tensorflow(3)---官方文档MNIST问题的实现思路解说
导语
之前我们已经搞定了tensorflow的基本实现思路,那么在本文,emmm算是复习一下吗?或者让我们为CNN做做准备,了解了解图像识别的一般流程吗?emm讲道理之前还没使用机器学习进行过图像识别的工作啊,所以,我们来看看这个MNIST的问题吧~其实也就是手写数字识别啦。
步骤
下载数据
"""Functions for downloading and reading MNIST data."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import gzip
import os
import tempfile
import numpy
from six.moves import urllib
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
from tensorflow.contrib.learn.python.learn.datasets.mnist import read_data_sets这是下载数据集的代码
import input_data # 调用input_data
mnist = input_data.read_data_sets('data/', one_hot=True)运行
所有代码所示:
import input_data # 调用input_data
mnist = input_data.read_data_sets('data/', one_hot=True)
import tensorflow as tf
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x,W) + b)
y_ = tf.placeholder("float", [None,10])
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})最后输出的结果:

0.9162即为最后的精确度,那么接下来我们将试着把这篇代码给解释清楚
分析
tf.placeholder()方法所定义的x类似于形式参数,在一开始的时候不赋值,在程序开始运行的时候再赋值。
tf.placeholder(type,shape,name),后面接的参数分别是类型,大小和名字,所以在这里锁定一的x是tf.float32的类型,行未定,列为784的矩阵。
W和b时程序自定义的两个变量(即我们的预测效果之所以越来越强是因为我们对W和b这两个变量进行迭代更新所致)
y = tf.nn.softmax(tf.matmul(x,W) + b)
y_ = tf.placeholder("float", [None,10])
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
y是使用tf.nn.softmax()所定义出来的函数,那么softmax()是什么呢?将原图像进行处理之后转化为evidence的格式之后(具体的转化方式等一下说),输入softmax()函数中,会输出该图像是各个数字的概率。
而具体的evidenci的转化格式就是
接下来定义了 y_ 用于存储真实的结果。用 y 和 y_ 结合一起可以计算交叉熵cross_entropy,数学的表达方式就是
在本博客的最大熵原理那一篇中验证了这种定义交叉熵方式的可行性,其中 y,i 是真实的结果, yi 是每一次的预测,总之这样定义确实可以达到如果如果预测与真实越接近,那么交叉熵也会越小的效果。
辣么,现在这个这个代码的目的,也就是让我们的最小化cross_entropy这个变量,通过改变W和b达到让y和y’尽可能接近的效果。
同样是使用梯度下降法来定义分类器,然后完成初始化变量等一系列初始化操作~
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)然后我们们就可以进行训练了:
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))本代码训练的第一步,随机抽取训练集也就是:
batch_xs, batch_ys = mnist.train.next_batch(100)还记得mnist是如何用input_data来定义的吗,train.nest_batch(100)应该是其中的一个方法,用来随机从data中获得数据,并以这100个随机选择的数据来作为x和y来进行梯度下降的操作。
这将这100个训练图片训练结束之后,我们使用一下语句来测试我们训练的效果:
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))correct_prediction是一个用来存储对错的张量,他的实现方法是用tf.argmax(y,1),这个方法可以返回另一串张量,每一个位置是最大值则为1,否则为0,使用tf.equal将两者进行比较,如果相同则为True,否则为False,再使用tf.case将True和false变为float即1或者0的形式,然后求平均值,也就是把所有的True加一起之后除以总的判断次数,也就是我们要的accuracy了。
但显然,这个accuracy只是表示我们用训练集所训练出来的模型再带回训练集中测试,效果好也说明不了什么,所以最后我们还用:
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})将x,y换成测试集进行判断。
大致思路如上,接下来是本人为了搞懂细节所做的一些实验~
细节
关于sess.run()
.run()是一个方法,sess同样是用tf.Session()所定义的方法,所以sess.run()的也可以写成
tf.Session().run()是一个方法的方法。
.run()里面可以接什么呢?
可以接名词:
sess.run(cross_entropy , feed_dict={x: batch_xs, y_: batch_ys})这里在定义了feed_dict,也就是定义了x,和y_这两个placeholder分别为谁的时候,就可以计算出cross_entropy了。运行这段代码

就能输出我们的交叉熵了~
然后这里总结一下,如果接名词,则接的一定时张量或者变量,不能是placeholder,因为placeholder被代码认为时要当作已知常数来处理的量,或者说代码接下来会给出定义的量,如我们的feed_dict这个量,就是在帮我们定义之前给出的placeholder。除了接名词,还可以接动词。
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})train_step,它的定义是使用梯度下降法来定义的,在我看来这就是一个等待完成的动作,而这个动作同样也可以run()来实现。我试过print它,但是输出的结果是None
关于结果更新
每次会在已有参数的基础上进行更新,所以精度讲道理是会逐渐变得越来越好的,这是我手动进行循环的结果:
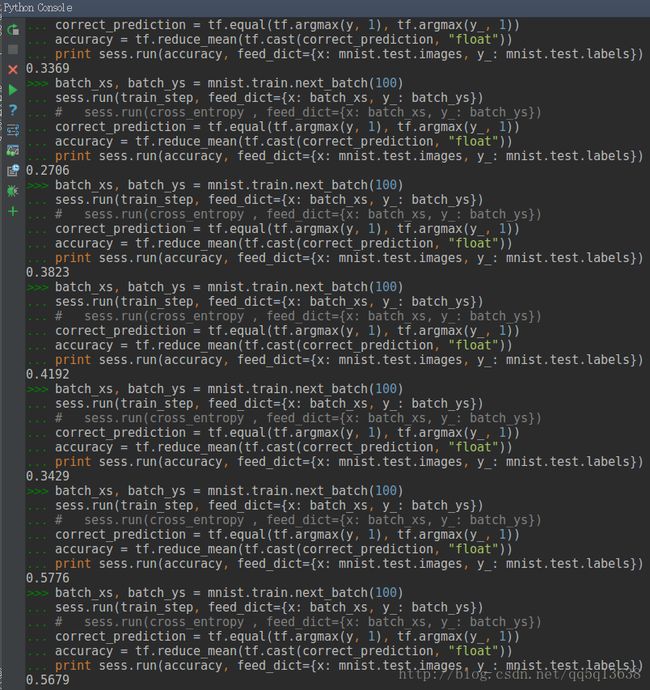
这时候如果我们想要看其中参数的变化情况,只需要,比如说我要看变量b的变化情况:
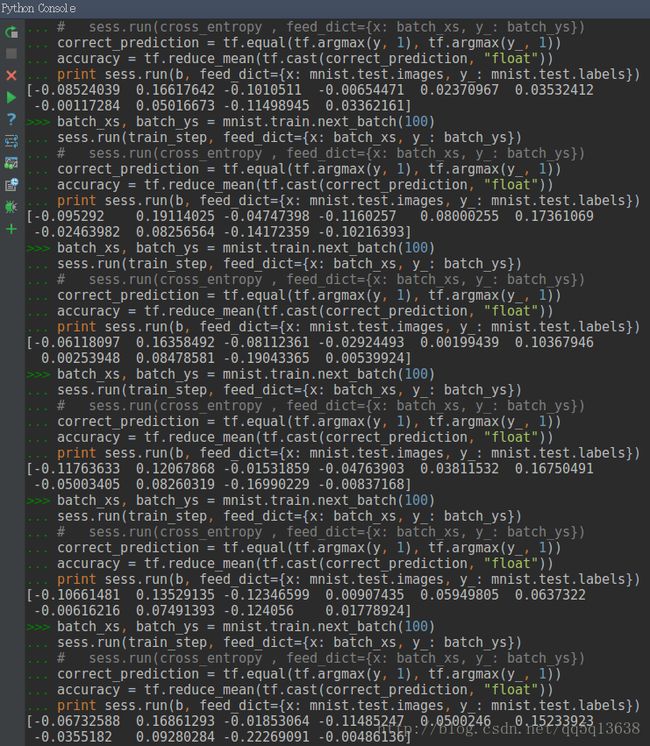
那怎么样把结果给初始化呢?这些张量之前定义的时候都是0来的吧还记得原来b的定义:
b = tf.Variable(tf.zeros([10]))这时候如果我们想要让b回去,只需要重新运行初始化的语句即可。
而且b值的改变只有当运行动作的时候才会改变,单纯sess.run()名词时没用的,只有sess.run(train_step)才会更新b数值
关于图像到底在哪里?
哎这个问题写到一半的时候网页切换一不小心关掉了,真是“`
whatever,我们可以看到一张图像在本代码中就是用x来表示的,而x的取值是使用batch_xs来赋值的,而batch_xs:
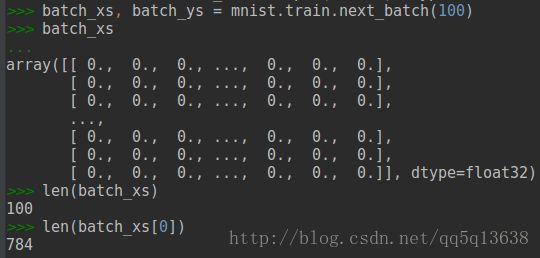
所以,batch_xs是一个包含100张图像的数据,那么batch_xs的784列是怎么来的呢?

官网告诉我是以某种方式把图片转化为数组了,那么我们现在能否把图片还原呢?
import numpy as np
forp = batch_xs[0].tolist()
pic = []
for i in range(28):
pic.append(forp[0+i*28:28+i*28])
np.savetxt('new.csv',np.array(pic),delimiter=',')用这个代码即可把第0张图片还原并存出为:

这样的形式,2333这不是手写的5吗(虽然看上去比较辣眼睛“`)
我们现在想看看mnist中对应数字的结果是不是5
在不更新的情况下,我们的输入输出:
![]()
所以,就是5啦~
结语
哎终于大概差不多好像把这个官方的demo搞懂一点点了,哎嘛本来就是想要看到数据集中的图像结果还是要我亲自写代码才能把图片还原~emmm怎么说这篇因为只是要识别数字,就直接把图片暴力破解成784个列的行向量来作为自变量来输入,但是如果我们要识别更复杂的东西比如“食物”,就不能用这样的操作来进行了吧~