论文阅读翻译笔记——雅虎S4
目录
2.6.1 简介... 1
2.6.2 设计目标... 1
2.6.3 设计... 2
2.6.3.1 处理单元(PE)... 2
2.6.3.2 处理节点(processing nodes)... 3
2.6.3.3 通讯层... 4
2.6.3.4 配置管理系统... 4
2.6.4 编程模型... 4
2.6.5 参考论文... 5
2.6.1 简介
S4是Simple Scalable Streaming System的简称,正如它的名字,这是一个简单易用、伸缩性强的分布式流式计算框架,S4的高并发基于Actor模型,设计思想基于MapReduce,通过处理单元 (Processing Elements)进行计算,消息在处理单元间以数据事件的形式传送。每个PE的状态对其他PE是隐藏的,PE之间唯一的交互模式就是发出事件和消费事件,框架提供了路由事件到合适的PE和创建新PE实例的能力。
设计这个框架是为了解决使用数据采集和机器学习算法的搜索应用中的现实问题,具体来说,商用搜索引擎是通过广告点击量来盈利的,该计算框架需要解决每秒数千次查询的应用场景下,根据收集到的用户信息进行计算从而得出广告刊登的策略,使用户以更高的可能性点击广告,从而提高企业收益。
在技术层面上,雅虎考虑过使用Hadoop和MapReduce来进行计算,但是Hadoop和MapReduce适用的场景是静态数据和批处理,而非为流式计算所设计的,而设计一个既适合流式计算又适合批处理的系统又太过复杂,所以雅虎决定在MapReduce的基础上设计S4框架,以解决广告业务低延迟、海量数据快速计算、简单易用、高可用性等需求。
2.6.2 设计目标
一、提供一种简单的编程接口来处理数据流。
二、设计一个可以在普通硬件之上可扩展的高可用集群。
三、通过在每个处理节点使用本地内存,避免磁盘 I/O 瓶颈达到最小化延迟。
四、使用一个去中心的,对等架构,所有节点提供相同的功能和职责,没有担负特殊责任的中心节点,以此简化部署和维护。
五、使用可插拔的架构,使设计尽可能的即通用又可定制化。
六、友好的设计理念,易于编程,具有灵活的弹性。
S4系统的设计基于以下假设:
一、故障是可以接受的。在一个服务器故障时,进程自动的转移到稳定的服务器,存储在本地内存中的处理状态在交接中会丢失,系统状态会根据输入数据流重新生成。
二、不会有节点从正在运行的集群中增加或移除。
2.6.3 设计
流被定义为一系列由键值和属性构成的事件。雅虎的目标是设计一个消耗流、计算中间值并有可能发出流的弹性的分布式计算平台。
2.6.3.1 处理单元(PE)
处理单元S4中最基本的计算单元。每个 PE 的实例被四个要素唯一标识:一、由一个 PE 类和相关配置定义的功能。
二、它所消费的事件的类型。
三、这些事件的带键值的属性(keyed attribute)。
四、这些带键值的属性的属性值
每个PE只消费事件类型、属性 key、属性 value 都匹配的事件。它可能会产生输出事件,会为每个属性值初始化一个 PE,实例化由平台进行。有一种特别的不带key的PE,没有属性key和属性value,这种PE消费相关类型的所有事件,无key的PE一般在一个 S4 集群的输入层使用,在这一层事件会被赋予一个key。任务使用一个配置文件来定义。对于有大量唯一key的应用,可能有必要随着时间的推移清除PE对象。最简单的方法可能是给每个PE对象加一个时间戳。如果在一个特定的时间段内没有这个PE相关的事件到达,那就可以清除了。当系统内存回收时,PE对象被清除,其之前的状态也丢失了。这种内存管 理策略比较简单,但是并不高效。为了使服务质量(QoS)最大化,应该在系统可用内存和对象对系统整体性能影响的基础上恰当的清除PE对象,开发者可以对PE 对象设定其优先级或重要性以更好的解决上述问题。
2.6.3.2 处理节点(processing nodes)
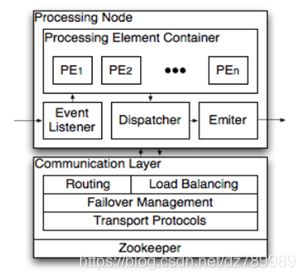
图一、处理节点和通信层
处理节点(PNs)是PE的逻辑主机。它们负责监听事件、在到达事件上执行 操作、通过通讯层的协助分发事件和发出输出事件。S4通过一个哈希函数基于事件中所有的属性值将每个事件路由到 PN上。单个事件可能被路由到多个PN 上。所有可能的属性key的集合通过S4集群的配置获知的。PN中的事件监听器将到来的事件传递给PE容器(PEC),PE容器以适当的顺序调用适当的PE。
有一种特殊的 PE 对象类型,PE原型(PE prototype)。它身份标识由前 3个元素(功能、事件类型、属性 key)组成,属性值是未赋值的。这个对象是在初始化时配置的,对于任何的值V,该对象可以克隆自身以创建与该类配置和key值相同的PE。
以上设计的结果是,所有包含特定属性值的事件保证会到达相应的PN,并被路由到PN内相应的PE上。每个key被赋值(keyed)的PE 能够被映射到一个确定的 PN,映射的规则也是通过基于PE属性值的哈希函数。无键值(keyless)的PE 会在每个PN上被初始化。
2.6.3.3 通讯层
通讯层负责集群管理、自动地使用备用节点进行故障恢复、逻辑节点到物理节点的映射。它会自动检测硬件故障并相应的更新这个映射。发送消息时只指定逻辑节点,发送者不会感知物理节点的存在或故障导致的逻辑节点重映射。通讯层的 API 支出数种语言的,如 java、C++等。遗留系统(legacy system)可以使用通讯层的API以 round-robin 的模式发送输入事件到S4集群中的节点。 通讯层使用一个插件式的架构来选择网络协议,事件可能以可靠或不可靠的方式发送。控制消息可能需要可靠发送,而数据消息可能不需要可靠发送,而是以最大化吞吐量为目标进行不可靠发送。此外,通讯层使用 ZooKeeper在S4集群节点之间进行一致性协作。
2.6.3.4 配置管理系统
管理系统可以使操作者为S4任务创建和销毁集群,并且进行其他的管理操作。分配物理节点到这些 S4 任务集群的操作通过ZooKeeper进行协作。当一个活动(active)节点的集合被分配给特定的任务,剩余的空闲节点仍然留在池中以备需要时使用(例如故障恢复或动态负载均衡)。此外,空闲节点可以被用作多个活动节点的备用节点以分配不同的任务。
2.6.4 编程模型
上层的编程范例是为了编写通用的,可重用的,可配置的跨应用处理单元,。开发者使用Java语言编写PE。使用 spring 框架将PE配置到应用中。
处理单元API具有简单和弹性的特点。开发者本质上只需实现两个主要的 接口:一个是输入事件接口processEvent(),另一个是输出机制的接口output()。 另外开发者可以为PE定义一些状态变量。processEvent()在PE订阅的每个事件到达时被调用。output()方法是可选的,可被配置为以各种方式调用。既可以在特定时间间隔调用,也可以在接收到n个输入事件时调用。output()方法实现 PE 的输出机制,通常是将PE的内部状态发布到一些外部系统。
考虑一个PE订阅了用户搜索查询的事件流的例子,从开始为每个查询实例计数,并间歇性的将计数值写到一个外部存储。事件流由 QueryEvent 类型的事件组成。类 QueryCounterPE实现图二中描述的processEvent()和output()。在这个例子中,queryCount是PE的内部状态变量,负责这个PE对查询的计数。PE 的配置在图三中描述。在这里,属性 keys 告诉我们 QueryCounterPE订阅了一个 QueryEvent类型的事件,并且关注事件的 queryString 属性。配置将 PE和数据处理组件 externalPersister绑定起来,并且构造 output()方法为每 600秒调用一次。

图二、PE输入输出的Java编程接口示例

图三、PE在Spring中的配置文件
2.6.5 参考论文
Neumeyer, Leonardo, et al. "S4: Distributed stream computing platform." 2010 IEEE International Conference on Data Mining Workshops. IEEE, 2010.