java并发编程-计算机硬件基础、缓存一致性协议、线程
一、现代计算机理论模型与工作原理
现代计算机模型是基于-冯诺依曼计算机模型
计算机在运行时,先从内存中取出第一条指令,通过控制器的译码,按指令的要求,从存储器中取出数据进行指定的运算和逻辑操作等加工,然后再按地址把结果送到内存中去。接下来,再取出第二条指令,在控制器的指挥下完成规定操作。依此进行下去。直至遇到停止指令。
程序与数据一样存贮,按程序编排的顺序,一步一步地取出指令,自动地完成指令规定的操作是计算机最基本的工作模型。这一原理最初是由美籍匈牙利数学家冯.诺依曼于1945年提出来的,故称为冯.诺依曼计算机模型。
计算机五大核心组件:
控制器、运算器、存储器、输入、输出
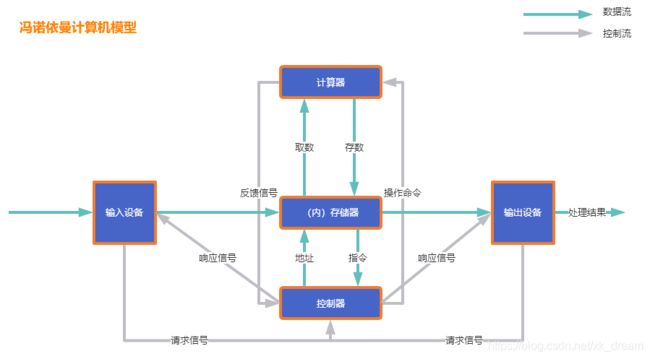
现代计算机硬件基本结构:
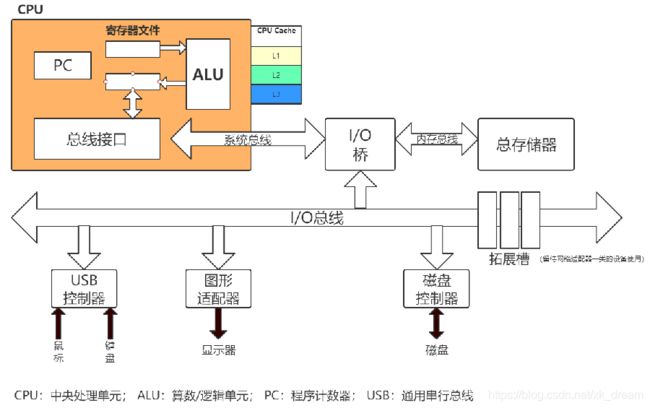
cpu内部结构划分:控制单元、运算单元、内存单元
cpu多核缓存架构:
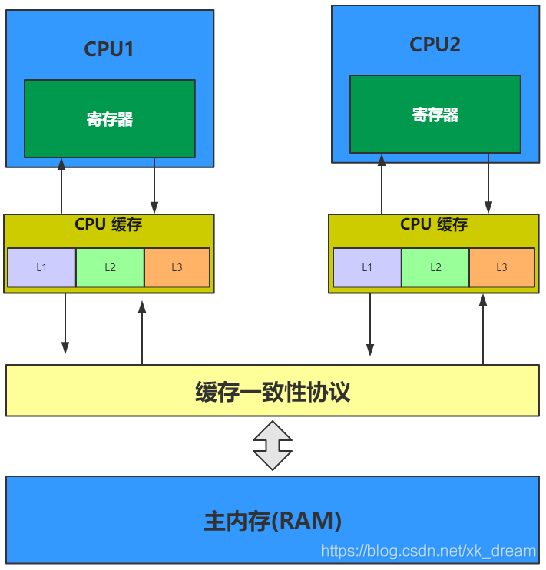
cpu多核:一个现代CPU除了处理器核心之外还包括寄存器、L1L2L3缓存这些存储设备、浮点运算单元、整数运算单元等一些辅助运算设备以及内部总线等。一个多核的CPU也就是一个CPU上有多个处理器核心。
cpu寄存器:每个CPU都包含一系列的寄存器,它们是CPU内内存的基础。CPU在寄存器上执行操作的速度远大于在主存上执行的速度。这是因为CPU访问寄存器的速度远大于主存。
cpu缓存:即高速缓冲存储器,是位于CPU与主内存间的一种容量较小但速度很高的存储器。由于CPU的速度远高于主内存CPU直接从内存中存取数据要等待一定时间周期,Cache中保存着CPU刚用过或循环使用的一部分数据,当CPU再次使用该部分数据时可从Cache中直接调用,减少CPU的等待时间,提高了系统的效率。现在cpu基本都是三级缓存,一级Cache(L1 Cache),二级Cache(L2 Cache),三级Cache(L3 Cache)。
内存:一个计算机还包含一个主存。所有的CPU都可以访问主存。主存通常比CPU中的缓存大得多。
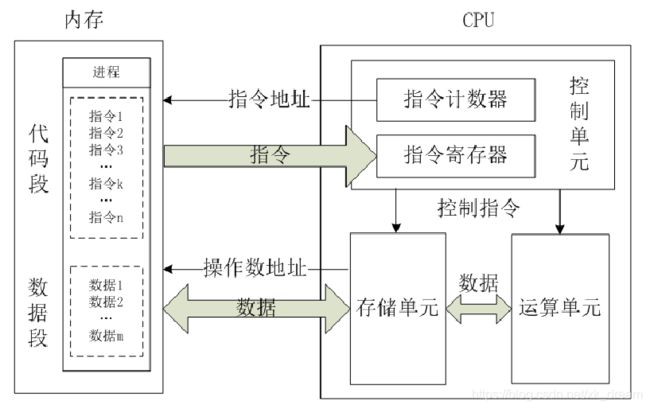
cpu读取存储器数据过程:
cpu读取寄存器中某个变量的值只需一步,直接读取;
cpu读取L1 cache缓存中的数据需要1-3步:把缓存行锁住,把某个数据读取,解锁,如果没锁住就会变慢;
cpu读取L2 cache缓存中的数据:先到L1 cache中取,L1中不存在,再到L2中取,先枷锁,枷锁后把L2中数据复制哦到L1,再执行读L1的过程,也就是上面的散步,再解锁;
cpu读取L3 cache缓存中的数据:先到L1中取,若L1中不存在再到L2中取,若L2中不存在,到L3中取,和上述步骤一样,先加锁,再把L3中数据复制到L2,从L2中再复制到L1,再执行读L1的过程,最后解锁;
cpu读取内存中的数据最:通知内存控制器占用总线带宽,通知内存加锁,发起内存读请求,等待回应,回应数据保存到L3(如果没有就到L2),再从L3/2到L1,再从L1到CPU,之后解除总线锁定。
在多处理器系统中,每个cpu都有自己的缓存,但他们又同享同一个主内存。若cpu1读取变量x=1的数据到内存中,并通过寄存器计算后把x的值改为2,后cpu会把x的数据存在缓存行中,但缓存行汇总的数据并不会马上被刷到主内存中,而是等待到某一个时间点后才会被刷会主内存;在这个过程中若有其他的cpu也读取到x的数据,并对x进行操作,此时的线程并不知道这个数据是否已经被其他线程修改,读取的还是旧数据,这就造成数据不一致,这就是多线程环境下存在的缓存不一致的问题。那么怎么处理这一问题,一种方法是给操作主内存数据的那块内存区域添加总线锁;另一种就是需要各个处理器访问缓存时都遵循一些协议,在读写时要根据协议来进行操作,这就是缓存一致性协议(MESI、MOSI等)。
总线锁效率低,比较消耗性能,最常用的就是MESI协议。
二、缓存一致性协议
缓存行:cpu锁的最小存储单元。
| 状态 | 描述 | 监听任务 |
| M(修改) | 该缓存行有效,数据被修改了。和主内存中的数据不一致,数据只存在本缓存中 | 缓存行必须时刻监听所有试图读该缓存行相对就主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成S(共享)状态之前被延迟执行。 |
| E(独享) | 该缓存航有效,数据和主内存中保持一致,数据只存在该缓存中 | 缓存行也必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成S(共享)状态。 |
| S(共享) | 该缓存航有效,数据和主内存中数据保持一致,数据存在多个缓存中 | 缓存行也必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效(Invalid)。 |
| I(无效) | 该缓存行数据无效 |
接着上面出现的问题,若使用缓存一致性协议会怎样?
假设主内存中存在变量volatile x=1,且此内存区域还没有被cpu访问。此时出现cpu1来读取x的值,由于x的值被volatile修饰,那么x就会遵循MESI协议;x的值经过cpu1缓存后进入cpu1,此时由于只有一个处理器访问,因此此时x的状态为E(独享)状态,并且它会通过总线嗅探机制时刻监听所有试图读取主内存中x数据的操作;如果又存在cpu2把x的数据加载到内存,那么此时x的状态就会改为S(共享)状态,并且cpu2中也会存在总线嗅探机制时刻监听主内存x的区域;若cpu1把x的数据更该为2,并返回到cpu1的缓存中,此时cpu1中的x的状态改为M(修改)状态,并通过协议通知其他cpu更改其缓存中x的状态为I(无效)状态后,cpu1中x的状态改为E(独享)状态;其他cpu中x的数据已为无效状态,若想操作x的数据,就需重新读取主内存。
那么会不会存在一种情况,两个cou同时把x的状态更改为M(修改)状态呢?
答案肯定是不会的,若出现这种状况,那么就会出现一个裁判进行裁决,只会有一个可以成功操作。
那么只要被volatile修饰的变量都能通过MESI协议来保证缓存一致性吗?
答案是不能,因为要想保证缓存一致性,就必须保证其一致性、有序性(指令重排)、可见性;volatile只能保证其可见性和有序性,但不能保证其一致性。还是上面的问题,若cpu1中x的数据改为2,其他cpu中缓存中的x的数据无效,但是此刻有线程要对其缓存中的x的数据操作,发现其无效后,就需重新去主内存中读取到缓存中,但在这个时间里,cpu1中x的新值还没有到主内存中,那么cpu2读取的值任然是旧值。
缓存行的失效问题:
1、MESI协议是锁住缓存行的,若x的存储长达大于一个缓存行,MESI协议就没法锁住,此时需要加总线锁;
2、cpu不支持缓存一致性协议;
三、线程
线程:现代操作系统在运行一个程序时,会为其创建一个进程。例如,启动一个Java程序,操作系统就会创建一个Java进程。现代操作系统调度CPU的最小单元是线程,也叫轻量级进程(Light Weight Process),在一个进程里可以创建多个线程,这些程都拥有各自的计数器、堆栈和局部变量等属性,并且能够访问共享的内存变量。处理器在这些线程上高速切换,让使用者感觉到这些线程在同时执行。
线程可分为:用户级线程和内核级线程。
专业术语:
在理解线程分类之前我们需要先了解系统的用户空间与内核空间两个概念,以4G大小的内存空间为例:
Linux为内核代码和数据结构预留了几个页框,这些页永远不会被转出到磁盘0x00000000 到 0xc0000000(PAGE_OFFSET) 的线性地址可由用户代码 和 内核代码进行引用(即用户空间)。从0xc0000000(PAGE_OFFSET)到 0xFFFFFFFFF的线性地址只能由内核代码进行访问(即内核空间)。内核代码及其数据结构都必须位于这 1 GB的地址空间中,但是对于此地址空间而言,更大的消费者是物理地址的虚拟映射。
这意味着在 4 GB 的内存空间中,只有 3 GB 可以用于用户应用程序。一个进程只能运行在用户方式(usermode)或内核方式(kernelmode)下。用户程序运行在用户方式下,而系统调用运行在内核方式下。在这两种方式下所用的堆栈不一样:用户方式下用的是一般的堆栈,而内核方式下用的是固定大小的堆栈(一般为一个内存页的大小)每个进程都有自己的 3 G 用户空间,它们共享1GB的内核空间。当一个进程从用户空间进入内核空间时,它就不再有自己的进程空间了。这也就是为什么我们经常说线程上下文切换会涉及到用户态到内核态的切换原因所在。
用户线程:指不需要内核支持而在用户程序中实现的线程,其不依赖于操作系统核心,应用进程利用线程库提供创建、同步、调度和管理线程的函数来控制用户线程。另外,用户线程是由应用进程利用线程库创建和管理,不依赖于操作系统核心。不需要用户态/核心态切换,速度快。操作系统内核不知道多线程的存在,因此一个线程阻塞将使得整个进程(包括它的所
有线程)阻塞。由于这里的处理器时间片分配是以进程为基本单位,所以每个线程执行的时间相对减少。
内核线程: 线程的所有管理操作都是由操作系统内核完成的。内核保存线程的状态和上下文信息,当一个线程执行了引起阻塞的系统调用时,内核可以调度该进程的其他线程执行。在多处理器系统上,内核可以分派属于同一进程的多个线程在多个处理器上运行,提高进程执行的并行度。由于需要内核完成线程的创建、调度和管理,所以和用户级线程相比这些操作要慢得多,但是仍然比进程的创建和管理操作要快。大多数市场上的操作系统,如Windows,Linux等都支持内核级线程。
个人理解:
系统空间可分为用户空间和内核空间;用户空间包括我们安装的各个软件,如播放器,jvm,ps等,他们就是我们所说的进程;系统的核心就是运行在内核空间里的;用户空间是不能随便访问内核空间的,若用户空间的进程想访问内核空间,就必须调用内核空间提供的调用接口才能访问;
jvm必须依赖于内核空间才能调用cpu权限。
当前window系统和linux系统的cpu权限级别基本上是两级Ring0和Ring3;Ring0级别最低,用户空间的级别就是在Ring3级别,若需要cpu创建线程就必须使用Ring0级别,只有内核空间才能调用cpu的Ring0级别。
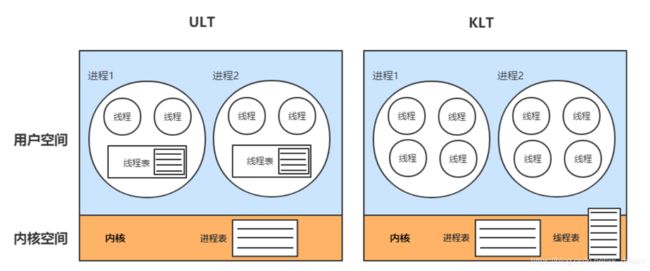
ULT:
若某个进程创建多个线程,就是用户级线程,这些线程是由其进程自己维护的,是属于伪线程;整个主进程还是执行在某个cpu上的,这就意味着若某个线程阻塞,整个进程就会阻塞。
KLT:
内核空间存在一个线程表对应用户空间每个进程线程,此时用户空间进程中的线程可以称为轻量级的进程。
java在1.2版本前用的是ULT,1.2版本后用的是KLT模式。
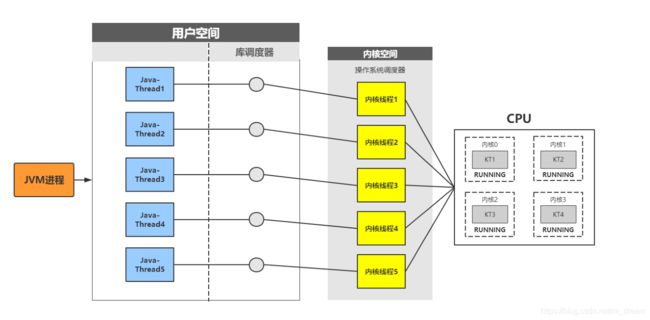
java线程与系统内核线程关系:
四:并发并行
并发:多个任务交替进行。CPU通过给每个线程分配CPU时间片来实现这个机制。时间片是CPU分配给各个线程的时间,因为时间片非常短,所以CPU通过不停地切换线程执行,让我们感觉多个线程是同时执行的,时间片一般是几十毫秒(ms)。
并行:多个任务同时进行,真正的并行也只能出现在拥有多个CPU的系统中。
并发的优点:
1. 充分利用多核CPU的计算能力;
2. 方便进行业务拆分,提升应用性能;
并发产生的问题:
高并发场景下,导致频繁的上下文切换; 临界区线程安全问题,容易出现死锁的,产生死锁就会造成系统功能不可用;
CPU通过时间片分配算法来循环执行任务,当前任务执行一个时间片后会切换到下一个任务。但是,在切换前会保存上一个任务的状态,以便下次切换回这个任务时,可以再加载这个任务的状态。所以任务从保存到再加载的过程就是一次上下文切换。