java基础类Character源码分析
目录
简介
属性
进制相关-radix
字符大小相关
补充字符与代理代码单元相关
基础属性
char与位,字节相关
构造方法
构造器
valueOf与缓存
基本方法
返回char
hashcode
equal
toString
与补充字符与代理代码单元相关方法
判断代码点
判断代理代码单元
代理点,代码单元的个数与互转
简介
Character 类用于对单个字符进行操作。
Character 类在对象中包装一个基本类型 char 的值
注释里详细地讲了java中char,代码点,代码单元的关系
16 位unicode编码的所有 65,536 个字符并不能完全表示全世界所有正在使用或曾经使用的字符。于是,Unicode 标准已扩展到包含多达 1,112,064 个字符。那些超出原来的16 位限制的字符被称作增补字符。Java的char类型是固定16bits的。代码点在U+0000 — U+FFFF之内到是可以用一个char完整的表示出一个字符。但代码点在U+FFFF之外的,一个char无论如何无法表示一个完整字符。这样用char类型来获取字符串中的那些代码点在U+FFFF之外的字符就会出现问题。
增补字符是代码点在 U+10000 至 U+10FFFF 范围之间的字符,也就是那些使用原始的 Unicode 的 16 位设计无法表示的字符。从 U+0000 至 U+FFFF 之间的字符集有时候被称为基本多语言面 (BMP UBasic Multilingual Plane )。因此,每一个 Unicode 字符要么属于 BMP,要么属于增补字符。
/**
* Charactre类包装了原始类型char的值到一个对象。
* 一个Character类的对象包含了一个单独的字段,类型为char。
*
*
此外,这个类提供了几个方法,包括确定一个字符的种类(小写字符,数字,等等),
* 将字符从大写转换为小写,反之亦然。
*
*
字符信息基于版本6.2.0的Unicode标准
*
*
Character类的方法和数据由Unicode协会维护的Unicode字符数据库
* 的一部分UnicodeData文件的信息定义。
* 这个文件为每个定义的Unicode编码点或者字符范围,指定包括名字和通用类别的属性。
*
*
这个文件及其描述能从Unicode协会获得:http://www.unicode.org
*
*
char数据类型(Character对象封装的值)是基于原始Unicode规范,
* 它定义字符是固定长度的16bit的实体。
* Unicode标准后来出现了变化,允许出现超过16位的字符。
* 合法的代码点的范围是在U+0000到U+10FFFF,成为Unicode标量值。(请参考Unicode标准中U+n符号的定义。)
*
*
从U+0000 到 U+FFFF的字符集有时被成为基本多语言平面(BMP)。
* 代码点大于U+FFFF的字符成为补充字符。
* java平台在String和StringBuffer类中的char数组中使用UTF-16表示。
* 在这个表示中,补充字符以2个char值表示。
* 第一个来于高代理范围(\uD800-\uDBFF),第二个来自低代理范围(\uDC00-\uDFFF)。
*
*
一个char值,因此,代表了BMP的代码点,包括代理代码点或者UTF-16编码的代码单元。
* 一个int值(32位)代表了所有的Unicode代码点,包括补充代码点。
* int的低位的21bit被用来代表Unicode代码点,高位的11bit一定是0.
* 除非另外指定,补充字符和代理值的行为如下:
*
*
自我理解:可以这样认为,一个int32位,一个char16位,一个代码单元16位,一个代码点16位或32位。
* 一个char对应一个代码单元,一个char对应16位的代码点和32位代码点的代理代码点(16位的)。
* 而一个int,无论如何,都能代表一个代码点。
* 有些字符需要两个char表示,一个char可能仅仅是某个字符的一半。
*
*
* - 仅仅接受一个char值的方法不能接受代理字符。
* 它们视代理字符的char值作为未定义的字符。
* 例如{@code Character.isLetter('\u005CuD840')} 返回false。
* 即使这个特定的值后面跟着任何低代理的值都能作为一个字符。
*
*
*
- 接受一个int值的方法支持左右Unicode字符,包括补充字符。
* 例如,{@code Character.isLetter(0x2F81A)}返回true,
* 因为这个代码点的值对应一个字符。
*
*
* 在Java SE API的文档内,Unicode代码点用于值对应在U+0000 到 U+10FFFF 的字符(最大的超过16bit)。
* Unicode代码单元用于UTF-16编码的16bit的char值。
* 更多的Unicode的问题可以看,http://www.unicode.org/glossary/
*
* @author Lee Boynton
* @author Guy Steele
* @author Akira Tanaka
* @author Martin Buchholz
* @author Ulf Zibis
* @since 1.0
*/
public final
class Character implements java.io.Serializable, Comparable

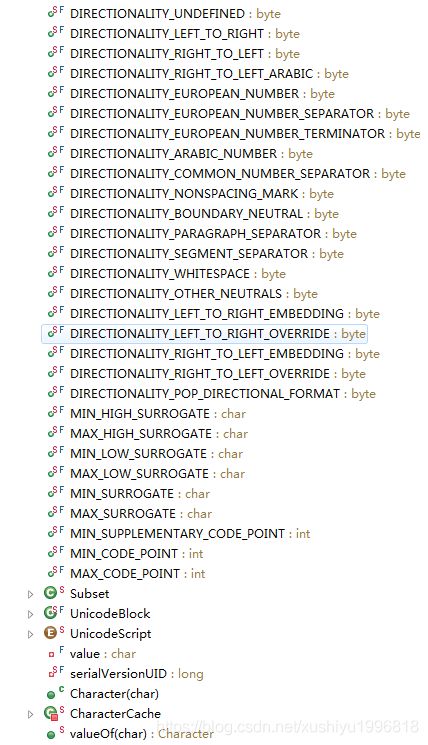
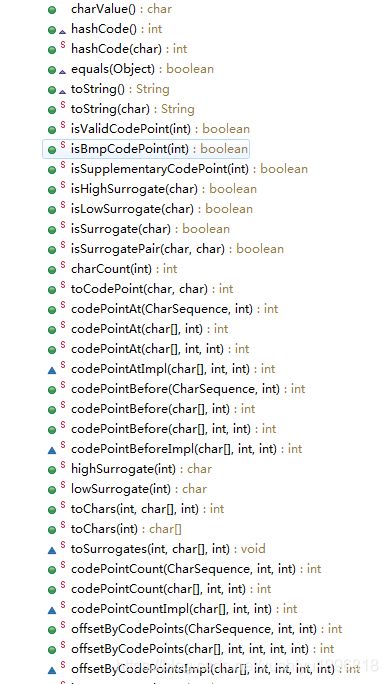
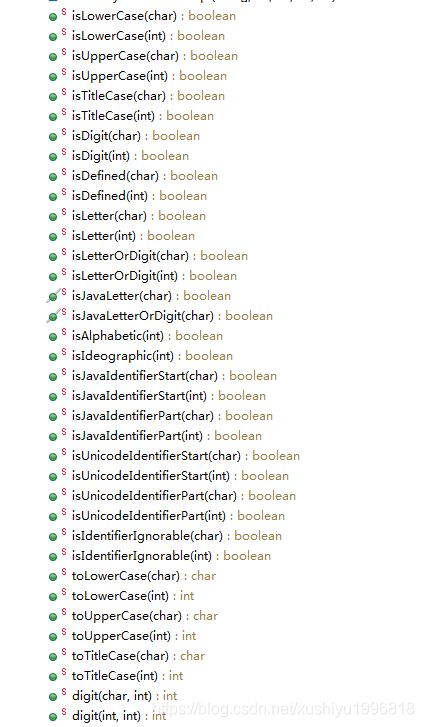
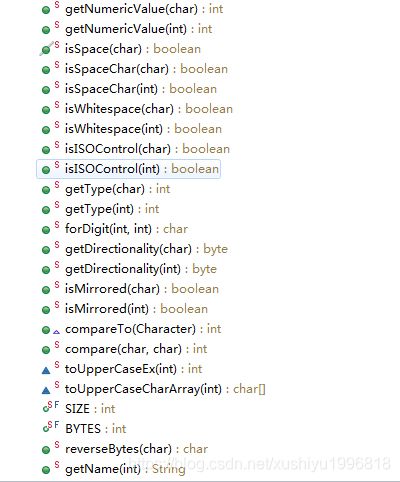
属性
进制相关-radix
/**
* 转换成字符串和从字符串转换的可行的最小的radix。
* 这个字段的常量值是最小的radix转换方法的radix参数,如digit方法,forDigit方法,Integer的toString方法。
*
*
* @see Character#digit(char, int)
* @see Character#forDigit(int, int)
* @see Integer#toString(int, int)
* @see Integer#valueOf(String)
*/
public static final int MIN_RADIX = 2;
/**
* 转换成字符串和从字符串转换的可行的最大的radix。
* 这个字段的常量值是最大的radix转换方法的radix参数,如digit方法,forDigit方法,Integer的toString方法。
*
* @see Character#digit(char, int)
* @see Character#forDigit(int, int)
* @see Integer#toString(int, int)
* @see Integer#valueOf(String)
*/
public static final int MAX_RADIX = 36;字符大小相关
/**
* 这个字段的常量值是char的最小值 {@code '\u005Cu0000'}
*
* @since 1.0.2
*/
public static final char MIN_VALUE = '\u0000';
/**
* 这个字段的常量值是char的最小值 {@code '\u005CuFFFF'}
* 注意:char是16位的,所以对应4个16进制的数字。
*
* @since 1.0.2
*/
public static final char MAX_VALUE = '\uFFFF';补充字符与代理代码单元相关
/**
* Unicode 的UTF-16编码的高代理代码单元的最小值,常量{@code '\u005CuD800'}
* 一个高代理同样也是一个领导代理。
*
* @since 1.5
*/
public static final char MIN_HIGH_SURROGATE = '\uD800';
/**
* Unicode 的UTF-16编码的高代理代码单元的最大值,常量{@code '\u005CuDBFF'}
* 一个高代理同样也是一个领导代理。
*
* @since 1.5
*/
public static final char MAX_HIGH_SURROGATE = '\uDBFF';
/**
* Unicode 的UTF-16编码的低代理代码单元的最小值,常量{@code '\u005CuDC00'}
* 一个低代理同样也是一个跟随代理。
* 可以看到高代理和低代理是连起来的,先是高代理,然后是低代理。
*
* @since 1.5
*/
public static final char MIN_LOW_SURROGATE = '\uDC00';
/**
* Unicode 的UTF-16编码的低代理代码单元的最大值,常量{@code '\u005CuDFFF'}
* 一个低代理同样也是一个跟随代理。
*
* @since 1.5
*/
public static final char MAX_LOW_SURROGATE = '\uDFFF';
/**
* Unicode 的UTF-16编码的代理代码单元的最小值,常量{@code '\u005CuD800'}
* 可以看到高代理和低代理是连起来的,先是高代理,然后是低代理。
*
* @since 1.5
*/
public static final char MIN_SURROGATE = MIN_HIGH_SURROGATE;
/**
* Unicode 的UTF-16编码的代理代码单元的最大值,常量{@code '\u005CuDFFF'}
*
* @since 1.5
*/
public static final char MAX_SURROGATE = MAX_LOW_SURROGATE;
/**
* Unicode补充代码点的最小值,常量{@code U+10000}
* @since 1.5
*/
public static final int MIN_SUPPLEMENTARY_CODE_POINT = 0x010000;
/**
* Unicode代码点的最小值,常量{@code U+0000}
*
* @since 1.5
*/
public static final int MIN_CODE_POINT = 0x000000;
/**
* Unicode代码点的最大值,常量{@code U+10FFFF}
* @since 1.5
*/
public static final int MAX_CODE_POINT = 0X10FFFF;基础属性
/**
* Character的值
*
* @serial
*/
private final char value;
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = 3786198910865385080L;char与位,字节相关
/**
* 用来表示一个char值在无符号的二进制形式下,使用的bit(位)的数量,常量16
*
* @since 1.5
*/
public static final int SIZE = 16;
/**
* 用来表示一个char值在无符号的二进制形式下,使用的byte(字节)的数量,常量2
*
* @since 1.8
*/
public static final int BYTES = SIZE / Byte.SIZE;构造方法
构造器
/**
* 创建一个新分配的Character对象,代表指定的char值
*
* @param value the value to be represented by the
* {@code Character} object.
*/
public Character(char value) {
this.value = value;
}valueOf与缓存
/** CharacterCache里面缓存着char的代码点对应[0,127]的Character实例
*
*/
private static class CharacterCache {
private CharacterCache(){}
static final Character cache[] = new Character[127 + 1];
static {
for (int i = 0; i < cache.length; i++)
//[0,127]
cache[i] = new Character((char)i);
}
}
/**
* 返回一个Character实例,代表指定的char值。
* 如果不需要一个新的Character实例,这个方法好于new Character(char)方法,
* 因为这个方法可能导致更好的空间和时间效率,通过缓存被频繁访问的值。
*
*
这个方法将总是缓存从{@code'\u005Cu0000'}到{@code '\u005Cu007F'}[0,127]的值。
*
* @param c a char value.
* @return a Character instance representing c.
* @since 1.5
*/
public static Character valueOf(char c) {
if (c <= 127) { // must cache
return CharacterCache.cache[(int)c];
}
return new Character(c);
}
基本方法
返回char
/**
* 返回Character对象的值
* @return the primitive {@code char} value represented by
* this object.
*/
public char charValue() {
return value;
}hashcode
/**
* 返回这个Character的hashcode,与调用charValue()的结果相同(就是返回这个Character的char值)
*
* @return a hash code value for this {@code Character}
*/
@Override
public int hashCode() {
return Character.hashCode(value);
}
/**
* 返回一个char值的hashcode,与{@code Character.hashCode()}匹配
*
* @since 1.8
*
* @param value The {@code char} for which to return a hash code.
* @return a hash code value for a {@code char} value.
*/
public static int hashCode(char value) {
//value强转成int
return (int)value;
}equal
/**
* 与指定对象比较。
* 当且仅当参数不是null而且是一个Character,代表与这个对象相同的char值,才返回true
*
*
* @param obj the object to compare with.
* @return {@code true} if the objects are the same;
* {@code false} otherwise.
*/
public boolean equals(Object obj) {
if (obj instanceof Character) {
//比较value与obj强转Character的char值
return value == ((Character)obj).charValue();
}
return false;
}toString
/**
* 返回一个代表这个Character的值的String对象。
* 这个对象的长度为1,唯一的成员是代表这个Character的char值。
*
* @return a string representation of this object.
*/
public String toString() {
char buf[] = {value};
return String.valueOf(buf);
}
/**
* 返回一个代表指定char值的String对象。
* 这个对象的长度为1,唯一的成员是代表这个Character的char值。
*
* @param c the {@code char} to be converted
* @return the string representation of the specified {@code char}
* @since 1.4
*/
public static String toString(char c) {
return String.valueOf(c);
}与补充字符与代理代码单元相关方法
判断代码点
/**
* 确定指定的代码点是否是一个合法的Unicode代码点
*
* @param codePoint the Unicode code point to be tested
* @return {@code true} if the specified code point value is between
* {@link #MIN_CODE_POINT} and
* {@link #MAX_CODE_POINT} inclusive;
* {@code false} otherwise.
* @since 1.5
*/
public static boolean isValidCodePoint(int codePoint) {
// 普通的确定形式为:
// codePoint >= MIN_CODE_POINT && codePoint <= MAX_CODE_POINT
// codePoint >= 0x000000 && codePoint <= 0X10FFFF
int plane = codePoint >>> 16; //移去16位,只剩左边的16位
return plane < ((MAX_CODE_POINT + 1) >>> 16); //plane小于0X11即可
}
/**
* 确定指定的代码点是否是一个BMP代码点。
* 这样的代码点能以一个单独的char表示
*
* @param codePoint the character (Unicode code point) to be tested
* @return {@code true} if the specified code point is between
* {@link #MIN_VALUE} and {@link #MAX_VALUE} inclusive;
* {@code false} otherwise.
* @since 1.7
*/
public static boolean isBmpCodePoint(int codePoint) {
return codePoint >>> 16 == 0; //只要codePoint只有右边16位可能为1,左边16位全为0即为BMP
//[0x0000,0xFFFF]
// Optimized form of:
// codePoint >= MIN_VALUE && codePoint <= MAX_VALUE
// We consistently use logical shift (>>>) to facilitate
// additional runtime optimizations.
}
/**
* 确定指定的代码点是否是补充代码点。(即不是BMP代码点)
*
* @param codePoint the character (Unicode code point) to be tested
* @return {@code true} if the specified code point is between
* {@link #MIN_SUPPLEMENTARY_CODE_POINT} and
* {@link #MAX_CODE_POINT} inclusive;
* {@code false} otherwise.
* @since 1.5
*/
public static boolean isSupplementaryCodePoint(int codePoint) {
return codePoint >= MIN_SUPPLEMENTARY_CODE_POINT
&& codePoint < MAX_CODE_POINT + 1;
//[0x10000,10FFFF]
}判断代理代码单元
/**
* 确定给定的char值是否是一个Unicode高代理代码单元。
* 这样的值不代表他们自己的字符,被用来代表UTF-16的补充字符。
*
* @param ch the {@code char} value to be tested.
* @return {@code true} if the {@code char} value is between
* {@link #MIN_HIGH_SURROGATE} and
* {@link #MAX_HIGH_SURROGATE} inclusive;
* {@code false} otherwise.
* @see Character#isLowSurrogate(char)
* @see Character.UnicodeBlock#of(int)
* @since 1.5
*/
public static boolean isHighSurrogate(char ch) {
// Help VM constant-fold; MAX_HIGH_SURROGATE + 1 == MIN_LOW_SURROGATE
//[\ud800,\udbff]
return ch >= MIN_HIGH_SURROGATE && ch < (MAX_HIGH_SURROGATE + 1);
}
/**
* 确定给定的char值是否是一个Unicode低代理代码单元。
* 这样的值不代表他们自己的字符,被用来代表UTF-16的补充字符。
*
* @param ch the {@code char} value to be tested.
* @return {@code true} if the {@code char} value is between
* {@link #MIN_LOW_SURROGATE} and
* {@link #MAX_LOW_SURROGATE} inclusive;
* {@code false} otherwise.
* @see Character#isHighSurrogate(char)
* @since 1.5
*/
public static boolean isLowSurrogate(char ch) {
//[udc00,\udfff]
return ch >= MIN_LOW_SURROGATE && ch < (MAX_LOW_SURROGATE + 1);
}
/**
* 确定给定的char值是否是一个Unicode代理代码单元。
* 这样的值不代表他们自己的字符,被用来代表UTF-16的补充字符。
* 一个char值当且仅当它是一个低代理代码单元或者高代理代码单元时,他才是一个代理代码单元
*
*
* @param ch the {@code char} value to be tested.
* @return {@code true} if the {@code char} value is between
* {@link #MIN_SURROGATE} and
* {@link #MAX_SURROGATE} inclusive;
* {@code false} otherwise.
* @since 1.7
*/
public static boolean isSurrogate(char ch) {
return ch >= MIN_SURROGATE && ch < (MAX_SURROGATE + 1);
//[\ud800,\udfff]
}
/**
* 确定指定的一对char是否是一个合法的Unicode代理对。
* 这个方法与下面相同:
* {@code
* isHighSurrogate(high) && isLowSurrogate(low)
* }
*
* @param high the high-surrogate code value to be tested
* @param low the low-surrogate code value to be tested
* @return {@code true} if the specified high and
* low-surrogate code values represent a valid surrogate pair;
* {@code false} otherwise.
* @since 1.5
*/
public static boolean isSurrogatePair(char high, char low) {
return isHighSurrogate(high) && isLowSurrogate(low);
}代理点,代码单元的个数与互转
/**
* 确定表示这个代码点需要的char的个数。
* 如果指定的字符大于等于0x10000,返回2,否则返回1。
* 这个方法没有验证指定的字符是否是一个合法的Unicode代码点。
* 调用者如果需要,使用isValidCodePoint验证
*
* @param codePoint the character (Unicode code point) to be tested.
* @return 2 if the character is a valid supplementary character; 1 otherwise.
* @see Character#isSupplementaryCodePoint(int)
* @since 1.5
*/
public static int charCount(int codePoint) {
return codePoint >= MIN_SUPPLEMENTARY_CODE_POINT ? 2 : 1;
//[0,U+10000)->1
}
/**
* 将指定的代理对转为对应的补充代码点。
* 这个方法不验证指定的代理对,调用者如果需要,必须使用isSurrogatePair来验证。
*
* @param high the high-surrogate code unit
* @param low the low-surrogate code unit
* @return the supplementary code point composed from the
* specified surrogate pair.
* @since 1.5
*/
public static int toCodePoint(char high, char low) {
// Optimized form of:
// return ((high - MIN_HIGH_SURROGATE \ud800 ) << 10)
// + (low - MIN_LOW_SURROGATE \udc00)
// + MIN_SUPPLEMENTARY_CODE_POINT 0x10000;
//high和low都为对应min时,为0x10000
//下面的就是上面的变种
return ((high << 10) + low) + (MIN_SUPPLEMENTARY_CODE_POINT
- (MIN_HIGH_SURROGATE << 10)
- MIN_LOW_SURROGATE);
} /**
* 返回指定字符在UTF-16编码中的高代理代码单元。
* 如果指定字符不是一个补充字符,回访一个无法定义的char。
* 如果isSupplementaryCodePoint(x)返回true,
* 则isHighSurrogate(highSurrogate(x))和toCodePoint(highSurrogate(x), lowSurrogate(x)) == x 永远为true
*
* @param codePoint a supplementary character (Unicode code point)
* @return the leading surrogate code unit used to represent the
* character in the UTF-16 encoding
* @since 1.7
*/
public static char highSurrogate(int codePoint) {
return (char) ((codePoint >>> 10)
+ (MIN_HIGH_SURROGATE - (MIN_SUPPLEMENTARY_CODE_POINT >>> 10)));
}
/**
* 返回指定字符在UTF-16编码中的低代理代码单元。
* 如果指定字符不是一个补充字符,回访一个无法定义的char。
* 如果isSupplementaryCodePoint(x)返回true,
* 则isLowSurrogate(lowSurrogate(x))和toCodePoint(highSurrogate(x), lowSurrogate(x)) == x 永远为true
*
* @param codePoint a supplementary character (Unicode code point)
* @return the trailing surrogate code unit used to represent the
* character in the UTF-16 encoding
* @since 1.7
*/
public static char lowSurrogate(int codePoint) {
return (char) ((codePoint & 0x3ff) + MIN_LOW_SURROGATE);
}