influxdb学习笔记(一):搭建与使用
引言
InfluxDB是一个时间序列数据库,旨在处理高写入和查询负载。它是TICK堆栈的组成部分 。InfluxDB旨在用作涉及大量带时间戳数据的任何用例的后备存储,包括DevOps监控,应用程序指标,物联网传感器数据和实时分析。
influxdb安装
这里安装的版本是1.4以后的,centos和Ubuntu的安装都比较简单,为:
# centos
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.4.1.x86_64.rpm
sudo yum localinstall influxdb-1.4.1.x86_64.rpm
sudo service influxdb start
# Ubuntu
wget https://dl.influxdata.com/influxdb/releases/influxdb_1.4.0_amd64.deb
sudo dpkg -i influxdb_1.4.0_amd64.deb
sudo systemctl start influxdb
然后我们输入influxdb就可以看到如下提示信息:
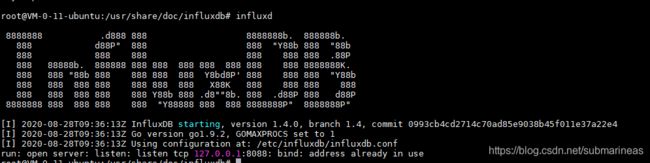
influxdb启动后,就有一些检测状态的命令如下:
启动命令:service influxdb start
停止服务:service influxdb stop
重启服务:service influxdb restart
尝试重启服务:service influxdb try-restart
重新加载服务:service influxdb reload
强制重新加载服务:service influxdb force-reload
查看服务状态:service influxdb status
另外在influxdb 1.3版本之前,是有内置一个管理页面的,虽然我是看网上是这么说的,至于为什么influxdb去掉了这个界面,就不得而知了,不过后来产生的chronograf 和 grafana确实是更加好用,页面也更加美观,安装方式和上面的类似,但需要注意的是看很多篇博客说在0.4以后的版本中,http界面就已经不再自动启动8083管理界面,所以需要手动开启,在 /etc/influxdb 下的配置文件:

而在1.3版本后,也就是我现在正在用的这个版本1.4,是没有管理界面的,即使去开启了http中的设置,也没用,当访问 localhost:8086后页面只会有一个 404 page not found,所以这里推荐使用 chronograf 或者 grafana:
chronograf的安装方式也很简单,我这里用的是ubuntu18.04,那么需要去找到相应的deb包,而chronograf和influxdb的关系可以从官方的图片能看出:

那么我们能从官网 https://docs.influxdata.com/chronograf/v1.8/introduction/installation 上找到其它三个的下载方式,相应的命令为:
wget https://dl.influxdata.com/kapacitor/releases/kapacitor_1.4.0_amd64.deb
sudo dpkg -i kapacitor_1.4.0_amd64.deb
sudo systemctl start kapacitor
wget https://dl.influxdata.com/telegraf/releases/telegraf_1.4.3-1_amd64.deb
sudo dpkg -i telegraf_1.4.3-1_amd64.deb
sudo systemctl start telegraf
wget https://dl.influxdata.com/chronograf/releases/chronograf_1.4.0.0_amd64.deb
sudo dpkg -i chronograf_1.4.0.0_amd64.deb
sudo systemctl start chronograf
然后就可以将将Chronograf连接到InfluxDB实例。对于Connection String,输入运行InfluxDB的机器的主机名或IP,并确保包含InfluxDB的默认端口:8086。Chronograf的默认端口为8888,第一次进去后会需要添加资源和填写账号密码,但不论是Chronograf或者influxdb初始是没有对其设置,所以可以直接进去:
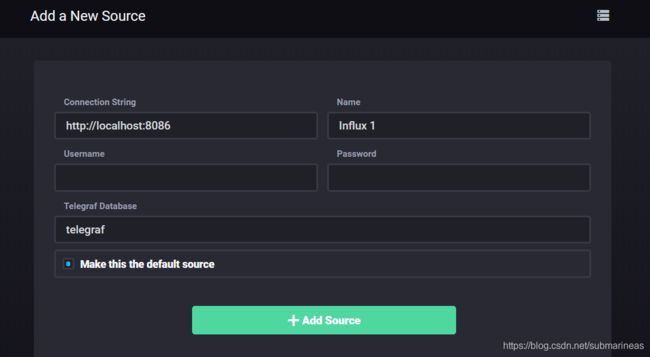
然后telegraf已经将当前系统环境导入了Chronograf,那么可以直接从Host List 看到当前服务器使用情况:

另外进入configration下能看到influxdb的连接状态,以及添加其它的服务资源:

data Explorer 是数据展示部分,我们可以查看表结构以及查询数据,但好像并不太支持插入和use语句,使用后会在下方提示能使用的语句类型。

influxdb使用
influx原生支持continuties query进行二次运算,与传统的数据库有明显的区别,支持添加查询操作,存在fields和tags概念,对应传统数据库的字段和索引。支持sql语句,支持http 方式进行插入和查询。以时间为主键。
这可能也是为什么查询效率会高于mongo的原因,如果是在拿到json后还要继续做运算的话,influxdb的速度会远远快过MongoDB,具体可看 InfluxDB is 2.4x Faster vs. MongoDB for Time Series Workloads

具体的在架构介绍上有所描述,这里主要提及语句以及连接:
influxdb连接数据库:
- 数据库安装在本机:
influx -precision rfc3339
- 连接远程数据库
influx -host sample.host -precision rfc3339
参数:-precision为设置显示时间格式,如果没有设置,返回的时间类型字段显示为时间戳,使用rfc3339返回的时间格式为:2018-10-11T06:37:53.439100393Z
timestamp: time存着时间戳,这个时间戳以RFC3339格式展示了与特定数据相关联的UTC日期和时间。
field set: 每组field key和field value的集合,如butterflies = 3, honeybees = 28
field key/value: 在InfluxDB中不能没有field,field没有索引。
tag set: 不同的每组tag key和tag value的集合,如location = 1, scientist = langstroth
tag key/value: 在InfluxDB中可以没有tag,tag是索引起来的。
measurement: 是一个容器,包含了列time,field和tag。概念上类似表。
retention policy: 单个measurement可以有不同的retention policy。measurement默认会有一个autogen的保留策略,autogen中的数据永不删除且备份数replication为1(只有一份数据,在集群中起作用)。
series: series是共同retention policy,measurement和tag set的集合。

引用自:influxDB学习笔记
上面链接很详细的介绍了influxdb的表结构以及大部分的语句练习,这里我就不再过多赘述了,influxdb的语句结构和主流的sql语言基本一致:
// 例一:从单个measurement查询所有的field和tag
> SELECT * FROM "h2o_feet"
// 例二:从单个measurement中查询特定tag和field
> SELECT "level description","location","water_level" FROM "h2o_feet"
// 例三:从单个measurement中选择特定的tag和field,并提供其标识符类型
> SELECT "level description"::field,"location"::tag,"water_level"::field FROM "h2o_feet"
// 例四:从单个measurement查询所有field
> SELECT *::field FROM "h2o_feet"
// 例五:从measurement中选择一个特定的field并执行基本计算
> SELECT ("water_level" * 2) + 4 from "h2o_feet"
// 例六:从多个measurement中查询数据
> SELECT * FROM "h2o_feet","h2o_pH"
// 例七:从完全限定的measurement中选择所有数据
> SELECT * FROM "NOAA_water_database"."autogen"."h2o_feet"
// 例八:从特定数据库中查询measurement的所有数据
> SELECT * FROM "NOAA_water_database".."h2o_feet"
我想说明的是python连接influxdb的使用方式,首先根据python官方文档 InfluxDB-Python ,我们需要通过pip下载influxdb:
$ pip install influxdb
$ pip install --upgrade influxdb
$ pip uninstall influxdb
$ sudo apt-get install python-influxdb
下载完包后,我们还需要进入influxdb数据库创建用户以及用户权限:
# 显示用户
SHOW USERS
# 创建用户
CREATE USER "username" WITH PASSWORD 'password'
# 创建管理员权限的用户
CREATE USER <username> WITH PASSWORD '' WITH ALL PRIVILEGES
# 删除用户
DROP USER "username"
创建成功用户后,如果是deb安装的方式,和上面的路径一样,修改/etc/influxdb下的conf配置,将 auth-enabled 改为True:
[http]
enabled = true
bind-address = ":8086"
auth-enabled = true #
log-enabled = true
write-tracing = false
pprof-enabled = false
https-enabled = false
https-certificate = "/etc/ssl/influxdb.pem"
而如果原先有用户并添加了相关权限可能就需要授权认证 auth,否则会一直报错:
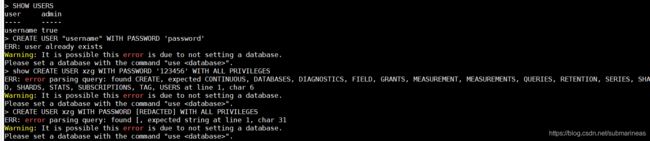
所以和mysql类似,将使用账号密码登录:
influx -username xzg -password 123456

然后用python连接数据库并插入数据,官网例子为:
>>> from influxdb import InfluxDBClient
>>> json_body = [
{
"measurement": "cpu_load_short",
"tags": {
"host": "server01",
"region": "us-west"
},
"time": "2009-11-10T23:00:00Z",
"fields": {
"value": 0.64
}
}
]
>>> client = InfluxDBClient('localhost', 8086, 'root', 'root', 'example')
>>> client.create_database('example')
>>> client.write_points(json_body)
>>> result = client.query('select value from cpu_load_short;')
>>> print("Result: {0}".format(result))

influxdb只需要query(“sql”)就能完成sql语句的执行,这其实是简化了很多的sql连接操作,但那样的坏处是如果在多线程下,可能会出现线程竞争而没法定位到问题的情况,所以如果可能,可以考虑自造连接池的方案。然后influxdb还有一种方法是 write_points 批量写入的方法,具体如下:
body = [
{
"measurement": "students",
"time": current_time,
"tags": {
"class": 1
},
"fields": {
"name": "Hyc",
"age": 3
},
},
{
"measurement": "students",
"time": current_time,
"tags": {
"class": 2
},
"fields": {
"name": "Ncb",
"age": 21
},
},
]
res = client.write_points(body)
但目前来讲,我不太清楚,它的底层怎样去完成批量导入的,如果之后有时间,会考虑看看源码,那么这里就简单的介绍一下了。
influxdb架构介绍
influxdb的主要特性有:
- 内置HTTP接口,使用方便
- 数据可以打标记,查让查询可以很灵活
- 类SQL的查询语句
- 安装管理很简单,并且读写数据很高效
- 能够实时查询,数据在写入时被索引后就能够被立即查出
虽然和MongoDB相比,大部分业务可能还是会选择后者,因为mongo的开源应用确实比较多,生态比较好,本篇的契机也是我在划水的时候看到有这么个东西,结合之前做的物联网相关的业务,感觉这确实是个很好的数据库,然而目前业务可能暂时用不到了,以后有机会的话还是可以再回来体验的,另外,除了上面有引用的一篇mongo的对比,还有两篇对比试验可以看看:
InfluxDB和MySQL的读写对比测试
A Deep Dive into InfluxDB
顺带我也去找了些资料,关于influxdb的底层架构方式:
influxdb存储引擎tsdb代码目录:github.com\influxdata\influxdb\tsdb
可以先阅读以下对于tsdb的官方文档。 其采用的存储模型是LSM-Tree模型,对其进行了一定的改造。将其称之为Time-Structured Merge Tree (TSM)
当一个point写入时,influxdb根据其所属的database、measurements和timestamp选取一个对应的shard。每个 shard对应一个TSM存储引擎。每个shard对应一段时间范围的存储。
一个TSM存储引擎包含:
- In-Memory Index 在shard之间共享,提供measurements,tags,和series的索引
- WAL 同其他database的binlog一样,当WAL的大小达到一定大小后,会重启开启一个WAL文件。
- Cache 内存中缓存的WAL,加速查找
- TSM Files 压缩后的series数据
- FileStore TSM Files的封装
- Compactor 存储数据的比较器
- Compaction Planner 用来确定哪些TSM文件需要compaction,同时避免并发compaction之间的相互干扰
- Compression 用于压缩持久化文件
- Writers/Readers 用于访问文件
引用自 influxdb源码阅读之tsdb核心数据结构梳理
那么就能得到如下图:

InfluxDB学习笔记
到此,本篇结束!
参考与推荐:
[1]. influxdb基础—介绍和配置
[2]. Telegraf plugins