生成器、迭代器、可迭代对象三者的联系和区别
生成器、迭代器、可迭代对象的联系和区别
- 可迭代对象
-
- 定义
- 判断
- 迭代器
-
- 概念
- 判断
- 生成器
-
- 概念
- yield关键字
-
- 实例①:
- 实例②:yield生成器实现斐波那契数列
- 实例③:send()方法修改生成器的状态
- 三者的联系与区别:
可迭代对象
定义
凡是实现了__iter__方法的对象都称之为可迭代对象,常见的有:
容器都是可迭代对象
1.list
2.set
3.dict
4.str
5.tuple
其他的:
6.打开状态的files
7.打开状态的sockets等
还有一种说法是,实现了__getitem__方法且__getitem__方法的参数是从0开始的整数。如python中的序列都是
判断
方法①可通过Iterable判断对象是不是可迭代对象
代码如下:
// 定义一个判断是不是迭代对象的函数
from collections.abc import Iterable
def isiterable(iter):
if isinstance(iter,Iterable): #判断q4是不是可迭代对象
print("yes" )
else:
print("no")
#再去调用它
isiterable([1,2,3,4])
isiterable(1)
可以看到结果:

方法②调用iter()方法,将可迭代对象转换成对应的迭代器
如果不可迭代,再处理typeError异常,比方法一更准确,因为iter()会考虑遗留的__getitem__方法,而方法一不会考虑
代码如下:
// An highlighted block
li=[1,2,3,4]
li_it=iter(li)
print(type(li_it))
输出结果为:

可以看到这里 的类型是列表迭代器,因此证明li这个列表是一个可迭代的对象
迭代器
概念
任何实现了__iter__()和__next()__方法的都是迭代器,其中__iter()__实用来返回迭代器本身;__next()__是用来返回迭代对象中的下一个值
注意事项如下:
1.迭代器有具体的迭代器类型,可用type查看,一般有list_iterator,set_iterator等类型
2.迭代器是有状态的,可以被next()调用,并且不断返回迭代对象的下一个值,如果到了迭代器的最后一个元素,继续调用next(),则会抛出stopIteration异常
判断
可用Iterator判断,具体代码如下:
from collections.abc import Iterable,Iterator
def ifiter(ran):
#判断是不是可迭代对象
if isinstance(ran,Iterable):
print(f"{ran}是可迭代的对象")
else:
print(f"{ran}不是可迭代的对象")
#判断是不是迭代器
if isinstance(ran,Iterator):
print(f"{ran}是迭代器")
else:
print(f"{ran}不是迭代器")
ran=range(3)
ifiter(ran)
输出:

生成器
概念
生成器是一种特殊的迭代器,不需要手动的编写__iter()__和__next()__方法,因为yeild关键字已经包含了这两种方法。
注意事项:
1.因为生成器(generator)一定是迭代器,所以生成器也是一种懒加载的模式生成值(即需要用的时候才会生成数据,不需要的时候不会生成)
2生成器可以是生成器表达式也可以是生成器函数
其中生成式表达式,使用()表示,将列表推导式的[]改成()即可得到生成器
生成器函数则调用yield关键字即可。
yield关键字
了解一个东西,首先要知道它的原因,yield关键字产生的原因:
因为yeild自动实现了__iter__和__next__方法,起到简化代码的作用,一般用于大数据,大文件逐个生成的时候,可以大大减少内存的开销。
使用yield时的注意事项:
1.yeild被调用时,返回一个迭代器,调用时可以使用next或send(msg)
2.只要函数内部有yield关键字,就认为该函数是生成器函数
3.一个生成器中可以有多个yield,一旦遇到yield,就会保存当前状态,然后返回yield后面的值
4.当生成器遇到yield时,会暂停运行生成器,返回yield后面的值,当再次调用生成器的时候,会从刚才暂停的地方继续执行,直到下一个yield
5.yield关键字,会保留中间算法,下次继续执行
6.yield是一个函数的返回值,能赋值给变量,会返回None,这是因为yield相当于函数里面的return,但是使用send函数改变生成器状态的时候,一定要先赋值给变量,才能进行状态的改变,否则会报错
估计大家看了这么多的文字会很难理解,下面直接看代码会简单很多。特别是实例2
简单使用yield生成器的代码如下:
实例①:
def get_content():
x=8;
yield x-1
y=6
yield y+2
z=2
yield z
g=get_content()
print(g,type(g))
print(next(g))
print(next(g))
print(next(g))
输出为:

注意,这里最多只能有3个print(next(g))的语句,因为这里只有3个yield,每执行一次yield会返回一次的状态,如果没有状态可以返回,则会报错
如下所示(写了4个print(next(g))语句 ):

yield语句的执行过程我刚开始也很懵,相信大家看完实例2之后会有比较清晰的理解了
实例②:yield生成器实现斐波那契数列
from itertools import islice
def lib():
prev,curr=0,1
i=0;
while True:
i=i+1;
print(f"第一个yield第{i}次前面的curr:", curr)
yield curr
#print("#######################")
print(f"第一个yield第{i}次后面的curr: ",curr);
print(f"第二个yield第{i}次前面的prev: ",prev);
yield prev
print(f"第二个yield第{i}次后面的prev: ", prev);
prev,curr=curr,curr+prev
f=lib()
print(type(f),f)
输出结果为:

因为执行生成器函数时不会执行代码,会首先返回一个generator对象,必须要用next方法来获取其值。
下图是加了1行print(next(g))语句之后的运行图:
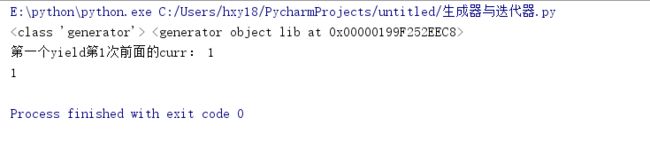
可以看到,程序运行到第一个yield则退出了,所以yield相当于函数里面的return语句,碰到了则退出函数并返回,但是与return不一样的是,yield是有状态的,它会自动保存这一次的位置,下一次next调用,会自动从当前位置开始执行
下图是有2行print(next(f))语句的结果:

可以看到,程序运行到第2个yield就退出运行了
下图是有3行print(next(f))语句的结果:

可以看到,此时yield已全部执行完毕(总共有2个yield,执行了3次next方法,所以,现在程序退出的位置是在第一个yield语句),以此类推。
通过该例子,大致可以总结出以下几点,希望大家能好好理解一下:
①执行生成器函数时不会执行代码,会首先返回一个iterable对象
②只有显示或隐式地调用next的时候才会真正执行函数里面的代码,执行到yield 语句时,lib()函数会返回yield后面的值,并记住当前执行的状态
③下次调用next后,程序会从yield的下一条语句继续执行,看起来就像是一个函数在正常执行的过程中被yield中断了数次,每次中断都会通过yield返回当前的迭代值
④由此看出,生成器通过关键字yield不断的将迭代器返回到内存进行处理,不会一次性的将对象全部放入内存,会节省很多空间
实例③:send()方法修改生成器的状态
def counter(start_at=0):
count=start_at
while True:
val=(yield count)
if val is not None:
count=val
else:
count+=1
count = counter(5)
print(type(count))
print(count.__next__())
print(count.__next__())
print(count.send(9)) #通过val变量改变当前迭代器的状态,从而对其进行修改
print(count.__next__())
print(count.send(100))
print(count.__next__())
count.close()
输出结果为:

注意的是,用close()关闭生成器之后,不能在对其使用next方法,因为此时已经没有生成器了,会报错的
三者的联系与区别:
画图表示如下:
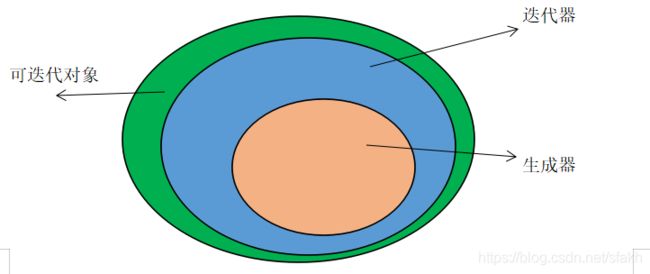
迭代器与可迭代对象:
迭代器都是一个可迭代对象,且所有的Iterable(迭代对象)都可以通过内置函数iter()转变为Iterator(迭代器)
生成器与迭代器:
联系:所有的生成器都是迭代器,有yield的是生成器,因为yield可以是生成器表达式也可以是生成器函数
区别:迭代器用于从集合中取出元素
生成器用于凭空生成元素