白话机器学习算法理论+实战之关联规则
1. 写在前面
如果想从事数据挖掘或者机器学习的工作,掌握常用的机器学习算法是非常有必要的,比如我之前写过的一篇十大机器学习算法的小总结,在这简单的先捋一捋, 常见的机器学习算法:
- 监督学习算法:逻辑回归,线性回归,决策树,朴素贝叶斯,K近邻,支持向量机,集成算法Adaboost等
- 无监督算法:聚类,降维,关联规则, PageRank等
为了详细的理解这些原理,曾经看过西瓜书,统计学习方法,机器学习实战等书,也听过一些机器学习的课程,但总感觉话语里比较深奥,读起来没有耐心,并且理论到处有,而实战最重要, 所以在这里想用最浅显易懂的语言写一个白话机器学习算法理论+实战系列。
个人认为,理解算法背后的idea和使用,要比看懂它的数学推导更加重要。idea会让你有一个直观的感受,从而明白算法的合理性,数学推导只是将这种合理性用更加严谨的语言表达出来而已,打个比方,一个梨很甜,用数学的语言可以表述为糖分含量90%,但只有亲自咬一口,你才能真正感觉到这个梨有多甜,也才能真正理解数学上的90%的糖分究竟是怎么样的。如果算法是个梨,本文的首要目的就是先带领大家咬一口。另外还有下面几个目的:
- 检验自己对算法的理解程度,对算法理论做一个小总结
- 能开心的学习这些算法的核心思想, 找到学习这些算法的兴趣,为深入的学习这些算法打一个基础。
- 每一节课的理论都会放一个实战案例,能够真正的做到学以致用,既可以锻炼编程能力,又可以加深算法理论的把握程度。
- 也想把之前所有的笔记和参考放在一块,方便以后查看时的方便。
学习算法的过程,获得的不应该只有算法理论,还应该有乐趣和解决实际问题的能力!
今天是白话机器学习算法理论+实战的第二篇,关联规则挖掘的学习, 通过今天的学习,应该可以掌握关联规则挖掘算法apriori算法和FPgrowth的基本原理,并且会通过后面的小实战掌握算法的运用。
大纲如下:
- 搞懂关联规则中的几个重要概念(频繁项集,支持度,置信度,提升度)
- 关联规则算法之Apriori算法
- 关联规则算法之FP-Growth算法
- 项目实战(通过几个小例子说明如何使用mlxtend进行数据关联分析,然后再介绍一个工具包efficient_apriori,并基于这个工具包进行“导演是如何选择演员的”一个项目实战)
OK, let’s go !
2. 关联规则挖掘:我打算还是从啤酒和尿布开始谈起:
为了避免后面的故事有点晦涩,先讲讲数据挖掘界的经典案例:啤酒和尿布的故事吧:
在美国有婴儿的家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布。父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去不相干的商品经常会出现在同一个购物篮的现象。如果这个年轻的父亲在卖场只能买到两件商品之一,则他很有可能会放弃购物而到另一家商店,直到可以一次同时买到啤酒与尿布为止。沃尔玛发现了这一独特的现象,开始在卖场尝试将啤酒与尿布摆放在相同的区域,让年轻的父亲可以同时找到这两件商品,并很快地完成购物;而沃尔玛超市也可以让这些客户一次购买两件商品、而不是一件,从而获得了很好的商品销售收入,这就是“啤酒与尿布”故事。
看完这个故事的感想是啥? 是不是很奇怪啊? 啤酒和尿布这两个听起来完全不相关的东西,竟然能够产生关联,并且通过挖掘两个其中的关系,可以使得销售更好,这背后起作用的就是关联规则的挖掘。
只要掌握了这项技能,你不仅可以根据超市里的客户商品明细表,挖掘出哪些商品放在一起可以增大销售,还可以分析出银行理财产品的交叉预售,每个手机用户的APP之间的关联,还可以自己爬取电影数据,分析关联,得到导演喜欢用哪些演员,以及哪个演员常和哪个演员经常在一块拍戏等(后面的实战里面都有涉及,这叫做一通百通)
哈哈,是不是开始有诱惑力了呢? 但需要一些知识作为铺垫,比如,到底什么是关联规则呢?
- 关联规则这个概念,最早是由 Agrawal 等人在 1993 年提出的。
- 关联规则挖掘可以让我们从数据集中发现项与项(item 与 item)之间的关系,它在我们的生活中有很多应用场景,“购物篮分析”就是一个常见的场景,这个场景可以从消费者交易记录中发掘商品与商品之间的关联关系,进而通过商品捆绑销售或者相关推荐的方式带来更多的销售量。
但是在学习具体算法之前,先搞懂几个概念,因为这些算法选关联规则时候,都是先依赖着这些标准。
搞懂关联规则中的几个概念
为了白话一点,还是通过例子来介绍吧,看一个超市里面购物的例子:

2.1 频繁项集
频繁项集是指那些经常出现在一起的物品,例如上图的{啤酒、尿布、牛奶},从上面的数据集中也可以找到尿布->啤酒的关联规则,这意味着有人买了尿布,那很有可能他也会购买啤酒。那如何定义和表示频繁项集和关联规则呢?这里引入支持度和可信度(置信度)。
2.2 支持度
支持度是个百分比,它指的是某个商品组合出现的次数与总次数之间的比例。支持度越高,代表这个组合出现的频率越大。
比如上面的例子里面,我们看到“牛奶”出现了4次,那么5笔订单中,“牛奶”的支持度就是4/5=0.8。
同理, 我们看到"牛奶+面包"出现了3次,那么这5笔订单里面"牛奶+面包" 的支持度就是3/5 = 0.6
2.3 置信度
它指的就是当你购买了商品 A的条件下,会有多大的概率购买商品 B,这其实是一个条件概率。
- 置信度(牛奶→啤酒)=2/4=0.5,代表如果你购买了牛奶,会有0.5的概率会购买啤酒。
- 置信度(啤酒→牛奶)=2/3=0.67,代表如果你购买了啤酒,会有0.67的概率会购买。
在上面这个例子中:我们看到在4次购买了牛奶的情况下,有2次购买了啤酒,所以(牛奶 -> 啤酒)的置信度就是2/4 = 0.5。
同理, 3 次购买啤酒的情况下,有 2 次购买了牛奶,所以置信度(啤酒→牛奶)=0.67。
2.3 提升度
我们在做商品推荐的时候,重点考虑的是提升度,因为提升度代表的是“商品 A 的出现,对商品 B 的出现概率提升的”程度。
还是看上面的例子,如果我们单纯看置信度 (可乐→尿布)=1,也就是说可乐出现的时候,用户都会购买尿布,那么当用户购买可乐的时候,我们就需要推荐尿布么?
实际上,就算用户不购买可乐,也会直接购买尿布的,所以用户是否购买可乐,对尿布的提升作用并不大。(也就是说,没有可乐出现的地方,用户也会买尿布,或者说不要根据冷门物品去推荐热门物品)
我们可以用下面的公式来计算商品 A 对商品 B 的提升度:
提升度 (A→B)= 置信度 (A→B) / 支持度 (B)
这个公式是用来衡量 A 出现的情况下,是否会对 B 出现的概率有所提升。
所以提升度有三种可能:
- 提升度 (A→B)>1:代表有提升;
- 提升度 (A→B)=1:代表有没有提升,也没有下降;
- 提升度 (A→B)<1:代表有下降。
关于关联规则挖掘,上面的几个概念也比较关键了,基于这几个关键,下面才有了几个挖掘算法,比较著名的也就是Apriori算法和FP—Growth算法了。下面具体看看。
3. Apriori的工作原理
明白了关联规则中支持度、置信度和提升度这几个重要概念,我们来看下 Apriori 算法是如何工作的。
Apriori 算法其实就是查找频繁项集 (frequent itemset) 的过程。而频繁项集的定义,需要最小支持度,大于等于最小支持度的项集就是频繁项集。项集这个概念,英文叫做 itemset,它可以是单个的商品,也可以是商品的组合。还是用例子来说明一下怎么算:
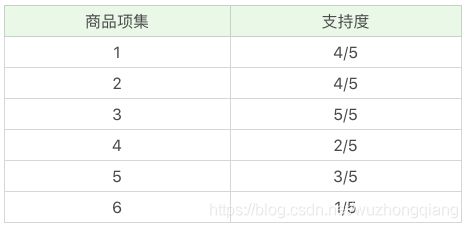
我们把上面案例中的商品用 ID 来代表,牛奶、面包、尿布、可乐、啤酒、鸡蛋的商品 ID 分别设置为 1-6,上面的数据表可以变为:

假设我随机指定最小支持度是 50%,也就是 0.5。看下Apriori算法是怎么运算的。
首先,我们先计算单个商品的支持度,也就是得到 K=1 项的支持度:
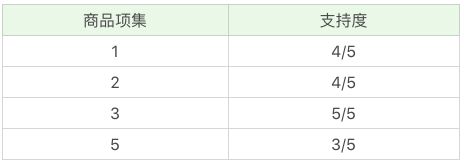
因为最小支持度是 0.5,所以你能看到商品 4、6 是不符合最小支持度的,不属于频繁项集,于是经过筛选商品的频繁项集就变成:
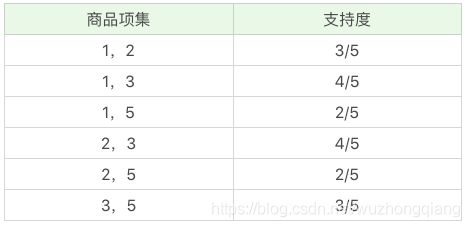
在这个基础上,我们将商品两两组合,得到 k=2 项的支持度:
我们再筛掉小于最小值支持度的商品组合,可以得到:
我们再将商品进行 K=3 项的商品组合,可以得到:
根据先验性质频繁项集的所有非空子集也一定是频繁的 ,所以,这里的2, 3, 5的二项非空子集为{2,3},{2,5},{3,5}, 只有{2,3}是频繁的, 1,2,5也是同理, 所以根据我们的先验性质, 我们就可以排除掉后两个, 当然这里根据最小值支持度也可以筛掉小于最小值支持度的商品组合,可以得到:



通过上面这个过程,我们可以得到 K=3 项的频繁项集{1,2,3},也就是{牛奶、面包、尿布}的组合。
上面模拟了一遍整个 Apriori 算法的流程,下面总结下 Apriori 算法的递归流程:
- K=1,计算 K 项集的支持度;
- 筛选掉小于最小支持度的项集;
- 如果项集为空,则对应 K-1 项集的结果为最终结果。
否则 K=K+1,重复 1-3 步。
但是Apriori 在计算的过程中有以下几个缺点:
- 可能产生大量的候选集。因为采用排列组合的方式,把可能的项集都组合出来了;
- 每次计算都需要重新扫描数据集,来计算每个项集的支持度。
所以 Apriori 算法会浪费很多计算空间和计算时间,为此人们提出了 FP-Growth 算法,它的特点是:
- 创建了一棵 FP 树来存储频繁项集。在创建前对不满足最小支持度的项进行删除,减少了存储空间。我稍后会讲解如何构造一棵 FP 树;
- 整个生成过程只遍历数据集 2 次,大大减少了计算量。
下面来看看FP-Growth算法。
四、Apriori的改进算法:FP-Growth算法
频繁项集挖掘分为构建 FP 树,和从 FP 树中挖掘频繁项集两步。
- 构建 FP 树
构建 FP 树时,首先统计数据集中各个元素出现的频数,将频数小于最小支持度的元素删除,然后将数据集中的各条记录按出现频数排序,剩下的这些元素称为频繁项;
接着,用更新后的数据集中的每条记录构建 FP 树,同时更新头指针表。头指针表包含所有频繁项及它们的频数,还有每个频繁项指向下一个相同元素的指针,该指针主要在挖掘 FP 树时使用。
下面看看例子:
统计商品的支持度,去掉不频繁的项:
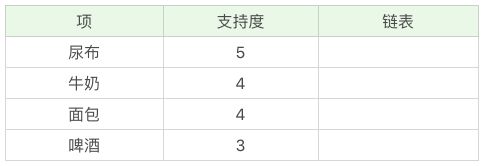
然后排序:

下面开始构建FP树的详细过程:
- 扫描编号1:
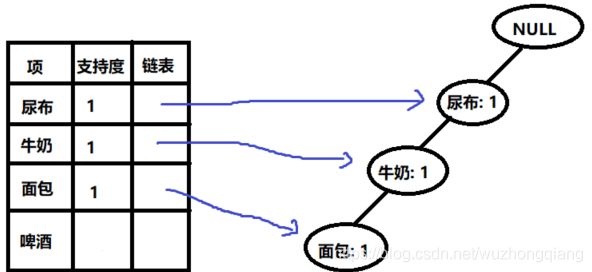
- 扫描编号2

- 扫描编号3
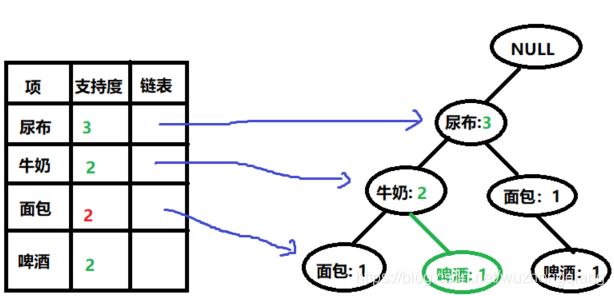
- 扫描编号4

- 扫描编号5

上面就是完整的FP建树过程。最终版如下:
- 通过FP树挖掘频繁项集
到这里,我们就得到了一个存储频繁项集的 FP 树,以及一个项头表。我们可以通过项头表来挖掘出每个频繁项集。
具体的操作会用到一个概念,叫“条件模式基”,它指的是以要挖掘的节点为叶子节点,自底向上求出 FP 子树,然后将 FP 子树的祖先节点设置为叶子节点之和。
我以“啤酒”的节点为例,从 FP 树中可以得到一棵 FP 子树,将祖先节点的支持度记为叶子节点之和,得到:

你能看出来,相比于原来的 FP 树,尿布和牛奶的频繁项集数减少了。这是因为我们求得的是以“啤酒”为节点的 FP 子树,也就是说,在频繁项集中一定要含有“啤酒”这个项。你可以再看下原始的数据,其中订单 1{牛奶、面包、尿布}和订单 5{牛奶、面包、尿布、可乐}并不存在“啤酒”这个项,所以针对订单 1,尿布→牛奶→面包这个项集就会从 FP 树中去掉,针对订单 5 也包括了尿布→牛奶→面包这个项集也会从 FP 树中去掉,所以你能看到以“啤酒”为节点的 FP 子树,尿布、牛奶、面包项集上的计数比原来少了 2。
条件模式基不包括“啤酒”节点,而且祖先节点如果小于最小支持度就会被剪枝,所以“啤酒”的条件模式基为空。同理,我们可以求得“面包”的条件模式基为:
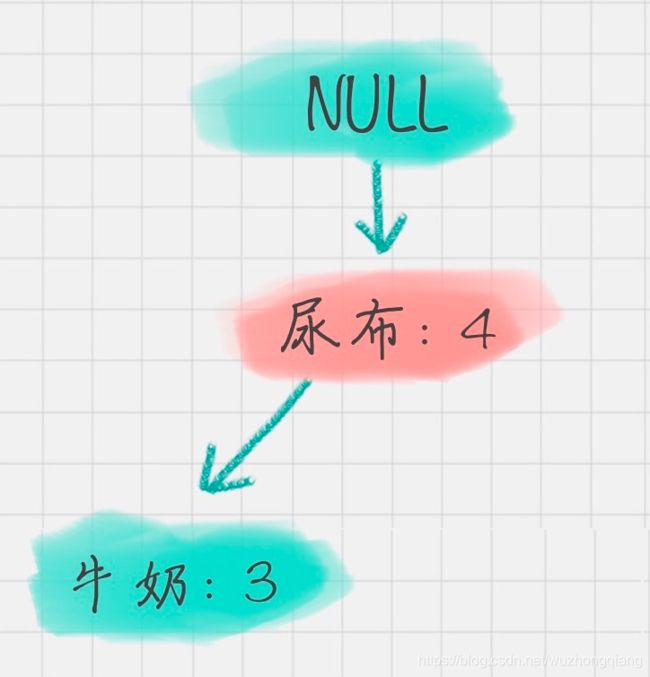
所以可以求得面包的频繁项集为{尿布,面包},{尿布,牛奶,面包}。同样,我们还可以求得牛奶,尿布的频繁项集,这里就不再计算展示。
这就是FPGrowth的工作原理了。
五、项目实战前的热身
这里是项目实战前的热身,在这里主要说一下如何通过工具包使用Apriori算法进行购物篮的分析(调用Apriori算法的库有两个,这里都分别使用一下,并说一下区别),然后把购物篮分析的这个思想迁移到超市订单上以及银行理财产品的交叉预售和APP的关联挖掘上。这些任务基本上相似。
5.1 购物篮的商品分析
首先构造数据集:
data = [['牛奶','面包','尿布'],
['可乐','面包', '尿布', '啤酒'],
['牛奶','尿布', '啤酒', '鸡蛋'],
['面包', '牛奶', '尿布', '啤酒'],
['面包', '牛奶', '尿布', '可乐']]
实现Apriori算法的,好多方式,这里介绍两种:
- 利用mlxtend包里面的Apriori算法进行数据关联分析
如果是使用这个包的话, apriori和association_rules一块使用的,并且这个对处理的数据的格式又要求(必须是宽表的格式)
先导入如下:
import pandas as pd
from mlxtend.frequent_patterns import apriori, association_rules
from mlxtend.preprocessing import TransactionEncoder
TransactionEncoder是进行数据转换中的,需要先将上面的data数据转成宽表的形式,何谓宽表,下面的这种:
"""数据转换"""
transEn = TransactionEncoder()
oht_ary = transEn.fit_transform(data)
new_data = pd.DataFrame(oht_ary, columns=transEn.columns_)
new_data
数据就变成了下面的这个样子,所谓宽表,就是把所有的商品都放在列上,每一条购买记录,如果买了该商品,相应的地方就是1,否则就是0.

只有上面这样的数据,apriori才能处理,下面就很简单了。两步搞定:
- 第一步:计算频繁项集,在这里可以定义最小支持度进行筛选频繁项集:
"""计算频繁项集"""
frequent_itemset = apriori(new_data, min_support=0.5, use_colnames=True)
frequent_itemset
结果如下:

- 第二步:挖取关联规则, 这里的准则部分可以使用置信度(confidence),或者是提升度(lift)
rules = association_rules(frequent_itemset, metric='confidence', min_threshold=1)
rules

这里就挖掘出了关联规则{啤酒} -> {尿布}, {牛奶} -> {尿布}, {面包} -> {尿布}, {牛奶, 面包} -> {尿布}。
下面小总一下这种方式:
这种方式一般会用三个函数:
- TransactionEncoder: 需要把数据转成宽表的形式
- apriori(): 这里面需要指定最小支持度
- association_rules(): 这里面指定筛选准则(置信度或者提升度或者支持度都可以)
优点:最后显示的关联规则中,支持度,置信度,提升度等信息非常详细,一目了然。
缺点:数据有特殊的规则要求,处理起来比较麻烦,并且用关联规则那块两个函数分开,用起来麻烦一些。
- efficient-apriori工具包
这个包使用起来简单一些,只需要一行代码就可同时把频繁项集合关联规则找出来,并且数据不用特殊的处理。
itemsets, rules = apriori(data, min_support, min_confidence)
其中 data 是我们要提供的数据集,它是一个 list 数组类型。min_support 参数为最小支持度,在 efficient-apriori 工具包中用 0 到 1 的数值代表百分比,比如 0.5 代表最小支持度为 50%。min_confidence 是最小置信度,数值也代表百分比,比如 1 代表 100%。
下面用这个包实现以下:
from efficient_apriori import apriori
# 设置数据集
data = [('牛奶','面包','尿布'),
('可乐','面包', '尿布', '啤酒'),
('牛奶','尿布', '啤酒', '鸡蛋'),
('面包', '牛奶', '尿布', '啤酒'),
('面包', '牛奶', '尿布', '可乐')]
# 挖掘频繁项集和频繁规则
itemsets, rules = apriori(data, min_support=0.5, min_confidence=1)
print(itemsets)
print(rules)
结果如下(和上面产生的关联规则一样):

这个的优点是使用起来简单,并且efficient-apriori 工具包把每一条数据集里的项式都放到了一个集合中进行运算,并没有考虑它们之间的先后顺序。因为实际情况下,同一个购物篮中的物品也不需要考虑购买的先后顺序。
而其他的 Apriori 算法可能会因为考虑了先后顺序,出现计算频繁项集结果不对的情况。所以这里采用的是 efficient-apriori 这个工具包。
5.2 思想迁移以下,完成其他的例子
上面的这个关联规则方式可以迁移以下,完成许多其他的任务,比如超市中的真实订单数据,银行理财产品交叉预售,手机APP之间的关联等。 怎么迁移一下呢? 主要是数据的处理方式: 如何把普通的数据转成宽表的形式。
5.2.1 超市订单的真实数据
超市订单的数据data一般长这样:
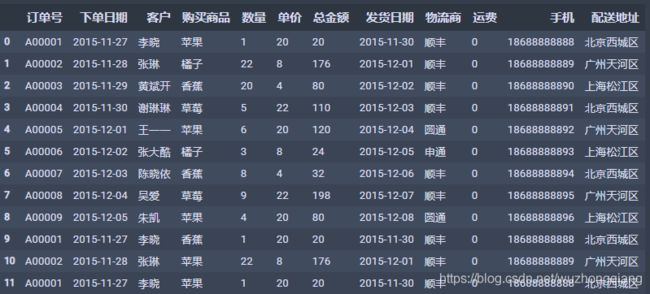
这种数据的话,需要转成宽表,但是再转宽表之前,需要先分类汇总一下:下面的一行代码
new_data = data.groupby(['订单号', '购买商品'])['数量'].sum().unstack().reset_index().fillna(0).set_index('订单号')
new_data
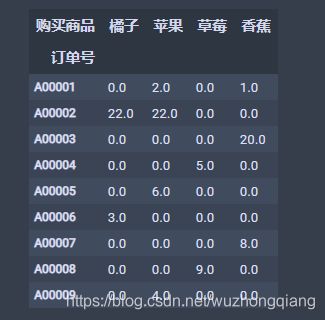
下面再把数值映射一下,就成了宽表的形式:
def encode_unit(x):
if x <= 0:
return 0
if x >=1 :
return 1
new_data = new_data.applymap(encode_unit)
new_data

这就是宽表的形式了,后面和购物篮分析的一样了,计算频繁项集,挖掘关联规则:
frequent_itemset = apriori(new_data, min_support=0.5, use_colnames=True)
rules = association_rules(frequent_itemset, metric='confidence', min_threshold=1)
5.2.2 银行理财产品交叉预售
bank数据长这样:

其实和上面的那个差不多,也是先分类汇总 -> 转成宽表的形式 -> 挖掘
bankset = bank.groupby(['CSR_ID', 'FIN_PROD']).size().unstack().reset_index().set_index('CSR_ID').fillna(0)
bank_data = bankset.applymap(encode_unit) # 这个函数见上面
bank_data
最后成这个样子,再和上面一样的分析方式

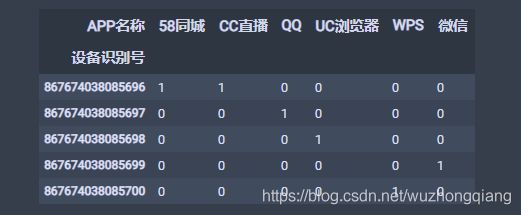
5.2.3 手机APP之间的关联
APP数据长这样:

看了这个是不是懂了迁移的方式了,先根据设备识别号,APP名称汇总,然后转成宽表的形式,然后进行挖掘。
app_new = app.groupby(['设备识别号', 'APP名称']).size().unstack().fillna(0)
app_data = app_new.applymap(encode_unit)
六、项目实战 - 导演是如何选择演员的
这个是通过Apriori算法进行关联规则挖掘,分析出导演一般喜欢哪些演员,哪个演员一般和哪个演员在一块演电影。
这里用的导演是宁浩(你也可以用别的), 使用的数据集的格式如下:(前面是宁浩导演的电影的名称,后面是里面的演员名称。)
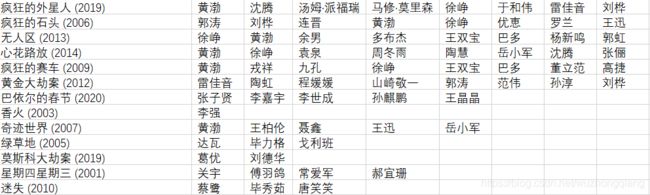
关于这个数据,需要使用爬虫技术,去https://movie.douban.com搜索框中输入导演姓名,比如“宁浩”。

关于爬虫技术的编写,这里不多说,之前写过一个Python爬虫快速入门,完全可以解决这里的数据爬取问题。下面只给出代码:
"""下载某个导演的电影数据集"""
def dowloaddata(director):
# 浏览器模拟
driver = webdriver.Chrome('C:/Users/ZhongqiangWu/AppData/Local/Google/Chrome/Application/chromedriver')
# 写入csv文件
file_name = './' + director + '.csv'
out = open(file_name,'w', newline='', encoding='utf-8-sig')
csv_write = csv.writer(out, dialect='excel')
flags = []
"""下载某个指定页面的数据"""
def download(request_url):
driver.get(request_url)
time.sleep(1)
html = driver.find_element_by_xpath("//*").get_attribute("outerHTML")
html = etree.HTML(html)
# 设置电影名称,导演演员的XPATH
movie_lists = html.xpath("/html/body/div[@id='wrapper']/div[@id='root']/div[1]//div[@class='item-root']/div[@class='detail']/div[@class='title']/a[@class='title-text']")
name_lists = html.xpath("/html/body/div[@id='wrapper']/div[@id='root']/div[1]//div[@class='item-root']/div[@class='detail']/div[@class='meta abstract_2']") # 获取返回的数据个数
# 获取返回的数据个数
num = len(movie_lists)
if num > 15: # 第一页会有16条数据, 第一条是导演的介绍
# 默认第一个不是,所以需要去掉
movie_lists = movie_lists[1:]
name_lists = name_lists[1:]
for (movie, name_list) in zip(movie_lists, name_lists):
# 会存在数据为空的情况
if name_list.text is None:
continue
print(name_list.text)
names = name_list.text.split('/')
# 判断导演是否为指定的director
if names[0].strip() == director and movie.text not in flags:
# 将第一个字段设置为电影名称
names[0] = movie.text
flags.append(movie.text)
csv_write.writerow(names)
if num >=14: # 有可能一页会有14个电影
# 继续下一页
return True
else:
# 没有下一页
return False
# 开始的ID为0, 每页增加15个
base_url = 'https://movie.douban.com/subject_search?search_text='+director+'&cat=1002&start='
start = 0
while start < 10000: # 最多抽取10000部电影
request_url = base_url + str(start)
# 下载数据,并返回是否有下一页
flag = download(request_url)
if flag:
start = start + 15
else:
break
out.close()
print('finished')
"""调用上面的函数"""
directorname = '宁浩'
dowloaddata(directorname)
下面进行关联规则挖掘,用第二种方式:
director = '宁浩'
file_name = './'+director+'.csv'
lists = csv.reader(open(file_name, 'r', encoding='utf-8-sig'))
# 数据加载
data = []
for names in lists:
name_new = []
for name in names:
# 去掉演员数据中的空格
name_new.append(name.strip())
data.append(name_new[1:])
# 挖掘频繁项集和关联规则
itemsets, rules = apriori(data, min_support=0.3, min_confidence=0.8)
print(itemsets)
print(rules)
结果如下:

你能看出来,宁浩导演喜欢用徐峥和黄渤,并且有徐峥的情况下,一般都会用黄渤。你也可以用上面的代码来挖掘下其他导演选择演员的规律。
六、总结
今天用了一天的时间,学习了一下关联规则挖掘,这里的知识浅层的不是太多,上面的这些足够用,但是只能够入门的,apriori和FPgrowth的原理希望能理解。 如果想深层次的学习这块,请查阅其他资料吧。关联规则可以用到推荐系统的相关方向。
最后就是感谢一下陈旸老师,听了他的《数据分析实战45讲》之后,感觉不仅让之前学习的算法理论变得更加的真实,并且还能够活学活用,还能get到认知和思维,哈哈,推荐。
参考资料:
- 极客时间数据分析实战45讲(上面网格图片的出处和实践项目都是摘自于此)
- 关联规则挖掘
- 频繁项集与关联规则 FP-growth 的原理和实现
- 数据分析实战
什么,还没看够? 哈哈,可以看看其他的系列,也同样有趣又能学习到知识
- 白话机器学习算法理论+实战之决策树 - 帮你搞定相亲选择的烦恼
- 白话机器学习算法理论+实战之PageRank算法 - 帮你分析与你对象交往的人员之间的关系紧密程度
- 白话机器学习算法理论+实战之AdaBoost算法 - 带你实现三个臭皮匠顶个诸葛亮的故事
- 白话机器学习算法理论+实战之朴素贝叶斯 - 帮你获得上帝的视角
- 白话机器学习算法理论+实战之支持向量机(SVM) - 教你检测是否有乳腺癌
- 白话机器学习算法理论+实战之K近邻算法 - 教你识别手写数字
- 白话机器学习算法理论+实战之KMearns聚类算法 - 帮你进行图像分割
- 白话机器学习算法理论+实战之EM聚类 - 带你走进王者荣耀英雄的聚类
- 白话机器学习算法理论+实战之PCA降维 - 带你玩一下人脸识别的降维