redis整合
Redis
是一个基于内存,实现缓存.可持久化,非关系型数据库。(nosql,key-value)
nosql:
不仅支持结构化查询语句--redis存储的数据结构不是表格。
key-value:
redis存储的数据基本结构,value有五种基本数据类型(String,hash,set,list,zset)。
| String |
字符串 |
实现缓存 |
| Hash |
面向对象的结构 |
实现缓存 |
| List |
双向链表 |
头尾操作速度快,中间的操作速度慢,有排序 |
| Set |
集合 |
没有排序,不允许元素重复 |
| ZSet |
有序集合 |
set的基础上进行排序,可以做排行榜系统 |
基于内存:
redis运行运行速度极快,最大支持的上限为万条/秒级,在内存处理数据。
实现缓存:
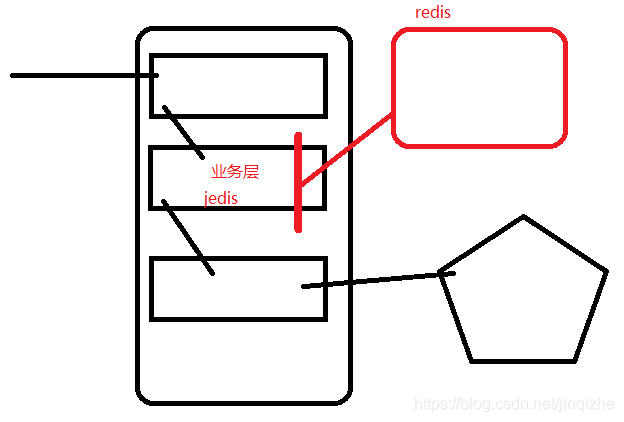
减少调用层次的数量,提升线程的处理速度,系统的并发能力提高。
可持久化:
memoryCache,类似于redis的缓存数据库。
| Redis |
memoryCache |
| 支持五种value |
String |
| 支持持久化(容灾雪崩) |
不支持(容易造成容灾雪崩) |
| redis单实例,单线程 |
memoryCache多线程,少快于redis |
网络访问redis这种技术,瓶颈不是限制在技术端,限制是在网络传输通道上。
雪崩:
如果一个长期运行的系统中,使用redis,缓存数据非常多,如果突然缓存故障(内存数据丢失,down机),导致海量访问的请求涌入数据库,数据库承受不住--宕机--重启,海量的数据请求并未消失,所以在缓存技术数据恢复之前,系统不可用--雪崩(并发请求)。
持久化:
缓存使用数据在内存,为了保证宕机数据不丢失,在运行期间使用持久化机制将内存数据存储在磁盘,可以在技术启动时重新加载磁盘数据。
持久化执行save策略,数据变动(写)越频繁,存储持久化的时间越短。
900秒内,数据至少变动一次。
300秒内,数据至少变动十次。
60秒内,数据至少变动一万次。
redis可以做什么
五种数据类型,可以实现缓存,可以实现分布式内存锁,其他复杂功能(计步器,共同好友,排行榜)。
redis的分布式集群
单机使用的优化:
如果作为redis节点,只在一个服务器启动一个进程,单进程。单进程的软件不足以使用到服务器 的有效资源上限,一般都会在一个服务器中设置3-10个redis节点。不同的redis节点对应不同的持久化文件,数据不互通。
数据在redis中的淘汰策略:
lru:最近最久未使用(热点保留,冷点删除)。
random:对超时的数据随机删除。
ttl:把将要过期的数据删除(剩余时间越少,删除的可能性越大)。
高可用集群:
单节点故障,会导致集群不可用。单点结构不是高可用的,所以要搭建集群。
1.哨兵集群
1.高可用结构:

主从结构的故障转移:主节点故障宕机,从节点顶替。
主从的数据备份:主从关系一旦搭建,从节点时刻备份主节点的数据,高可用的基础。
2.redis的主从数据复制:
reids支持一主多从,支持多级主从。
主从结构过于复杂会导致数据备份的不稳定。
3.实现一主二从结构:
6382为主节点,6383,6384为6382的从节点。
利用>slaveof 主节点ip 主节点端口号。
127.0.0.1:6384> slaveof 10.9.39.13 6382
结论:
主节点,从节点只关心主从的任务,没有故障转移替换机制,高可用单个结构单独使用主从的复制无法完成。
4.哨兵进程:
介绍:
哨兵集群是一个单独的,特殊的redis进程,和redis-server相互独立运行,可以实现对主从结构的监听和管理,实现故障转移的控制。
原理:
监听原理:
初始化时访问主节点,调用info命令从主节点获取所有从节点的信息,维护在内存中进行监控管理,所有节点的状态都会通过哨兵进行维护。
心跳机制:
每秒钟通过rpc(远程通信协议)心跳检测访问集群的所有节点,一旦发现心跳响应是空的,达到一定时间判断节点故障宕机。
投票机制:
主节点宕机,选举一个从节点为新的主节点,通过管理的权限将这个节点的角色转化为master,将其他集群节点挂接到这个新的主节点上,必须通过投票完成(哨兵也是集群),投票的结果必须过半才能执行,否则将会重新判断循环。
5.哨兵集群的分布式结构:
jedis无法实现哨兵的分布式。
hash一致性计算固定(基于它的结构修改hash一致性算法)。
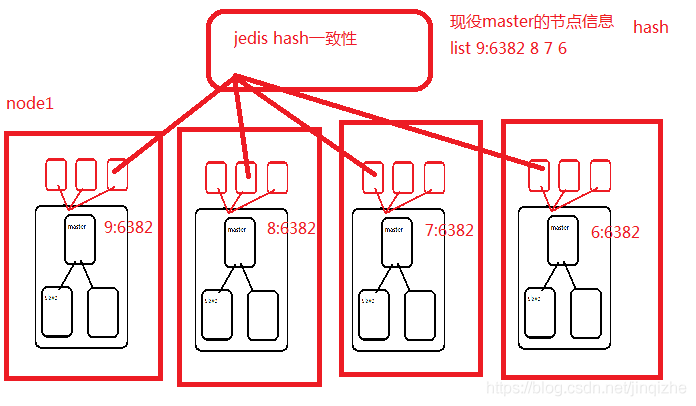
hash取余会导致集群扩容和缩容时数据的迁移量过大,不迁移就会造成数据未命中过大造成雪崩。
而hash一致性算法就解决了hash取余在扩容和缩容时的迁移量过大的问题,hash环实现hash一致性。
hash取余扩容:节点越多迁移量越大。
hash一致性:节点越多迁移量越小,小到一定程度时,这种未命中微不足道。
2.redis-cluster
哨兵集群redis技术中只能解决高可用问题,但是实现分布式比较浪费资源,分布式计算比较复杂,需要根据搭建的结构实现不同的分布式hash一致性的重写过程。
Redis3.0版本redis出现了最终的结构支持高可用分布式同时存在的redis-cluster。
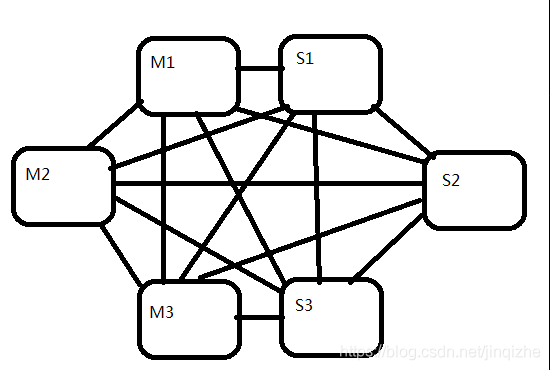
特性:
1.两两互联:
集群中节点与节点,部分角色两两互联,底层内部二进制通信协议,优化传输速度(同步集群相关信息)。
2.哨兵逻辑整合到master:
集群中要求最小的master数量是3,将哨兵的进程逻辑整合到master节点中,集群的高可用监听逻辑由投票过半的master决定。因为有了两两互联,master才能实现互相监听管理。
3.客户端连接一个节点获取集群所有信息:
客户端基于两两互联,实现从一个节点,获取集群的所有节点的内容(jedisCluster的代码高可用)。
4.槽道实现key和节点的松耦合:
hash slot:
redis-cluster集群中有新分片计算的逻辑,hash槽,底层计算(key.CRC16()%16384)key值会对应到一个槽道号[0-16383],master可以管理一批不同的槽道,实现key->slot->node。
槽道使用特性:
客户端连接集群任意一个节点,发送处理数据的命令,会计算key值对应的槽道号,找到管理槽道号的节点,进行通知客户端转发redirect。
持久化方式:
| rdb |
aof |
对比 |
| 记录的数据是key-value name wanglaoshi |
开启的日志文件记录的整个执行的命令 set name wanglaoshi |
运行模式:set name wanglaoshi |
| 比较小 |
比较大 |
文件大小 |
| 单独开启rdb才加载 |
aof优先级比rdb大 |
redis-server加载顺序 |
| 缺点: 会在宕机时造成数据的丢失更多 优点: 批量操作,效率更高,小数据量时使用rdb效率比aop高 2倍以上的效率 |
优点 数据同步时间接近实时(默认每秒同步);数据备份可靠性高,丢失数据少 缺点: 同步的实时性,增加redis-server的压力 |
优点和缺点 |
| 需要一定的数据恢复能力,不要求数据可靠性极强(数据恢复时,越全可靠性越高);数据量不大的情况可以选择rdb |
对数据的可靠性要求极高,可以使用aof,在aof模式下,最多丢失2秒的数据. |
使用场景 |
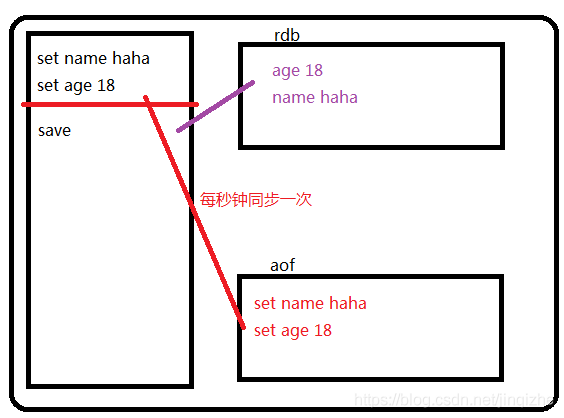
总结:
存储数据结构,rbd存数据,aof日志命令。
优先级加载,aof高(数据恢复更全面)。
使用场景:优缺点,aof可靠性(恢复的约全面,持久化的可靠性越高)高。
槽道原理:
1.集群启动时创建的内存数据:
启动单个节点(相互间谁也不其他人通信)
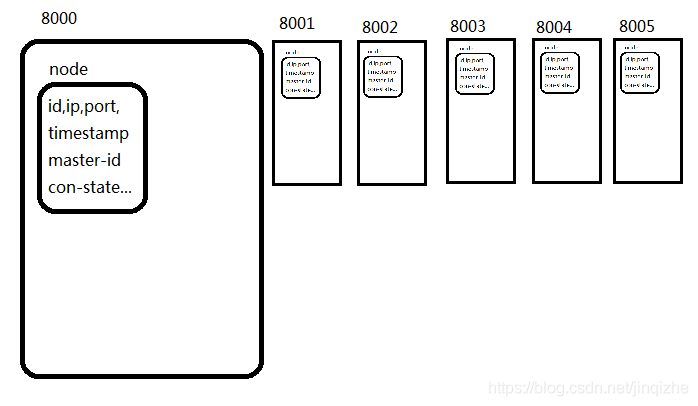
将使用ruby调用create两两通信建立,对象信息相互同步(cluster最大的横向扩展空间1000个节点)。
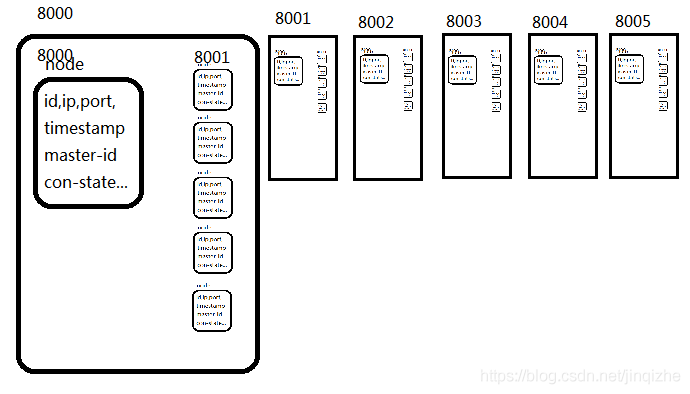
所以集群创建之后,登录任何一个节点后可以通过cluster-nodes查看整个集群所有信息。
2.槽道结构:
集群的槽道结构有2个部分组成。
16384位的二进制(byte[2048]形式驻留在内存)。
16384个元素的数组(数组中保存的是所有节点对象的引用变量)。
在节点计算完key值的取模结果后,使用槽道号判断所属权。
每个节点中,都会管理一个2048个元素的byte数组(16384位的二进制);从头到尾赋予下标概念(位移计算)0-16383,每个下对应一个槽道号,可以利用槽道号从二进制获取下标对应的二进制的值1/0,如果是1,表示当前槽道归属true,0表示不归属false。

当前集群的主节点创建之初的二进制

16384个元素的数据可以记录0-16383下标的元素值,每个下标对应槽道号,每个节点中通过通信获取二进制,整理使用这个数组,每个元素内容,记录了引用当前槽道号管理者的对象数据。
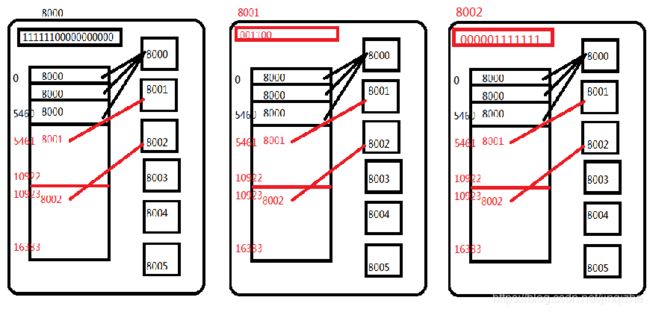
客户端传输命名到节点中,计算分布式hash取模处理
- 客户端连接点发送命令set name haha。
- 8000接收到。
- 计算槽道--5789。
- 二进制判断对应下标值是1/0,false。
- 找到数组拿到5789下标元素,8001节点对象变量引用。
- ip:port返回客户端重定向。
- 8001接受命令set name haha。
- 计算槽道--5789。
- 二进制判断对应下标值是0/1,true。
- redis服务端接收set命令处理。