python:Scrapy框架概述+简单命令
Scrapy是一个适用爬取网站数据、提取结构性数据的应用程序框架,它可以应用在广泛领域:Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
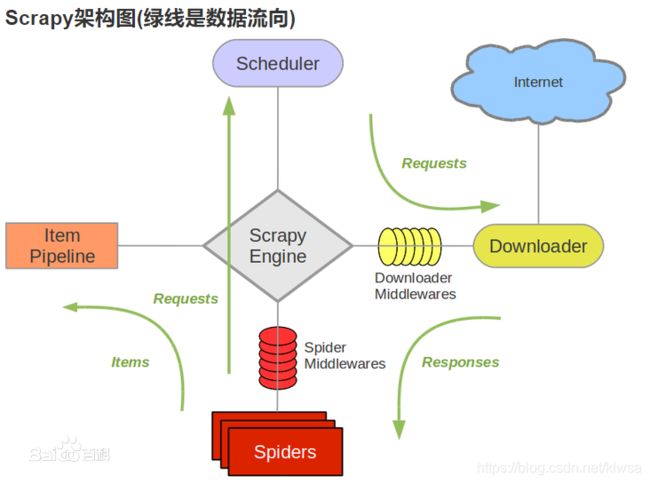
SCrapy为5+2模式,即五个模块,两个中间件。
Scrapy Engine(引擎):最核心的模块。负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。(实质是构造一个消息队列)
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses(回应)交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
Downloader(下载器)需要我们编写的部分:负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
中间件:
Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):一个可以自定扩展和操作引擎和Spider中间通信的功能组件
用scrapy创建一个爬虫项目:
scrapy startproject 项目名称

scrapy shell [可选](需要爬取的地址):
这是一个可交换的shell,支持命令和py内置函数。很适合调试。