【深度学习】经典网络-Alexnet复现(使用Tensorflow实现)
论文地址:http://120.52.51.18/papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
本文所包含代码GitHub地址:https://github.com/shankezh/DL_HotNet_Tensorflow
如果对机器学习有兴趣,不仅仅满足将深度学习模型当黑盒模型使用的,想了解为何机器学习可以训练拟合最佳模型,可以看我过往的博客,使用数学知识推导了机器学习中比较经典的案例,并且使用了python撸了一套简单的神经网络的代码框架用来加深理解:https://blog.csdn.net/shankezh/article/category/7279585
项目帮忙或工作机会请邮件联系:[email protected]
论文精华
关键信息提取
1.2012年ImageNet图像分类竞赛冠军网络;
2.使用了两块GPU GTX580 3GB 进行了训练;
3.网络包含了很多的不同于之前网结构的特性用来提升正确率和减少训练时间,具体细节见论文第三章(Section 3);
4.使用了一系列的特殊技巧用来防止过拟合,具体细节件论文第四章(Section 4);
5.最后成形的网络包含了5个卷积层和3个全连接层;
6.将不同分辨率图像全部变成256x256,主要做法为,对矩形图片,改变其中短边分辨率变成256,然后从改变的图像中剪裁中央部分为256x256的图像;
7.除了每张图像减去训练集合中所有图像各通道的像素的平均值,并没有使用其他的图像预处理手段;
8.使用了Local Response Normalzalion(局部响应规范化);
9.论文中提到,响应归一化层跟在第一层和第二层卷积层之后;
10.数据扩充方法1:图像变换和水平翻转图像;
11.数据扩充方法2:改变训练数据集合中RGB通道强度,加噪点到图像中;
12.论文提到,将在256x256的图像中,随机提取224x224的图像,这样就增加了数据源;
13.使用Dropout降低训练代价;
训练细节
1.优化器为momentum,冲量为0.9,学习律为0.0005,batch size 为128;
2.初始化权重层为0均值的高斯分布,标准偏差0.01;
3.初始化第2/4/5卷积层和所有全连接的偏置,为常量1,剩余层初始化偏置为常量0;
4.设置了10个训练速率,用来应对训练错误不提升的情况,初始化训练学习速率为0.01;
模型结构图

论文附图
实际结构应该为下图:

Tensorflow代码实现
说明
1.代码总体上而言遵循了论文的标准进行了复现,会有一些细微差别(比如说初始化的偏置没有遵循论文,batch size和论文不同,没有对数据集进行数据扩充)
2.训练数据使用了猫狗大战的数据,由于源数据中没有标注测试集合的标签,因此手动的从测试集合中提取了2000张图片作为猫狗的测试集合(先用训练的VGG19机器分类,然后手工修改错误的,大大的降低了工作量)
3.训练速率的改变,我是通过模型重载进行更改的,而非动态调整
4.论文中的图有错误,输入应为227x227,而非224x224,否则无法正确得出每一层的shape
代码
模型
Alexnet.py
'''
模型AlexNet
卷积层:5层
全连接层:3层
深度:8层
参数个数:60M
神经元个数:650k
分类数目:1000类
'''
def AlexNetModel_slim(inputs,num_cls=2,keep_prob = 0.5):
with tf.name_scope('reshape'):
inputs = tf.reshape(inputs,[-1,227,227,3])
with tf.variable_scope('alex_net'):
with slim.arg_scope([slim.conv2d,slim.fully_connected],
weights_initializer=tf.truncated_normal_initializer(0.0, 0.01)):
with slim.arg_scope([slim.conv2d,slim.max_pool2d],
padding = 'same',
stride = 1):
net = slim.conv2d(inputs,96,11,stride=4,padding='VALID')
# conv_vars = tf.get_collection(tf.GraphKeys.MODEL_VARIABLES,'Conv')
# tf.summary.histogram('conv_weights',conv_vars[0])
net = norm(net,depth_radius=5.0,bias=2.0,alpha=1e-4,beta=0.75)
net = slim.max_pool2d(net,3,stride=2,padding='VALID')
net = slim.conv2d(net,256,5)
net = norm(net,depth_radius=5.0,bias=2.0,alpha=1e-4,beta=0.75)
net = slim.max_pool2d(net,3,stride=2,padding='VALID')
net = slim.conv2d(net,384,3)
net = slim.conv2d(net,384,3)
net = slim.conv2d(net,256,3)
met = slim.max_pool2d(net,3,stride=2,padding='VALID')
net = slim.flatten(net)
net = slim.fully_connected(net,4096)
net = slim.dropout(net,keep_prob=keep_prob)
net = slim.fully_connected(net,4096)
net = slim.dropout(net,keep_prob=keep_prob)
net = slim.fully_connected(net,num_cls)
net = slim.softmax(net)
return net训练
Alexnet_DogCat.py
def main():
train_dir = ''
test_dir = ''
model_dir = ''
logdir = ''
num_cls = 2
is_train = False
is_load_model = True
BATCH_SZIE = 100
EPOCH_NUM = 20
ITER_NUM = 20000 # 60000 / 50
KEEP_PROB = 0.5
if utils.isLinuxSys():
train_dir = r'/DataSets/CatAndDog/train'
test_dir = r'/DataSets/CatAndDog/test'
model_dir = r'/DataSets/CatAndDog/model_file'
logdir = r'/DataSets/CatAndDog/logs/train'
if utils.isWinSys():
train_dir = r'D:\DataSets\CatAndDog\train'
test_dir = r'D:\DataSets\CatAndDog\test'
model_dir = r'D:\DataSets\CatAndDog\model_file\alexnet'
logdir = r'D:\DataSets\CatAndDog\logs\train'
train_img_list, train_label_list = pre_pro.get_dogcat_img(train_dir)
train_img_batch, train_label_batch = pre_pro.get_batch(train_img_list,train_label_list,227,227,batch_size=BATCH_SZIE,capacity=2000)
train_label_batch = tf.one_hot(train_label_batch,depth=num_cls)
test_img_list, test_label_list = pre_pro.get_dogcat_img(test_dir)
test_img_batch, test_label_batch = pre_pro.get_batch(test_img_list,test_label_list,227,227,batch_size=BATCH_SZIE,capacity=2000)
test_label_batch = tf.one_hot(test_label_batch,depth=num_cls)
inputs = tf.placeholder(tf.float32,[None,227,227,3])
labels = tf.placeholder(tf.float32,[None,num_cls])
logits = AlexNet.AlexNetModel_slim(inputs=inputs,num_cls=num_cls,keep_prob=KEEP_PROB)
train_loss = coms.loss(logits,labels)
train_eval = coms.evaluation(logits,labels)
train_optim = coms.optimizer(lr=5e-4,loss=train_loss,fun='mm')
summary_op = tf.summary.merge_all()
saver = tf.train.Saver(max_to_keep=4)
max_acc = 0.
with tf.Session() as sess:
if utils.isHasGpu():
dev = "/gpu:0"
else:
dev = "/cpu:0"
with tf.device(dev):
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
if is_train:
if is_load_model:
ckpt = tf.train.get_checkpoint_state(model_dir)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess,ckpt.model_checkpoint_path)
print('model load successful')
else:
print('model load falid')
return
n_time = time.strftime("%Y-%m-%d %H-%M", time.localtime())
logdir = os.path.join(logdir,n_time)
writer = tf.summary.FileWriter(logdir,sess.graph)
for epoch in range(EPOCH_NUM):
if coord.should_stop():
break
for step in range(ITER_NUM):
if coord.should_stop():
break
batch_train_im , batch_train_label = sess.run([train_img_batch,train_label_batch])
batch_test_im , batch_test_label = sess.run([test_img_batch,test_label_batch])
_, loss,w_summary = sess.run([train_optim,train_loss,summary_op],feed_dict={inputs:batch_train_im,labels:batch_train_label})
writer.add_summary(w_summary,(epoch * ITER_NUM + step))
print("epoch %d , step %d train end ,loss is : %f ... ..." % (epoch, step, loss))
if not is_load_model:
if epoch == 0 and step < (ITER_NUM / 3):
continue
if step % 200 == 0:
print('evaluation start ... ...')
ac_iter = int((len(test_img_list) / BATCH_SZIE))
ac_sum = 0.
for ac_count in range(ac_iter):
accuracy = sess.run(train_eval,feed_dict={inputs:batch_test_im,labels:batch_test_label})
ac_sum = ac_sum + accuracy
ac_mean = ac_sum / ac_iter
print('epoch %d , step %d , accuracy is %f'%(epoch,step,ac_mean))
if ac_mean >= max_acc:
max_acc = ac_mean
saver.save(sess, model_dir + '/' + 'dogcat' + str(epoch) + '_step' + str(step) + '.ckpt',
global_step=step + 1)
print('saving last model ...')
saver.save(sess, model_dir + '/cifar10_last.ckpt')
print('train network task was run over')
else:
model_file = tf.train.latest_checkpoint(model_dir )
saver.restore(sess, model_file)
for i in range(1,11):
name = str(i) + '.jpg'
img = cv2.imread(name)
img = cv2.resize(img,(227,227))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img / 255.
img = np.array([img])
res = sess.run(logits, feed_dict={inputs:img})
if np.argmax(res) == 0:
print('Detect ', name, ' result is dog, ','result is ',res)
elif np.argmax(res) == 1:
print('Detect ', name, ' result is cat, ','result is ',res)
except tf.errors.OutOfRangeError:
print('done trainning --epoch files run out of')
finally:
coord.request_stop()
coord.join(threads)
sess.close()pre_process.py
import tensorflow as tf
import os
import numpy as np
def get_dogcat_img(file_dir):
cls_list = ['dog','cat']
cls_img_path , cls_img_label = [],[]
for file in os.listdir(file_dir):
for index , name in enumerate(cls_list):
if name in file:
cls_img_path.append(file_dir + '/' + file)
cls_img_label.append(index)
temp = np.array([cls_img_path,cls_img_label])
temp = temp.transpose()
np.random.shuffle(temp)
img_list = list(temp[:,0])
label_list = list(temp[:,1])
label_list = [int (i) for i in label_list]
return img_list, label_list
'''
生成相同大小的批次,使用此函数将图片分批次,原因为一次性将大量图片读入内存可能会存在内存不足,同时也是性能浪费
@:param img get_cat_and_dog_files()返回的img_list
@:param label get_cat_and_dog_files()返回的label_list
@:param img_w, img_h 设置好固定的宽和高
@:param batch_size 每个batch的大小
@:param capacity 一个队列最大容量
@:return 包含图像和标签的batch
'''
def get_batch(img, label, img_w, img_h, batch_size, capacity):
# 格式化为tf需要的格式
img = tf.cast(img, tf.string)
label = tf.cast(label, tf.int32)
# 生产队列
input_queue = tf.train.slice_input_producer([img,label])
# 从队列中读取图
img_contents = tf.read_file(input_queue[0])
label = input_queue[1]
# 图像解码,不同类型图像不要混在一起
img = tf.image.decode_jpeg(img_contents, channels=3)
# 图像统一预处理,缩放,旋转,裁剪,归一化等
img = tf.image.resize_images(images=img,size=[img_h,img_w],method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
img = tf.cast(img, tf.float32) / 255. # 转换数据类型并归一化
# 图片标准化
# img = tf.image.per_image_standardization(img)
img_batch, label_batch = tf.train.batch(
[img,label],
batch_size= batch_size,
num_threads= 64,
capacity=capacity
)
# label_batch = tf.reshape(label_batch,[batch_size])
img_batch = tf.cast(img_batch, tf.float32)
return img_batch, label_batchcoms.py
# 训练函数
def optimizer(lr,loss,mom=0.9,fun = 'mm'):
with tf.name_scope('optimizer'):
if fun == 'mm':
optim = tf.train.MomentumOptimizer(learning_rate=lr,momentum=0.9).minimize(loss=loss)
elif fun == 'gdo':
optim = tf.train.GradientDescentOptimizer(learning_rate=lr).minimize(loss=loss)
elif fun == 'adam':
optim = tf.train.AdamOptimizer(learning_rate=lr).minimize(loss= loss)
else:
raise TypeError('未输入正确训练函数')
return optim
# 误差
def loss(logits, labels, fun='cross'):
with tf.name_scope('loss') as scope:
if fun == 'cross':
_loss = tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits, labels=labels)
mean_loss = tf.reduce_mean(_loss)
else:
raise TypeError('未输入正确误差函数')
tf.summary.scalar(scope + 'mean_loss', mean_loss)
return mean_loss
'''
准确率计算,评估模型
由于测试存在切片测试合并问题,因此正确率的记录放到了正式代码中
'''
def evaluation(logits,labels):
with tf.name_scope('evaluation') as scope:
correct_pre = tf.equal(tf.argmax(logits,1),tf.argmax(labels,1))
accurary = tf.reduce_mean(tf.cast(correct_pre,'float'))
tf.summary.scalar(scope + 'accuracy:', accurary)
return accurary结果
三天利用下班时间回家训练,大概加起来花费了10个小时左右,测试集中最高正确率为98%,其中loss的变化如下图:
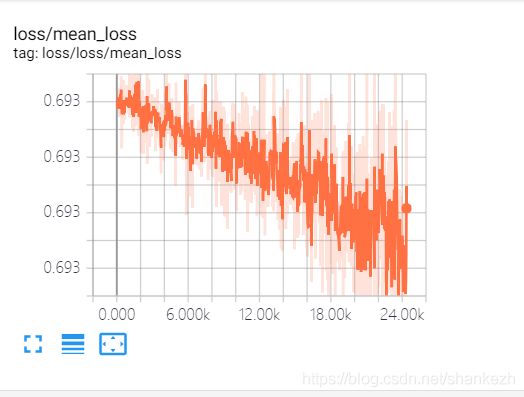


硬件使用了GTX1070Ti,由于是三天内进行了两次断点恢复训练,因此有三张loss曲线,loss值从最开始的0.693一路下降到0.005最低.
训练的模型文件会后续传到网盘,可以验证本模型对猫狗图片的识别效果.
为了测试我的模型训练是否真的不错,我从百度上下了10张图片,其中4张狗狗,4张猫猫,1张人,1张猫狗合影,如下截图:

可以看到,1,2,3,4编号为狗狗,其中3号为动漫狗,5,6,7,8,为猫,9号为人,10号为猫狗合集,经过运行检测,结果如下:
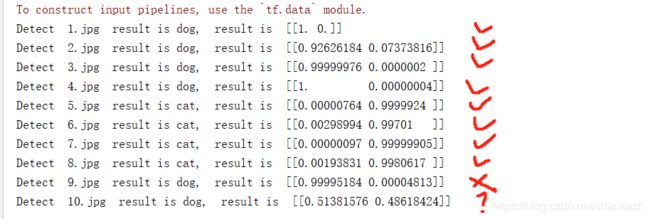
上图结果,说明前八张全部分类完成,甚至连3号动漫狗也可以正确的识别出来,而第9图片错误的识别为狗,因为我们只是二分类,没对人训练过,因此网络认为这是狗狗,所以并不能归到模型错误中,因为我们并没有训练模型识别猫狗之外的生物,第十张图可以看到,结果显示,猫狗检测都具有相应的分数,且结果分数差距并不大,说明网络对其中两个类别都有判别到,只是我们单一选择了最大可能猫而已。此次模型在我的测试集上准确率为98%,而这里随机找的网络图片测试等同于全部正确。
至此,AlexNet论文复现完成.
后续我会上传我训练的权重文件和数据集到网盘中。
权重文件,百度云地址为链接:https://pan.baidu.com/s/1BdMZYvkiYT9Fts0dLIgrog
提取码:0rmi