Two-Stream Convolutional Networks for Action Recognition in Videos算法笔记
论文:Two-Stream Convolutional Networks for Action Recognition in Videos
链接:https://arxiv.org/abs/1406.2199
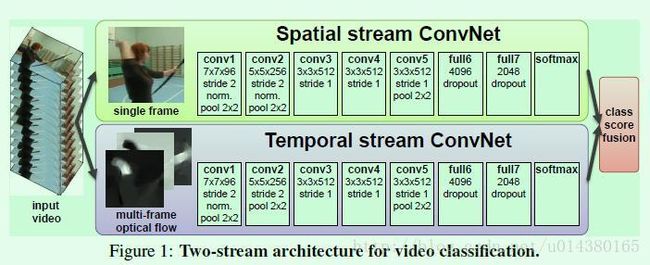
这篇文章是NIPS 2014年提出一个two stream网络来做video action的分类,比较经典。two stream表示两个并行的网络:spatial stream convnet 和 temporal stream convnet. 这两个并行网络的作用是:The spatial stream performs action recognition from still video frames, whilst the temporal stream is trained to recognise action from motion in the form of dense optical flow.
Figure1是two stream convnet的示意图。其中spatial stream convnet网络的输入是静态图像,该网络是一个分类网络,用来识别行为。temporal stream convnet输入是multi-frame optical flow,optical flow是从video中提取的特征信息。作者在总结中提到对于temporal stream convnet,用optical flow(翻译过来是光流信息)作为输入的效果要远远优于用raw stacked frame(就是简单的一系列帧)作为输入。
可以看出optical flow是文章的关键词,那么什么是optical flow?可以看原文的一段解释如下截图。

所以optical flow是由一些displacement vector fields(每个vector用dt表示)组成的,其中dt是一个向量,表示第t帧的displacement vector,是通过第t和第t+1帧图像得到的。dt包含水平部分dtx和竖直部分dty,可以看Figure2中的(d)和(e)。因此如果一个video有L帧,那么一共可以得到2L个channel的optical flow,然后才能作为Figure1中temporal stream convnet网络的输入。
FIugre2中的(a)和(b)表示连续的两帧图像,(c)表示一个optical flow,(d)和(e)分别表示一个displacement vector field的水平和竖直两部分。

所以如果假设一个video的宽和高分别是w和h,那么Figure1中temporal stream convnet的输入维度应该是下面这样的。其中τ表示任意的一帧。
![]()
那么怎么得到Iτ?文章主要介绍了两种Iτ的计算方式,分别命名为optical flow stacking和trajectory stacking,这二者都可以作为前面temporal stream convnet网络的输入,接下来依次介绍。
optical flow stacking
式子1列出了分别得到水平和竖直方向的Iτ的计算公式,其中(u,v)表示任意一个点的坐标。因此 Iτ(u,v,c) 存的就是(u,v)这个位置的displacement vector。原文:For an arbitrary point (u,v), the channels Iτ(u,v,c); c = [1; 2L] encode the motion at that point over a sequence of L frames。如Figure3的左图所示。

trajectory stacking
式子2是关于如何得到Iτ,其中Pk表示k-th point along the trajectory。因此 Iτ(u,v,c) 存的就是vectors sampled at the locations Pk along the trajectory。如Figure3的右图所示。
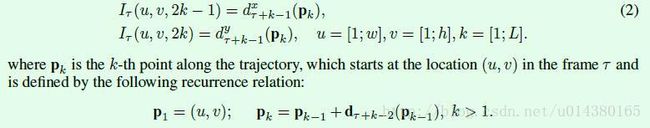
Figure3分别介绍了optical flow stacking和trajectory stacking。

spatial stream convnet因为输入是静态的图像,因此其预训练模型容易得到(一般采用在ImageNet数据集上的预训练模型),但是temporal stream convnet的预训练模型就需要在视频数据集上训练得到,但是目前能用的视频数据集规模还比较小(主要指的是UCF-101和HMDB-51这两个数据集,训练集数量分别是9.5K和3.7K个video)。因此作者采用multi-task的方式来解决。怎么做呢?首先原来的网络(temporal stream convnet)在全连接层后只有一个softmax层,现在要变成两个softmax层,一个用来计算HDMB-51数据集的分类输出,另一个用来计算UCF-101数据集的分类输出,这就是两个task。这两条支路有各自的loss,最后回传loss的时候采用的是两条支路loss的和。
实验结果:
Table1是两个网络的实验结果,数据集都是UCF-101,该数据集包含13K的videos,平均每个video包含180帧图像,有101个action class。另外multi-task有用到HMDB-51数据集,其包含6.8K的video,有51个action class。(a)是spatial stream convnet,主要对比了从头开始训练(from scratch)和在预训练模型上做fine tune的差别(pre-trained+fine tuning表示用预训练网络的参数初始化所有层,然后对所有层fine tune;pre-trained+last layer同样是用预训练网络的参数初始化所有层,但是只对最后一层fine tune,也就是前面那些层的参数在初始化后固定不变)。从实验结果可以看出直接在UCF-101数据集上从头开始训练容易过拟合。在后面的实验中作者采用第三种做法,也就是在预训练模型的基础上只fine tune最后一层的参数。(b)表示temporal stream convnet的几种不同类型输入的差别,训练都是从头开始(from scratch)。其中optical flow stacking和trajectory stacking在前面都介绍过了,注意L参数对结果的影响,第一行中L=1相当于只给了一帧图像,另外在后面的实验中作者采用L=10。可以看出optical flow stacking的效果要优于trajectory stacking。最后一行的bi-dir表示bi-directional optical flow,感兴趣的可以看原文。通过对比(a)和(b)可以看出temporal stream convnet的效果要优于spatial stream convnet,这说明对于action recognition而言,motion information的重要性。
另外,文中的一句话写得很好:This shows that while multi-frame information is important, it is also important to present it to a ConvNet in an appropriate manner. 翻译过来就是:都知道是那个理,就看你怎么实现了。哈哈

Table2是multi task的实验结果。主要的修改内容包括:(i) fine-tuning a temporal network pre-trained on UCF-101; (ii) adding 78 classes from UCF-101, which are manually selected so that there is no intersection between these classes and the native HMDB-51 classes; (iii) using the multi-task formulation to learn a video representation, shared between the UCF-101 and
HMDB-51 classification tasks. Table2中的实验正是对比这几个修改的效果。

Table3是two-stream convnet的不同构建方式的实验结果对比。几个结论:(i) temporal and spatial recognition streams are complementary, as their fusion significantly improves on both (6% over temporal and 14% over spatial nets); (ii) SVM-based fusion of softmax scores outperforms fusion by averaging; (iii) using bi-directional flow is not beneficial in the case of ConvNet fusion; (iv) temporal ConvNet, trained using multi-task learning, performs the best both alone and when fused with a spatial net.

Table4是two stream convnet和其他算法的对比。
