里面,省得引入依赖。
这一块相当于我们gserver项目里的zeus那个公共基础包
2.2.3 Hystrix容错处理
Feign组件已经集成了Hystrix,可以直接用
比如说再dm-user-consumer里启用Hystrix的话就在yml文件里开启:

新建一个UserFeignClientFallback类实现UserFeignClient接口

在UserFeignClient接口的注解里加上一个备用选项fallback参数,如此一来,如果
dm-user-provider挂了,就从fallback里面调了,不至于给用户一个异常。

经测试,我关了provider,再用consumer调接口,返回是自定义的fallback,说明Hystrix成功!

2.3 实战大觅网–Ribbon、Zuul、Config组件的使用

2.3.1 Ribbon负载均衡
provider任务繁忙,不堪重负,因此设置多个provicer,负载均衡。
就类似Nginx实现反向代理,里面可以设置权重,做到负载均衡一样。
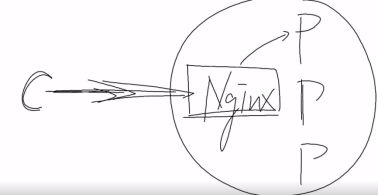
用nginx属于服务端负载均衡策略,就是服务端去想办法。
这里用ribbon属于客户端负载均衡策略,
ribbon也是集成在Eureka里面,直接可以用,开关默认已经启动,直接用。
到这里本地主代码看springcloud-damiwang,我把所有的子模块都放在里面了
只需要再搞一个dm-user-provider2就可以,注册名还是dm-user-provider,注册中心可以看到
再调consumer接口的话,会按1:1的比例分配给这两个provider。
provider日志:

provider2日志:

Ribbon负载均衡就这么简单,都集成在Eureka里,而且默认开启的,直接用就行。
更换负载均衡策略,要在dm-user-consumer也就是客户端来进行yml配置:

如此一来遵循的规则是随机分配了,不再是默认的完全轮流制度。
ribbon源码托管在github上:这里面有很多规则。

2.3.2 Zuul微服务网关
本地主代码:
dm-gateway-zuul
依赖改一下,低版本这样写:




 在
在 浏览器和consumer之间设置一个网关,浏览器想调用consumer的userLogin接口,就通过网关的/user/userLogin来调就行
浏览器和consumer之间设置一个网关,浏览器想调用consumer的userLogin接口,就通过网关的/user/userLogin来调就行

说明网关代理成功,现在加入一些过滤器:
四大类过滤器:PRE、ROUTE、POST、ERROR
分别为:预处理过滤器、路由过滤器、

B为Broser浏览器,U-C为user-consumer

ERROR的话,随时会进入,ERROR处理后还可以有执行POST的机会,也就是ERROR后可以再设置后处理。
下面写过滤器:

 这个RequestContext是zuul里的一个类,它能将上一个过滤器返回的值代到这个过滤器里
这个RequestContext是zuul里的一个类,它能将上一个过滤器返回的值代到这个过滤器里
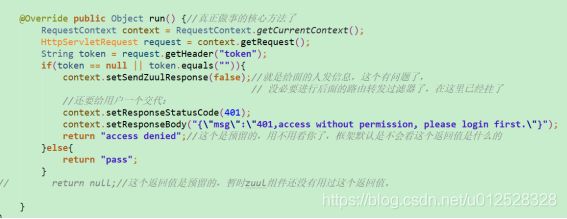
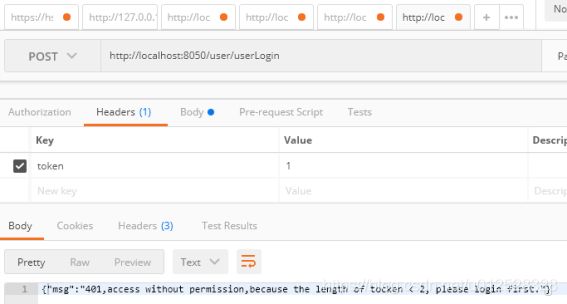
调用时候在header里不放token的话拦截:
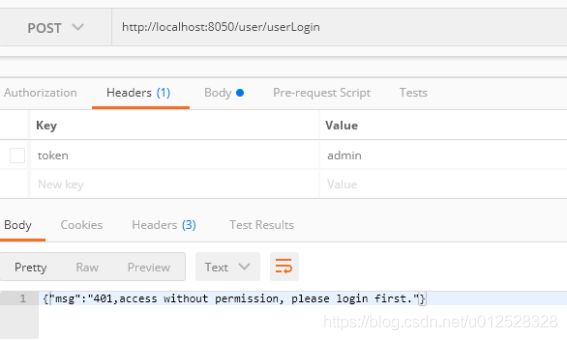
放token的话就可以通过:

再建一个过滤器SecondFilter:


同理建一个ThirdFilter过滤器:

请看效果;
token长度<2会被SecondFilter拦截,>5会被ThirdFilter过滤器拦截。
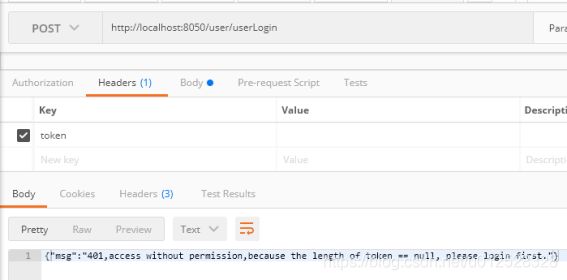


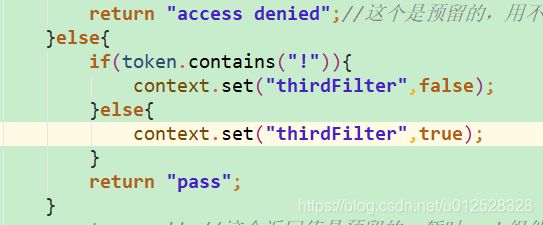
不仅可以如此,过滤器之间的组合非常灵活,比如有一个需求,就是token里如果包含!,那么没有>5的长度限制了,不管多长都别拦截,那么可以这样做:
在PreFilter里判断,如果包含!那么设置一个参数thirdFilter赋值为false。
然后在ThirdFilter里

这个thirdFilter参数一旦为false,那么ThirdFilter这个过滤器不开启,也就是不执行拦截!
还可以在配置文件里关闭一个过滤器:

2.3.3 Config统一配置

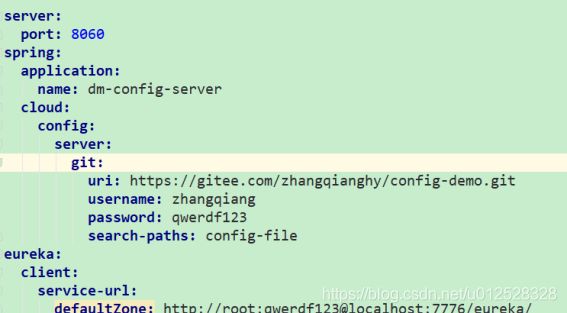
可以建立一个ConfigServer类,去读取git托管的config配置文件,其他的服务项目如果要用到配置信息,就去调用ConfigServer就行了,这些项目就是ConfigClient了
在码云上建一个git

本地主代码:
dm-config-server(未完成,读取码云上的git文件失败,有时间再弄)

2.4 实战大觅网–Docker+Jenkins实现CI


在这里我部署docker的可视化工具shipyard:
需要这些镜像:

我从163镜像中心拉来:https://c.163.com/hub#/home
然后重命名就是了docker tag 原名 重命名
然后删除原来的docker image rm 原名
运行下面代码:
docker run -ti -d --restart=always --name shipyard-rethinkdb shipyard/rethinkdb;docker run -ti -d -p 4001:4001 -p 7001:7001 --restart=always --name shipyard-discovery microbox/etcd:latest -name discovery;docker run -ti -d -p 2375:2375 --hostname=$HOSTNAME --restart=always --name shipyard-proxy -v /var/run/docker.sock:/var/run/docker.sock -e PORT=2375 shipyard/docker-proxy:latest;docker run -ti -d --restart=always --name shipyard-swarm-manager swarm:latest manage --host tcp://0.0.0.0:3375 etcd://192.168.206.158:4001;docker run -ti -d --restart=always --name shipyard-controller --link shipyard-rethinkdb:rethinkdb --link shipyard-swarm-manager:swarm -p 8070:8080 shipyard/shipyard:latest server -d tcp://swarm:3375
最后访问
http://192.168.206.158:8070/#/login

账号:admin
密码:shipyard

停止所有运行的镜像:
docker stop $(docker ps -aq)
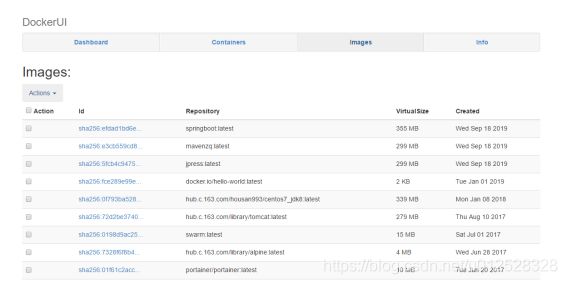
没看到本地镜像和容器内容,我用了dockerui:
docker pull hub.c.163.com/changwenwen/dockerui:latest
docker run -d --name dockerui --restart=always -p 9999:9000 -v /var/run/docker.sock:/docker.sock hub.c.163.com/changwenwen/dockerui:latest
浏览地址:http://192.168.206.158:9001/#/
df -h看内存

2.4.1 Docker-Compose
Docker-Compose项目是Docker官方的开源项目,负责实现对Docker容器集群的快速编排。
Docker-Compose将所管理的容器分为三层,分别是工程(project),服务(service)以及容器(container)。Docker-Compose运行目录下的所有文件(docker-compose.yml,extends文件或环境变量文件等)组成一个工程,若无特殊指定工程名即为当前目录名。一个工程当中可包含多个服务,每个服务中定义了容器运行的镜像,参数,依赖。一个服务当中可包括多个容器实例,Docker-Compose并没有解决负载均衡的问题,因此需要借助其它工具实现服务发现及负载均衡。
Docker-Compose的工程配置文件默认为docker-compose.yml,可通过环境变量COMPOSE_FILE或-f参数自定义配置文件,其定义了多个有依赖关系的服务及每个服务运行的容器。
使用一个Dockerfile模板文件,可以让用户很方便的定义一个单独的应用容器。在工作中,经常会碰到需要多个容器相互配合来完成某项任务的情况。例如要实现一个Web项目,除了Web服务容器本身,往往还需要再加上后端的数据库服务容器,甚至还包括负载均衡容器等。
Compose允许用户通过一个单独的docker-compose.yml模板文件(YAML 格式)来定义一组相关联的应用容器为一个项目(project)。
Docker-Compose项目由Python编写,调用Docker服务提供的API来对容器进行管理。因此,只要所操作的平台支持Docker API,就可以在其上利用Compose来进行编排管理。
安装方法一:
下载Docker-Compose:
sudo curl -L https://github.com/docker/compose/releases/download/1.23.0-rc3/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
安装Docker-Compose:
sudo chmod +x /usr/local/bin/docker-compose
查看版本 :
docker-compose version
安装方法二:
安装pip
yum -y install epel-release
yum -y install python-pip
确认版本
pip --version
更新pip
pip install --upgrade pip
安装docker-compose
pip install docker-compose
查看版本
docker-compose version
安装补全工具:
为了方便输入命令,也可以安装Docker的补全提示工具帮忙快速输入命令:
安装
yum install bash-completion
下载docker-compose脚本
curl -L https://raw.githubusercontent.com/docker/compose/$(docker-compose version --short)/contrib/comple
这里安装使用:
curl -L https://github.com/docker/compose/releases/download/1.25.0-rc2/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose


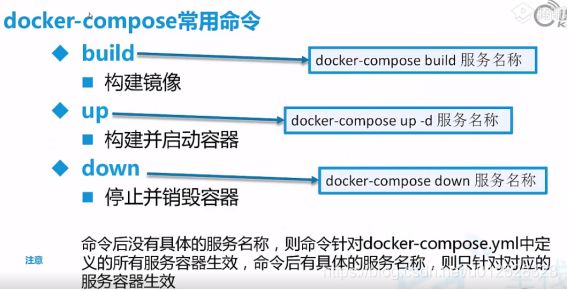
服务名称不加的话,默认构建所有yml文件里的服务
我把所有东西放在/home/docker目录下:
![]()
先pull一个centos,然后分别到centos7、jdk8u151、tomcat7下去执行下面的命令:
docker build -t yi/centos7-ssh .
docker build -t yi/centos7-jdk8u151 .
docker build -t yi/centos7-tomcat7 .
然后到docker-compose.yml文件目录下,执行:
docker-compose build命令,一键建立所需镜像。
发现/home路径不够了,来扩展:从10g扩展到了40g:
https://blog.csdn.net/zcc1229936385/article/details/81737576
https://blog.csdn.net/ctypyb2002/article/details/80883763
然后运行docker-compose build一键搭好:
你看,这么多:

执行docker-compose up 在前台运行,
执行docker-compose up -d在后台运行,
执行docker-compose up -d +服务名 :在后台运行指定服务
然后我把dm-eureka-server、dm-user-provier、dm-user-provicer2、dm-user-comsumer、dm-gateway-zuul通过docker-compose的格式,部署到hub.c.163.com/housan993/centos7_jdk8上面,路径为/home/docker/damiwang
搞定后:

docker-compose down全部停止
2.4.2 jenkins
docker pull hub.c.163.com/library/jenkins
docker run -d -p 8067:8080 -p 50000:50000 -v /home/docker-jenkins:/var/jenkins_home hub.c.163.com/library/jenkins
如果报错
sudo chown -R 1000:1000 /home/docker-jenkins
密码自己找:227ccb1e453c4c6fa3a84a01227bbeb0
输入:http://192.168.206.158:8067/jenkins 浏览jenkins页面
docker exec -it myjenkins /bin/bash没啥用
我在jenkins上创建了用户zhangqiang,qwerdf123
默认还有admin/qwerdf123
流程:先用git在git仓库中下载,然后用jenkins里的maven插件打包,再用ssh发送到远程服务器上,最后用docker部署。
插件下载url设置:
http://mirrors.tuna.tsinghua.edu.cn/jenkins/updates/stable-2.89/update-center.json
https://mirrors.tuna.tsinghua.edu.cn/jenkins/updates/update-center.json
http://mirror.esuni.jp/jenkins/updates/update-center.json
找到之后直接安装,然后重启jenkins就可以了;
重启jenkins可以直接在浏览器地址栏操作:
http://你的ip地址:8067/restart
由于版本为2.60.2,太低了
我又下载了新版本的2.150.3版本的jenkins.war部署到hub.c.163.com/library/tomcat上了
Dockerfile放在/home/docker-jenkins-war路径下。
docker run -d -p 8067:8080 -p 50000:50000 -v /home/docker-jenkins-war:/var/jenkins_home docker-jenkins-war
密码:87c0e68c2c684963b28a5bc23964b539
1、从容器里面拷文件到宿主机?
答:在宿主机里面执行以下命令
docker cp 容器名:要拷贝的文件在容器里面的路径 要拷贝到宿主机的相应路径
示例: 假设容器名为testtomcat,要从容器里面拷贝的文件路为:/usr/local/tomcat/webapps/test/js/test.js, 现在要将test.js从容器里面拷到宿主机的/opt路径下面,那么命令应该怎么写呢?
答案:在宿主机上面执行命令
docker cp testtomcat:/usr/local/tomcat/webapps/test/js/test.js /opt
2、从宿主机拷文件到容器里面
答:在宿主机里面执行如下命令
docker cp 要拷贝的文件路径 容器名:要拷贝到容器里面对应的路径
示例:假设容器名为testtomcat,现在要将宿主机/opt/test.js文件拷贝到容器里面的/usr/local/tomcat/webapps/test/js路径下面,那么命令该怎么写呢?
答案:在宿主机上面执行如下命令
docker cp /opt/test.js testtomcat:/usr/local/tomcat/webapps/test/js

后来我突发奇想,把最新的jenkins.war代替/home/docker/Jenkins里面的jenkins.war,用docker-compose build重新创建,然后docker-compose up -d jenkins
启动,输入http://192.168.206.158:8899/jenkins/
就可以了,决定在这里面运行Jenkins了
但是注意docker-compose down jenkins会把jenkins容器也删除了,下次再启动会丢失配置,所以呢,用docker stop id的方式停止jenkins,千万别删除jenkins容器。
用docker start +id 这个id时jenkins容器,以后这个容器别删除,就放这里,配置不会丢的。切记别把container删除了!!!我可没用数据卷备份哦
2.5 实战大觅网–ELK+Kafka实现日志收集



2.5.1 Sleuth整合Zipkin




本地主代码:dm-sleuth-server

设置端口7700并访问:http://localhost:7700/






2.5.2 Kafka搭建


logstash不仅支持kafka,还支持File、redis\rabbitmq等



 kafka用scala语言写的
kafka用scala语言写的


本地主代码:dm-kafka-client



input{
kafka{
bootstrap_servers => ["192.168.206.158:9092"]
group_id => "test-consumer-group"
auto_offset_reset => "latest"
consumer_threads => 5
decorate_events => true
topics => ["user-consumer"]
type => "bhy"
}
}
output {
elasticsearch{
hosts=> ["192.168.206.158:9200"]
index=> "user-consumer-%{+YYYY.MM.dd}"
user => "elastic"
password => "changeme"
}
}
启动logstash:docker-compose up -d logstash
把配置文件改一下:
docker exec -it (logstash 的启动容器id) bash
cd /user/local/logstash6.几来着
cd bin
vim logstash.conf更改为上面的。
重新启动logstash
再启动elastisearch,
再启动kibana


关闭防火墙用systemctl stop firewalld.service
每次更新elasticsearch项目就docker-compose build elasticsearch
然后docker-compose up -d elasticsearch即可。
想进入docker exec -it ($id) bash
su root
密码是root
现在是
elasticsearch启动报错 CRIT could not write pidfile /usr/local/supervisord.pid
删除空镜像:docker rmi docker images | grep "
后来我实在受不了了,不用docker启动了
在本地直接搭建:
https://blog.csdn.net/select_bin/article/details/83657493
和
https://www.cnblogs.com/yidiandhappy/p/7714481.html
搞定的,
以后启动就这样
到/home/docker/Elasticsearch/elasticsearch-6.2.4/bin下,然后su elsearch
执行:./elasticsearch -d
搞定。

