特征选择详解及与sklearn的结合应用
特征选择( Feature Selection )也称特征子集选择( Feature Subset Selection , FSS ),或属性选择( Attribute Selection )。是指从已有的M个特征(Feature)中选择N个特征使得系统的特定指标最优化,是从原始特征中选择出一些最有效特征以降低数据集维度的过程,是提高学习算法性能的一个重要手段,也是模式识别中关键的数据预处理步骤。对于一个学习算法来说,好的学习样本是训练模型的关键。
此外,需要区分特征选择与特征提取。特征提取 ( Feature extraction )是指利用已有的特征计算出一个抽象程度更高的特征集,也指计算得到某个特征的算法。
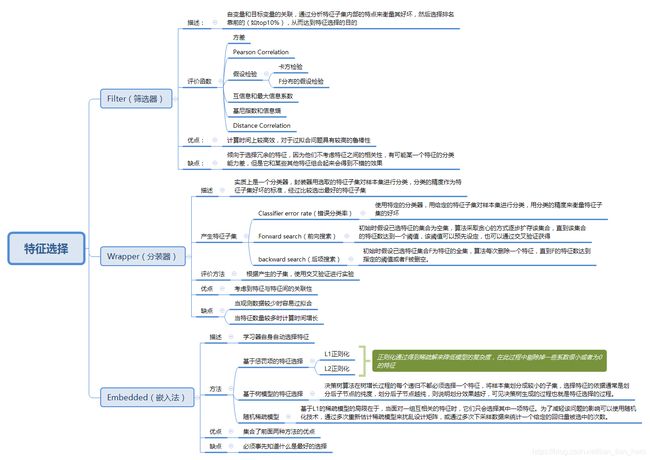
一、Filter(过滤法)
1、移除低方差的特征 (Removing features with low variance)
假设某特征的特征值只有0和1,并且在所有输入样本中,95%的实例的该特征取值都是1,那就可以认为这个特征作用不大。如果100%都是1,那这个特征就没意义了。当特征值都是离散型变量的时候这种方法才能用,如果是连续型变量,就需要将连续变量离散化之后才能用。可以把它作为特征选择的预处理,先去掉那些取值变化小的特征,然后再从接下来提到的的特征选择方法中选择合适的进行进一步的特征选择。
from sklearn.feature_selection import VarianceThreshold
#方差选择法,返回值为特征选择后的数据
#参数threshold为方差的阈值
VarianceThreshold(threshold=3).fit_transform(iris.data)
2、单变量特征选择
单变量特征选择的原理是分别单独的计算每个变量的某个统计指标,根据该指标来判断哪些指标重要,剔除那些不重要的指标。
对于分类问题(y离散),可采用:
Chi2,f_classif, mutual_info_classif,Mutual_info_classif
对于回归问题(y连续),可采用:
皮尔森相关系数,f_regression, mutual_info_regression,最大信息系数
(1)相关系数(Pearson Correlation)
皮尔森相关系数是一种最简单的,能帮助理解特征和响应变量之间关系的方法,该方法衡量的是变量之间的线性相关性,结果的取值区间为[-1,1],-1表示完全的负相关,+1表示完全的正相关,0表示没有线性相关。
Pearson Correlation速度快、易于计算,经常在拿到数据(经过清洗和特征提取之后的)之后第一时间就执行。Scipy的 pearsonr 方法能够同时计算 相关系数 和p-value.
计算方法:
第一种:
from sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr
#选择K个最好的特征,返回选择特征后的数据
#第一个参数为计算评估特征是否好的函数,该函数输入特征矩阵和目标向量,输出二元组(评分,P值)的数组,数组第i项为第i个特征的评分和P值。在此定义为计算相关系数
#参数k为选择的特征个数
x_new=SelectKBest(lambda X, Y: array(map(lambda x:pearsonr(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
第二种:
import numpy as np
from scipy.stats import pearsonr
np.random.seed(0)
size = 300
x = np.random.normal(0, 1, size)
# pearsonr(x, y)的输入为特征矩阵和目标向量
print("Lower noise", pearsonr(x, x + np.random.normal(0, 1, size)))
print("Higher noise", pearsonr(x, x + np.random.normal(0, 10, size)))
(2)假设检验(Hypothesis Test)
Chi2:经典的卡方检验是检验定性自变量对定性因变量的相关性,对应于sklearn中的chi2
F分布的假设检验:对应于sklearn中的F_classif、F_regression
(3)互信息和最大信息系数 (Mutual information and maximal information coefficient (MIC))
互信息为随机变量X与Y之间的互信息I(X;Y)为单个事件之间互信息的数学期望,也是评价定性自变量对定性因变量的相关性,计算公式:
I ( X ; Y ) = E [ I ( x i ; y j ) ] = ∑ x i ∈ X ∑ y j ∈ Y p ( x i , y j ) log p ( x i , y j ) p ( x i ) p ( y j ) I(X;Y) = E[I({x_i};{y_j})] = \sum\limits_{{x_i} \in X} {\sum\limits_{{y_j} \in Y} {p({x_i},{y_j})} } \log \frac{{p({x_i},{y_j})}}{{p({x_i})p({y_j})}} I(X;Y)=E[I(xi;yj)]=xi∈X∑yj∈Y∑p(xi,yj)logp(xi)p(yj)p(xi,yj)
互信息直接用于特征选择其实不是太方便:1、它不属于度量方式,也没有办法归一化,在不同数据及上的结果无法做比较;2、对于连续变量的计算不是很方便(X和Y都是集合,x,y都是离散的取值),通常变量需要先离散化,而互信息的结果对离散化的方式很敏感。
最大信息系数克服了这两个问题。它首先寻找一种最优的离散化方式,然后把互信息取值转换成一种度量方式,取值区间在[0,1]。 minepy 提供了MIC功能。
from sklearn.feature_selection import SelectKBest
from minepy import MINE
#由于MINE的设计不是函数式的,定义mic方法将其为函数式的,返回一个二元组,二元组的第2项设置成固定的P值0.5
def mic(x, y):
m = MINE()
m.compute_score(x, y)
return (m.mic(), 0.5)
#选择K个最好的特征,返回特征选择后的数据
x_new=SelectKBest(lambda X, Y: array(map(lambda x:mic(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
(4)距离相关(Distance Correlation)
距离相关是为了克服Pearson相关系数的弱点而生的。有时即便Pearson相关系数是0,我们也不能断定这两个变量是独立的(有可能是非线性相关);但如果距离相关是0,那么我们就可以说这两个变量是独立的。R语言中有方法dcor用于计算距离相关(点击链接有维基百科的相关介绍)
注:上面没有给出代码的方法都可以通过调用sklearn来实现,只有sklearn不能直接实现的我才给出了代码
使用selectKBest方法进行单变量特征选择
score_func : callable
Function taking two arrays X and y, and returning a pair of arrays
(scores, pvalues) or a single array with scores.
Default is f_classif (see below "See also"). The default function only
works with classification tasks.
k : int or "all", optional, default=10
Number of top features to select.
The "all" option bypasses selection, for use in a parameter search.
F_classif(分类):分类任务的标签/特征之间的方差分析f值。
Mutual_info_classif(相互信息分类):离散目标的相互信息。
chi2(卡方检验):分类任务的非负特征的chi平方统计。
F_regression(回归):回归任务的标签/特征之间的F值。
Mutual_info_regression(相互信息回归):连续目标的相互信息。
SelectPercentile(选择百分位数):根据最高分数的百分位数选择特征。
selectFpr:根据假阳性率测试选择特征。
selectFdr:根据估计的误报率选择特征。
selectFwe:根据家庭错误率选择功能。
GenericUnivariateSelect(通用单变量选择):具有可配置模式的单变量特征选择器。
Get_support():用于得到特征筛选的布尔值结果
indices : boolean (default False)
If True, the return value will be an array of integers, rather than a boolean mask.
以上是sklearn对单变量特征选择的支持,首先我们先要导入想要用来进行特征选择的方法,例如from sklearn.feature_selection import chi2。然后使用SelectKBest(score_func,K)根据我们选择的方法计算的得分,移除K名以外的所有特征。最后,我们可以使用Get_support(X,Y)方法得到特征筛选后的布尔值(整型)数组,依据用户给出的特征的排列顺序,如果该特征被移除,数组中相应位置返回false;我们也可以使用fit_transform(X,Y)方法直接得到特征选择后的整个新的同特征向量数组x_new.当然,除了SelectKBest,也可以用SelectPercentile等方法。
二、Wrapper(封装器):
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,移除若干权值系数的特征,再基于新的特征集进行下一轮训练。
对特征含有权重的预测模型(例如,线性模型对应参数coefficients),RFE通过递归减少考察的特征集规模来选择特征。首先,预测模型在原始特征上训练,每个特征指定一个权重。之后,那些拥有最小绝对值权重的特征被踢出特征集。如此往复递归,直至剩余的特征数量达到所需的特征数量。
Sklearn中有两种方法:RFE和RFECV
(1)REF(estimator,n_features_to_select,step)
给定一个为特征分配权重的外部估计量(例如线性模型的系数),递归特征消除(rfe)的目标是通过递归地考虑更小的特征集来选择特征。首先,对估计量进行初始特征集的训练,通过“coef”属性或“feature”importances属性获得每个特征的重要性,然后从当前特征集中删去最不重要的特征。该过程在修剪集上递归地重复,直到最终达到所需的要选择的特性数量。
其中estimator是带有特征权重的分类器(所有的回归模型都有feature_importances),而n_features_to_select就是我们要保留的特征,step是每次递归要出去的特征的数目。
from sklearn.datasets import make_friedman1
from sklearn.feature_selection import RFE
from sklearn.svm import SVR
X, y = make_friedman1(n_samples=50, n_features=10, random_state=0)
estimator = SVR(kernel="linear")
selector = RFE(estimator, 5, step=1)
selector = selector.fit(X, y)
print(selector.support_ )# doctest: +NORMALIZE_WHITESPACE
输出:array([ True, True, True, True, True,
False, False, False, False, False], dtype=bool)
print(selector.ranking_)
输出:array([1, 1, 1, 1, 1, 6, 4, 3, 2, 5])
(2)RFECV(estimator,step,cv)
RFECV即通过交叉验证的方式执行RFE,以此来选择最佳数量的特征。我们注意到这个函数中没有n_features_to_select,所以他会递归所有的特征子集,然后通过交叉验证选择最佳数量的特征。
from sklearn.datasets import make_friedman1
from sklearn.feature_selection import RFECV
from sklearn.svm import SVR
X, y = make_friedman1(n_samples=50, n_features=10, random_state=0)
estimator = SVR(kernel="linear")
selector = RFECV(estimator, step=1, cv=5)
selector = selector.fit(X, y)
print(selector.support_) # doctest: +NORMALIZE_WHITESPACE
输出:array([ True, True, True, True, True,
False, False, False, False, False], dtype=bool)
print(selector.ranking_)
输出:array([1, 1, 1, 1, 1, 6, 4, 3, 2, 5])
support_属性可以得到特征筛选结果的布尔值数组,ranking_属性可以得到对应位置特征得分的排序,被选中的特征都会标志为1。
三、Embedded(嵌入法)
单变量特征选择方法独立的衡量每个特征与响应变量之间的关系,另一种主流的特征选择方法是基于机器学习模型的方法。有些机器学习方法本身就具有对特征进行打分的机制,或者很容易将其运用到特征选择任务中,例如回归模型,SVM,决策树,随机森林等等。其实Pearson相关系数等价于线性回归里的标准化回归系数。
SelectFromModel作为meta-transformer,能够用于拟合后任何拥coef_或feature_importances_属性的预测模型。如果特征对应的coef_或feature_importances_值低于设定的阈值threshold,那么这些特征将被移除。除了手动设置阈值,也可通过字符串参数调用内置的启发式算法(heuristics)来设置阈值,包括:平均值(“mean”), 中位数(“median”)以及他们与浮点数的乘积,如“0.1*mean”。
1、 基于惩罚项的特征选择法
最常用的是通过L1和L2正则化来选取特征。L1是通过稀疏参数(减少参数的数量)来降低复杂度,使用L1范数作为惩罚项的线性模型(Linear models)会得到稀疏解,大部分特征对应的系数为0,我们可以选择系数不为0的特征用于分类器。L2是通过减小参数值的大小来降低复杂度,相比于L1,L2正则化会让系数的取值变得平均,不像L1那样系数会因为细微的数据变化而波动,所以L2正则化对于特征选择来说是一种稳定的模型。。特别指出,常用于此目的的稀疏预测模型有 linear_model.Lasso(回归), linear_model.LogisticRegression 和 svm.LinearSVC(分类)。
from sklearn.svm import LinearSVC
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectFromModel
iris = load_iris()
X, y = iris.data, iris.target
Print(X.shape)
输出:(150, 4)
lsvc = LinearSVC(C=0.01, penalty="l1", dual=False).fit(X, y)
model = SelectFromModel(lsvc, prefit=True)
X_new = model.transform(X)
Print(X_new.shape)
输出:(150, 3)
以上代码中我们也可以调用get_support()方法来获取特征选择的结果,也可以通过feature_importances_或者coef_来查看各特征的比重。
当然,上面的程序中我们也可以替换机器学习模型,更改残参数中的惩罚项来选择L1还是L2正则化。
2、 基于树模型的特征选择
基于树的预测模型(见 sklearn.tree 模块,森林见 sklearn.ensemble 模块)能够用来计算特征的重要程度,因此能用来去除不相关的特征。
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectFromModel
iris = load_iris()
X, y = iris.data, iris.target
Print(X.shape)
输出:(150, 4)
clf = ExtraTreesClassifier()
clf = clf.fit(X, y)
clf.feature_importances_
array([ 0.04..., 0.05..., 0.4..., 0.4...])
model = SelectFromModel(clf, prefit=True)
X_new = model.transform(X)
Print(X_new.shape)
输出:(150, 2)
熟悉决策树的同学都知道,决策树的实现过程就是通过计算基尼指数或者信息熵来选择最佳特征进行分类的,我们便是利用这个过程进行特征选择。当然在决策树或者随机森林中,我们还可以设置树的深度来控制得到的特征数量,树的深度不能太低也不能太高,太低会导致分类精度不够,太高容易过拟合,具体的大家可以自己去网上查查,我这里就不多讲了。
3、随机稀疏模型(Randomized sparse models)
基于L1的稀疏模型的局限在于,当面对一组互相关的特征时,它们只会选择其中一项特征。为了减轻该问题的影响可以使用随机化技术,通过多次重新估计稀疏模型来扰乱设计矩阵,或通过多次下采样数据来统计一个给定的回归量被选中的次数。
稳定性选择是一种基于二次抽样和选择算法相结合较新的方法,选择算法可以是回归、SVM或其他类似的方法。它的主要思想是在不同的数据子集和特征子集上运行特征选择算法,不断的重复,最终汇总特征选择结果,比如可以统计某个特征被认为是重要特征的频率(被选为重要特征的次数除以它所在的子集被测试的次数)。理想情况下,重要特征的得分会接近100%。稍微弱一点的特征得分会是非0的数,而最无用的特征得分将会接近于0。
sklearn在随机lasso(RandomizedLasso)和随机逻辑回归(RandomizedLogisticRegression)中有对稳定性选择的实现。
from sklearn.linear_model import RandomizedLasso
from sklearn.datasets import load_boston
boston = load_boston()
#using the Boston housing data.
#Data gets scaled automatically by sklearn's implementation
X = boston["data"]
Y = boston["target"]
names = boston["feature_names"]
rlasso = RandomizedLasso(alpha=0.025)
rlasso.fit(X, Y)
print("Features sorted by their score:")
print(sorted(zip(map(lambda x: format(x, '.4f'), rlasso.scores_), names), reverse=True))
Features sorted by their score:
输出:[('1.0000', 'RM'), ('1.0000', 'PTRATIO'), ('1.0000', 'LSTAT'), ('0.6450', 'CHAS'), ('0.6100', 'B'), ('0.3950', 'CRIM'), ('0.3800', 'TAX'), ('0.2250', 'DIS'), ('0.2000', 'NOX'), ('0.1150', 'INDUS'), ('0.0750', 'ZN'), ('0.0200', 'RAD'), ('0.0100', 'AGE')]
在上边这个例子当中,最高的3个特征得分是1.0,这表示他们总会被选作有用的特征(当然,得分会收到正则化参数alpha的影响,但是sklearn的随机lasso能够自动选择最优的alpha)。接下来的几个特征得分就开始下降,但是下降的不是特别急剧,这跟纯lasso的方法和随机森林的结果不一样。能够看出稳定性选择对于克服过拟合和对数据理解来说都是有帮助的:总的来说,好的特征不会因为有相似的特征、关联特征而得分为0,这跟Lasso是不同的。对于特征选择任务,在许多数据集和环境下,稳定性选择往往是性能最好的方法之一。
四、 sklearn.pipeline.Pipeline
我们可以使用Pipeline实现特征选择和模型训练的串行计算,使得代码看起来更加的简洁,具体的用法可以去看看sklearn的官方API。
import sklearn.pipeline.Pipeline:
clf = Pipeline([
('feature_selection', SelectFromModel(LinearSVC(penalty="l1"))),
('classification', RandomForestClassifier())
])
clf.fit(X, y)
总结:以上的这些都是本人看了几篇博客后做出的整理,其实一开始看的时候还是很迷糊的,就各种乱用,所以这里要提一下:大家一定要清楚自己的特征变量是离散的还是连续的,相对应的用到的学习模型是离散的分类模型还是回归模型,这个很重要,这之间的区别不用我多说,不能一上来就直接用各种方法尝试一遍,就算有好的效果也是立不住脚的,而且说实话,也不会有好的效果。
参考博客:
1、https://www.cnblogs.com/stevenlk/p/6543646.html
2、https://www.cnblogs.com/bonelee/p/8632866.html
3、https://ynuwm.github.io/2017/12/09/sklearn-%E7%89%B9%E5%BE%81%E6%8F%90%E5%8F%96/
4、https://www.cnblogs.com/stevenlk/p/6543628.html
5、https://baike.baidu.com/item/%E7%89%B9%E5%BE%81%E9%80%89%E6%8B%A9/4950639?fr=aladdin