RT-Thread -双向链表分析
文章目录
- 双向链表的基本概念
- 双向链表的函数接口讲解
-
- rt_list_node结构体
- 常用的宏定义
- 初始化链表 - rt_list_init
- 向链表中插入节点
-
- 向链表指定节点后面插入节点 rt_list_insert_after()
- 向链表指定节点前面插入节点 rt_list_insert_before()
- 从链表删除节点函数 rt_list_remove()
- 链表节点元素访问
双向链表的基本概念
双向链表也叫双链表,是链表的一种,是在操作系统中常用的数据结构,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱,其头指针 head 是唯一确定的。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点,这种数据结构形式使得双向链表在查找时更加方便,特别是大量数据的遍历。由于双向链表具有对称性,能方便地完成各种插入、删除等操作,但需要注意前后方向的操作。
双向链表的函数接口讲解
rt_list_node结构体
/**
* Double List structure
*/
struct rt_list_node
{
struct rt_list_node *next; /**< 指向下一个节点的指针(后驱) */
struct rt_list_node *prev; /**< 指向上一个节点的指针(前驱) */
};
typedef struct rt_list_node rt_list_t; /**< Type for lists. */
常用的宏定义
/* 获取type结构体中member成员在这个结构体中的偏移 */
#define rt_container_of(ptr, type, member) ((type *)((char *)(ptr) - (unsigned long)(&((type *)0)->member)))
/* 初始化链表对象 */
#define RT_LIST_OBJECT_INIT(object) { &(object), &(object) }
/* 获取结构体变量的地址 */
#define rt_list_entry(node, type, member) rt_container_of(node, type, member)
/* 遍历链表 */
#define rt_list_for_each(pos, head) for (pos = (head)->next; pos != (head); pos = pos->next)
/* 安全地遍历链表 */
#define rt_list_for_each_safe(pos, n, head)
/* 循环遍历head链表中每一个pos中的member成员 */
#define rt_list_for_each_entry(pos, head, member)
#define rt_list_for_each_entry_safe(pos, n, head, member)
/* 获取链表中的第一个元素 */
#define rt_list_first_entry(ptr, type, member) rt_list_entry((ptr)->next, type, member)
初始化链表 - rt_list_init
/**
* @brief 初始化链表
*
* @param l 将被初始化的链表
*/
rt_inline void rt_list_init(rt_list_t *l)
{
l->next = l->prev = l;
}
在使用链表的时候必须要进行初始化,将链表的指针指向自己,为以后添加节点做准备 ,链表的数据结构也是需要内存空间的,所以也需要进行内存的申请.

描述:其初始化完成后可以检查一下链表初始化是否成功,判断链表是不是空的就行了,因为初始化完成的时候,链表肯定是空的,注意,在初始化链表的时候其实链表就是链表头,需要申请内存
向链表中插入节点
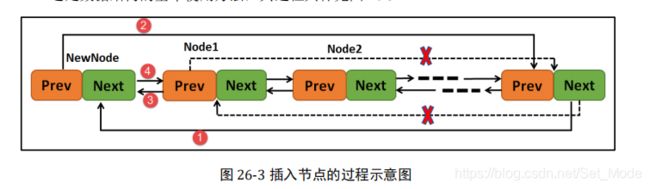
向链表指定节点后面插入节点 rt_list_insert_after()
rt_inline void rt_list_insert_after (rt_list_t *l, rt_list_t *n)
/**
* @brief insert a node after a list
*
* @param l 操作的链表
* @param n 将要被插入的新节点
*/
rt_inline void rt_list_insert_after(rt_list_t *l, rt_list_t *n)
{
l->next->prev = n; /* 1、先改变节点l的下个一个节点的前驱指向节点n */
n->next = l->next; /* 2、再将新节点n的后驱指向节点l的下个节点。 */
l->next = n; /* 3、将l的后驱指向节点n */
n->prev = l; /*4、将节点n的前驱指向节点l/*
}

向链表指定节点前面插入节点 rt_list_insert_before()
rt_inline void rt_list_insert_before (rt_list_t *l, rt_list_t *n)
/**
* @brief insert a node before a list
*
* @param n 将要被插入的新节点
* @param l 操作链表
*/
rt_inline void rt_list_insert_before(rt_list_t *l, rt_list_t *n)
{
l->prev->next = n; /*1:先改变节点l的上一个节点的后驱指向新节点n */
n->prev = l->prev; /*2:再将新节点n的前驱指向l节点的上一个节点。 */
l->prev = n; /*3:将节点l的上一个节点指向节点n */
n->next = l; /*4:将n节点的下一个节点指向节点l*/
}
从链表删除节点函数 rt_list_remove()
删除节点与添加节点一样,其实删除节点更简单,只需要知道删除哪个节点即可,把该节点前后的节点链接起来,那它就删除了,然后该节点的指针指向节点本身即可,不过要注意的是也要讲该节点的内存释放掉,因为该节点是动态分配内存的,否则会导致内存泄漏,
/**
* @brief remove node from list.
* @param n the node to remove from the list.
*/
rt_inline void rt_list_remove(rt_list_t *n)
{
n->next->prev = n->prev; /*1:要移除节点n的上一个节点的后驱指向节点n的上一个节点 */
n->prev->next = n->next; /*2:将要移除节点n的上一个节点的后驱指向n的下一个节点*/
n->next = n->prev = n; /*3:将要移除节点n的后驱指向和n的前驱都指向n*/
}

/**
* @brief tests whether a list is empty
* @param l the list to test.
*/
rt_inline int rt_list_isempty(const rt_list_t *l)
{
return l->next == l; /* 判断节点l的下一个节点是否指向本节点l */
}
/**
* @brief 获取链表长度
* @param l the list to get.
*/
rt_inline unsigned int rt_list_len(const rt_list_t *l)
{
unsigned int len = 0;
const rt_list_t *p = l;
while (p->next != l)
{
p = p->next;
len ++;
}
return len;
}
链表节点元素访问
rt_list_t成员是存放在节点中部或是尾部,不同类型的节点rt_list_t成员位置还不一样,在遍历整个链表时,获得的是后继节点(前驱节点)的rt_list_t成员的地址,那如何根据rt_list_t成员的地址访问节点中其他元素?尽管不同类型节点中rt_list_t成员位置不定,但是在确定类型节点中,rt_list_t成员的偏移是固定的,在获取rt_list_t成员地址的情况下,计算出rt_list_t成员在该节点中的偏移,即(rt_list_t成员地址)-(rt_list_t成员偏移)=节点起始地址。关键在于如何计算不同类型节点中rt_list_t成员偏移。RT-Thread中给出的相应算法如下:
/**
* rt_list_for_each - iterate over a list
* @pos: 指向宿主结构的指针,在for循环中是一个迭代变量
* @head: 链表头
*/
#define rt_list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
/**
* rt_container_of - 就是通过结构体变量中某个成员的首地址进而获得整个结构体变量的首地址
*
*/
#define rt_container_of(ptr, type, member) \
((type *)((char *)(ptr) - (unsigned long)(&((type *)0)->member)))
(1)作用:知道一个结构体中某个元素的指针,反推这个结构体变量的指针。有了rt_container_of宏,我们可以从一个元素的指针得到整个结构体变量的指针,继而得到结构体中其它元素的指针。
(2)type 关键字的作用是:type (a)时由变量a得到a的类型,所以type 的作用就是由变量名得到变量的数据类型。
(3)这个宏的工作原理:先用type 得到member元素的类型,将member成员的指针转成自己类型的指针,然后用这个指针减去该元素相对于整个结构体变量的偏移量之后得到的就是整个结构体变量的首地址了,再把这个地址强制类型转换为type *即可。