SparkStreaming无丢失读取Kafka且转为DataFrame
目录
1、需求
2、步鄹
3、日志格式
4、代码展示
5、运行结果展示
6、Kafka Manager 和 Zookeeper展示
1、需求
1、SparkStreaming读取Kafka数据,且将offset存储到Zookeeper中
2、控制每次读取数据的最大值
3、将读取出来的数据,转为DataFrame
2、步鄹
1、通过zkClient.readData方法读取Zookeeper中TopicName数据的Offset
2、通过ZkUtils.updatePersistentPath方法存取Zookeeper中TopicName数据的Offset
3、通过set(“spark.streaming.kafka.maxRatePerPartition” ,“6”),控制最大为1200条数据
4、通过将使用Case类将Rdd转为DataFrame。
参考:http://spark.apache.org/docs/1.6.1/sql-programming-guide.html#programmatically-specifying-the-schema
3、日志格式
3g.donews.com 123.125.71.39 - - [17/Jan/2017:00:50:44 +0800] "GET /2405707 HTTP/1.1" "http://3g.donews.com/2405707" 302 160 "-" "Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" "-" "China" "22" "Beijing"
3g.donews.com 220.181.108.160 - - [17/Jan/2017:00:50:44 +0800] "GET /News/donews_detail?id=2405707 HTTP/1.1" "http://3g.donews.com/News/donews_detail?id=2405707" 200 970 "-" "Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" "-" "China" "22" "Beijing"
3g.donews.com 220.181.108.101 - - [17/Jan/2017:00:50:45 +0800] "GET /2334668 HTTP/1.1" "http://3g.donews.com/2334668" 302 160 "-" "Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" "-" "China" "22" "Beijing"
3g.donews.com 220.181.108.97 - - [17/Jan/2017:00:50:48 +0800] "GET /2422382 HTTP/1.1" "http://3g.donews.com/2422382" 302 160 "-" "Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" "-" "China" "22" "Beijing"
3g.donews.com 220.181.108.122 - - [17/Jan/2017:00:50:48 +0800] "GET /News/donews_detail?id=2288327 HTTP/1.1" "http://3g.donews.com/News/donews_detail?id=2288327" 200 970 "-" "Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" "-" "China" "22" "Beijing"
3g.donews.com 123.125.71.105 - - [17/Jan/2017:00:51:32 +0800] "GET /2390918 HTTP/1.1" "http://3g.donews.com/2390918" 302 160 "-" "Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" "-" "China" "22" "Beijing"
3g.donews.com 123.125.71.46 - - [17/Jan/2017:00:51:57 +0800] "GET /News/donews_detail?id=2144955 HTTP/1.1" "http://3g.donews.com/News/donews_detail?id=2144955" 200 970 "-" "Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" "-" "China" "22" "Beijing"
3g.donews.com 220.181.108.158 - - [17/Jan/2017:00:52:03 +0800] "GET /News/donews_detail?id=2324434 HTTP/1.1" "http://3g.donews.com/News/donews_detail?id=2324434" 200 970 "-" "Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" "-" "China" "22" "Beijing"
3g.donews.com 218.30.103.183 - - [17/Jan/2017:00:52:11 +0800] "GET /2941891 HTTP/1.1" "http://3g.donews.com/2941891" 302 160 "-" "Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25" "-" "China" "22" "Beijing"
3g.donews.com 220.181.108.149 - - [17/Jan/2017:00:52:33 +0800] "GET /News/donews_detail?id=278698 HTTP/1.1" "http://3g.donews.com/News/donews_detail?id=278698" 200 970 "-" "Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" "-" "China" "22" "Beijing"
3g.donews.com 220.181.108.99 - - [17/Jan/2017:00:52:46 +0800] "GET /News/donews_detail?id=2317077 HTTP/1.1" "http://3g.donews.com/News/donews_detail?id=2317077" 200 970 "-" "Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" "-" "China" "22" "Beijing"
4、代码展示
package com.donews.localspark
import java.util.regex.Pattern
import kafka.common.TopicAndPartition
import kafka.message.MessageAndMetadata
import kafka.serializer.StringDecoder
import kafka.utils.{ZKGroupTopicDirs, ZkUtils}
import org.I0Itec.zkclient.ZkClient
import org.apache.spark.SparkConf
import org.apache.spark.sql.SQLContext
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka._
import org.apache.spark.streaming.{Duration, StreamingContext}
import org.slf4j.LoggerFactory
import scala.collection.mutable.ArrayBuffer
/**
* Created by yuhui on 2017/2/6.
*/
case class NginxBeans(domain: String, ip: String, ts: String, url: String, ref: String, ua: String, suuid: String)
object Streaming2Kafka1{
def main(args: Array[String]): Unit = {
val LOG = LoggerFactory.getLogger(Streaming2Kafka2.getClass)
val conf = new SparkConf().setAppName("streaming_test").setMaster("local[4]").set("spark.driver.port", "18080").set("spark.streaming.kafka.maxRatePerPartition" ,"6")
val ssc = new StreamingContext(conf, Duration(5000))
val kafkaParam = Map[String, String](
"metadata.broker.list" -> "tagtic-master:9092,tagtic-slave01:9092,tagtic-slave02:9092,tagtic-slave03:9092",
"auto.offset.reset" -> "smallest"
)
val topic: String = "donews_website_nginx_log" //消费的 topic 名字
val topics: Set[String] = Set(topic) //创建 stream 时使用的 topic 名字集合
val topicDirs = new ZKGroupTopicDirs("donews_website_nginx_log", topic) //创建一个 ZKGroupTopicDirs 对象,对保存
val zkClient = new ZkClient("tagtic-master:2181") //zookeeper 的host 和 ip,创建一个 client
val children = zkClient.countChildren(s"${topicDirs.consumerOffsetDir}") //查询该路径下是否字节点(默认有字节点为我们自己保存不同 partition 时生成的)
var kafkaStream: InputDStream[(String, String)] = null
var fromOffsets: Map[TopicAndPartition, Long] = Map() //如果 zookeeper 中有保存 offset,我们会利用这个 offset 作为 kafkaStream 的起始位置
val messageHandler = (mmd: MessageAndMetadata[String, String]) => (mmd.topic, mmd.message()) //这个会将 kafka 的消息进行 transform,最终 kafka 的数据都会变成 (topic_name, message) 这样的 tuple
if (children > 0) {
//如果保存过 offset,这里更好的做法,还应该和 kafka 上最小的 offset 做对比,不然会报 OutOfRange 的错误
for (i <- 0 until children) {
val partitionOffset = zkClient.readData[String](s"${topicDirs.consumerOffsetDir}/$i")
val tp = TopicAndPartition(topic, i)
fromOffsets += (tp -> partitionOffset.toLong) //将不同 partition 对应的 offset 增加到 fromOffsets 中
// LOG.info("@@@@@@ topic[" + topic + "] partition[" + i + "] offset[" + partitionOffset + "] @@@@@@")
}
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)](ssc, kafkaParam, fromOffsets, messageHandler)
}
else {
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParam, topics) //如果未保存,根据 kafkaParam 的配置使用最新或者最旧的 offset
}
var offsetRanges = Array[OffsetRange]()
kafkaStream.transform { rdd =>
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges //得到该 rdd 对应 kafka 的消息的 offset
rdd
}.map(msg => msg._2).foreachRDD { rdd =>
val sqlContext = SQLContext.getOrCreate(rdd.sparkContext)
import sqlContext.implicits._
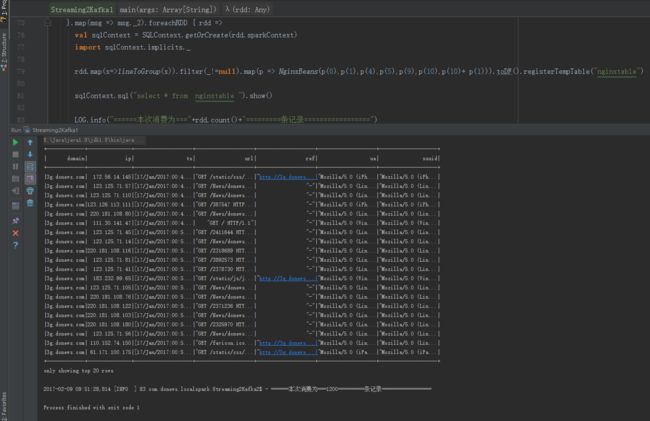
rdd.map(x=>lineToGroup(x)).filter(_!=null).map(p => NginxBeans(p(0),p(1),p(4),p(5),p(9),p(10),p(10)+ p(1))).toDF().registerTempTable("nginxtable")
sqlContext.sql("select * from nginxtable ").show()
LOG.info("======本次消费为==="+rdd.count()+"=========条记录=================")
for (o <- offsetRanges) {
val zkPath = s"${topicDirs.consumerOffsetDir}/${o.partition}"
ZkUtils.updatePersistentPath(zkClient, zkPath, o.fromOffset.toString) //将该 partition 的 offset 保存到 zookeeper
// LOG.info(s"@@@@@@ topic ${o.topic} partition ${o.partition} fromoffset ${o.fromOffset} untiloffset ${o.untilOffset} #######")
}
}
ssc.start() // 真正启动程序
ssc.awaitTermination() //阻塞等待
}
val regex = "^([\\S]+)\\s([\\S]+)\\s(\\W+)\\s([\\S]+)\\s(\\[.+\\])\\s(\".+\")\\s(\".+\")\\s([\\S]+)\\s([\\S]+)\\s(\".+\")\\s(\".+\")\\s(\".+\")\\s(\".+\")\\s(\".+\")\\s(\".+\")$"
//通过正则分组,获取字段。如果字段匹配成功且大于11的为有效数据
def lineToGroup(line: String): ArrayBuffer[String] = {
val groups = ArrayBuffer[String]()
val p = Pattern.compile(regex)
val m = p.matcher(line)
while (m.find()) {
for (i <- Range(1, m.groupCount() + 1, 1)) {
groups.append(m.group(i))
}
}
if(groups.length>=11){
return groups
}
null
}
}
org.apache.spark
spark-streaming_2.10
1.6.1
5、运行结果展示
6、Kafka Manager 和 Zookeeper展示
Kafka Manager 展示
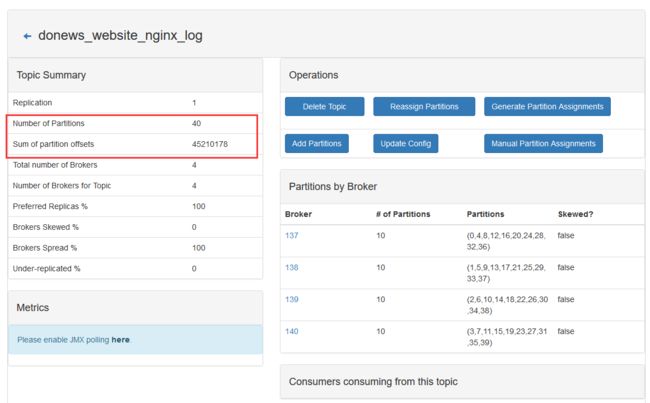
Zookeeper展示
![]()
