小甲鱼笔记:数据结构——四大逻辑结构,算法,时间复杂度和空间复杂度
Fighting!!!再学一遍数据结构!
一、绪论
-
什么是数据结构?
数据结构是一门研究非数值的程序设计问题中的操作对象,以及它们之间的关系和操作等相关问题的学科。程序设计=数据结构+算法数据结构即为
关系,数据元素相互之间存在一种或多种特定关系集合 -
逻辑结构和物理结构
数据结构分为逻辑结构和物理结构。
逻辑结构:是指数据对象中数据元素之间的相互关系。
物理结构:数据的逻辑结构在计算机中的存储形式。
下面叙述数据结构的逻辑结构和物理结构。 -
数据结构的四大逻辑结构
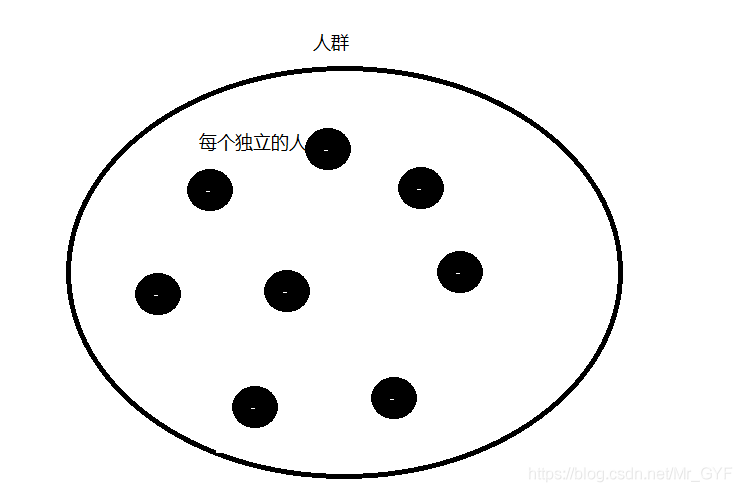
集合结构:结合结构的数据元素除了同属于一个集合外,他们之间没有其他不三不四的关系。如下图,大圈为一个整体属于人类,圈中的每个黑球为世界上每个毫无血缘关系的人。但是他们都属于人类。
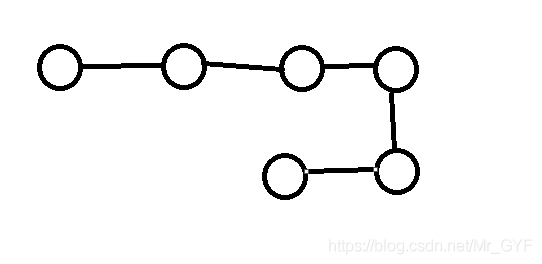
线性结构:元素之间是一种一对一的关系。类似数组。也可看做排队。(球为数据元素)
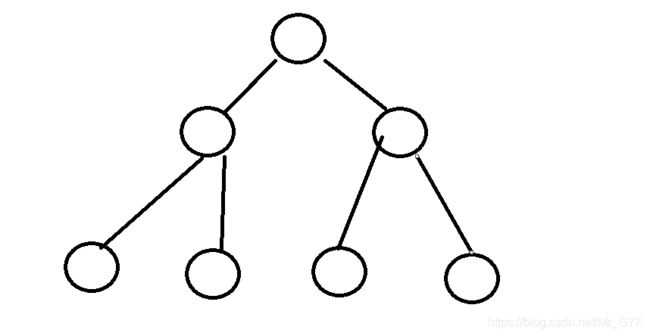
树形结构:树形结构中数据元素之间存在一种一对多层次关系。(球为数据元素)
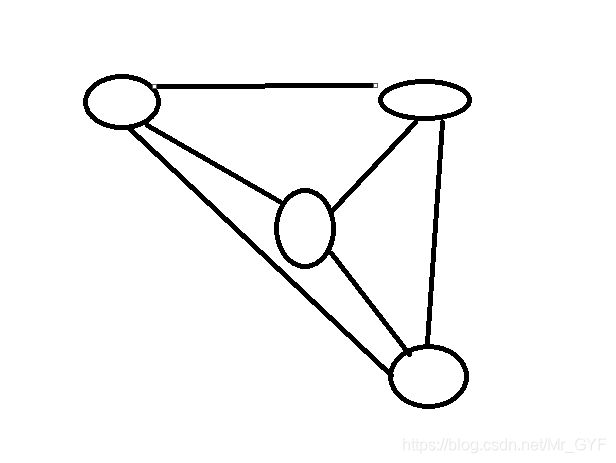
图形结构:数据元素是多对多的关系,(球为数据数据元素)
4. 数据结构的物理结构
主要研究如何把数据关系存储到计算机的存储器(内存)中。上面的球体也就是数据元素。数据元素存储形式有两种:顺序存储和链式存储。
顺序存储结构:把元素存放在地址连续的存储单元里,其数据间的逻辑关系和物理关系是一致的。
例如:数组。
链式存储结构:把数据元素存放在任意的存储单元里,这组存储单元是可以连续的,也可以不连续。链式存储结构的数据元素存储关系并不能反映其逻辑关系,因此需要一个指针存放数据元素的地址,这样通过地址找到相关数据元素的位置。
二、算法
- 算法初体验
使用算法:计算1+2+3+…+99+100
方法一:
int sum =0,n=100;
for(int i = 1;i<=n;i++){
sum = sum+i;
}
printf("%d",sum);
方法二:
int i,sum =0,n=100;
sum=(1+n)*n/2;
printf("%d",sum);
TIPS:方法一运行100次,方法二运行1次。
-
什么是算法?
是解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列。并且每条指令表示一个或多个操作。 -
算法的五个基本特征:
输入,输出,有穷性,确定性和可行性。
输入:算法具有零个或多个输入。(有参函数/无参函数)
输出:至少有一个或多个输出
有穷性:在执行有限的步骤之后,自动结束而不会出现无限循环并且在每一个步骤必须在可接受的时间内完成
确定性:每一个步骤具有确定含义。
可行性:每一步都必须是可行的。 -
算法设计要求
正确性:无语法错误,对合法输入能够产生满足要求的输出
可读性
时间效率高和存储量尽可能低
健壮性
三、算法效率的度量方法
事前分析估算方法:
在计算机运行程序编写前,依据统计方法对算法进行估算。
高级语言编写的程序在计算机上运行时所消耗的时间取决于下列因素:
1.算法采用的策略和方法
2.编译产生的代码质量。(主要是汇编语言)
3.问题的输入规模。(需要输入几个变量或者函数参数传递的多少)
4.机器执行指定的速度
因此,我们抛开硬件和软件的有关因素,一个程序的运行时间依赖于算法的好坏和问题的输入规模。
案例:
算法一:
int sum =0,n=100; //执行一次
for(int i = 1;i<=n;i++){
//执行n+1次
sum = sum+i; //执行n次
}
printf("%d",sum);
tips:注意此处for循环为n+1次的原因:for循环在运行1所以上述算法执行了1+(n+1)+n=2n+2次
案例:算法二:
int i,sum =0,n=100; //执行一次
sum=(1+n)*n/2; //执行一次
printf("%d",sum);
若忽略头尾判断的开销,那么两个算法的差距只有一个n和一个1的差别。
案例:算法三
int i,j,x=0,sum=0,n=100;
for(i = 1;i<=n;i++){
for(j =1 ;j<=n;j++){
x++;
sum=sum+x;
}
}
TIPS:此处循环条件i每从1到100,每次都要让j循环100次,那么一共需要100*100次
因此我们研究算法的复杂度,侧重研究算法随着输入规模扩大增长量的一个抽象。因此不计循环索引的递增和循环终止条件。变量声明,打印结果等,在分析算法运行时间时,重要的是把基本操作的数量和输入模式关联起来。
可以看出:
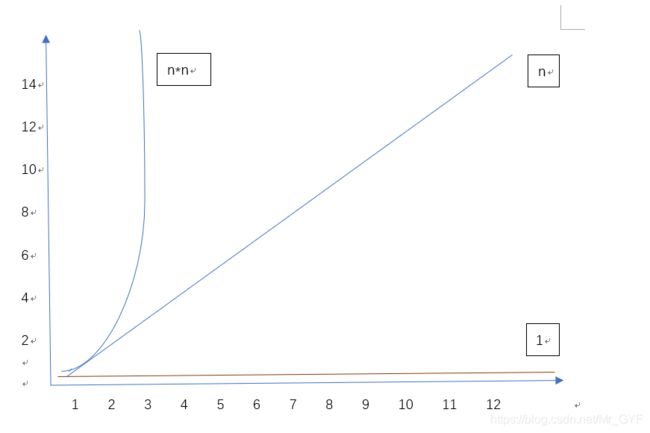
插入一个概念:
函数的渐近增长:给定两个函数f(n)和g(n),如果存在一个整数N,使得对于所有的n>N,f(n)总是比g(n)大,那么我们说f(n)的增长渐近快于g(n)
下面我们做一些测试:
测试一:判断A和B哪个算法更好?
两种算法输入规模都是n,算法A做2n+3次操作。可以理解为先执行n次循环,执行完成后再有一个n次循环,最后有3次运算。算法B做3n+1次操作,先执行n次循环执行结束后,再有两个n次循环,最后执行1次运算。
分析:列出一些普通数据
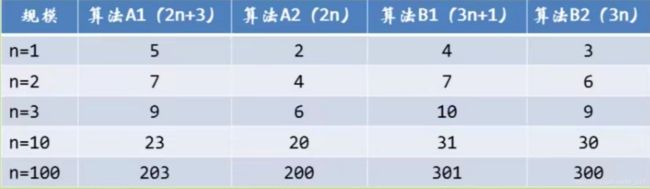
从上述的n增长,我们会发现当n逐渐变大,当达到很大的时候2n+3与2n差别不大,3n+1与3n差别不大
虽然算法A开始不如B运算量小,但是随着n增大,算法A总体运算次数比B小,使用的规模小,算法A总体优于算法B。
测试二:判断算法哪个更好?算法C:4n+8,算法D:2n²+1
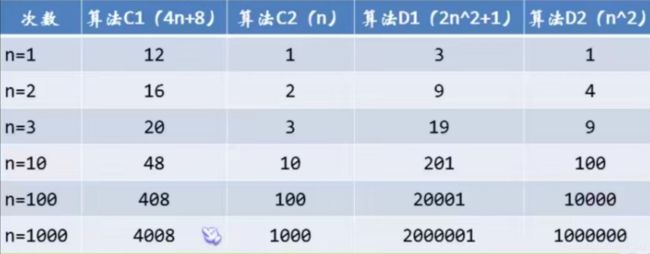
从上述的n增长,我们会发现当n逐渐变大,与最高此项相乘的常数并不重要。即4n+8与4n差别不大。2n²+1与2n²差别不大。如果再随着n的增大会发现n前面的常数也可以进行忽略不记。
算法C使用规模比算法D使用规模要小,算法C优胜。
测试三:判断算法哪个更好?算法E:2n²+3n+1,算法F:2n^3+3n+1?
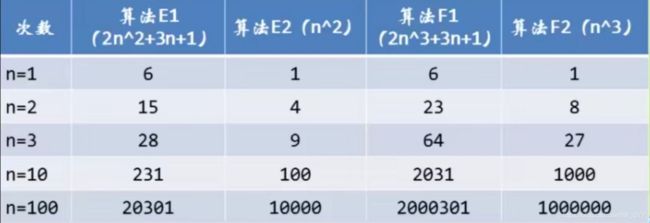
从上述的n增长,我们会发现当n逐渐变大,与最高此项相乘的常数并不重要。即2n²+3n+1与2n²差别不大。2n^3+3n+1与2n^3差别不大。如果再随着n的增大会发现n前面的常数也可以进行忽略不记。最高次项的指数大的,函数随n的增长,结果也会变得增长特别快。
算法E使用规模比算法F使用规模要小,算法E优胜。
测试四:判断算法哪个更好?算法G:2n²,算法H:3n+1,算法I:2n²+3n+1?

从上述的n增长,我们会发现当n逐渐变大,当n的值非常大的时候,3n+1已经无法与2n²的结果进行比较,算法G和算法I基本上已经重合。
四、算法时间复杂度
在进行算法分析时,语句总的执行次数T(n)是关于问题规模n的函数进而分析T(n)随n的变化情况并确定T(n)的数量级。算法时间复杂度,即算法时间度量,记作:T(n)=O(f(n))。表示随着问题规模的增大,算法执行时间的增长度和f(n)的增长率相同,称作算法的渐近时间复杂度。f(n)是问题规模n的某个函数。这里的执行次数 =时间。
一般情况下,随着输入规模n的增大,T(n)增长最慢的算法为最优算法,上面三个求和算法的时间复杂度分别为O(1) , O(n) , O(n²)
如何推导大O阶?
1.用常数1取代运行时间中的所有加法常数
2.在修改后的运行次数函数中,只保留最高阶项
3.如果最高阶项存在且不是1,则去除与这个项相乘的常数
4.得到的最后结果就是O阶。
例如:
常数阶:
int sum =0,n=100;
sum=(1+n)*n/2
该算法的时间复杂度为O(1)
线性阶:
一般含有非嵌套循环设计线性阶,线性阶就是随着问题规模n的扩大,相应的计算机次数呈直线增长。
int i,n=100,sum=0;
for(int i = 0;i<n;i++){
sum=sum+i;
}
该算法的时间复杂度为O(n)
平方阶1:
一般含有嵌套循环,双重for循环等。
int i,j,n=100,sum=0;
for(i =0;i < n;i++){
for(j = 0; j < n;j++){
printf("*****");
}
}
该算法的时间复杂度为O(n²),若有三个for循环嵌套,那么就有O(n的三次方)
平方阶2:
int i,j,n=100,sum=0;
for(i = 0; i < n; i++){
for(j = i;j < n; j++){
printf("*****");
}
}
执行次数:n+(n-1)+(n-2)+…+1=n(n+1)/2;
此时如何算O阶?根据上文的度量方法,我们可以忽略常数项和低阶,只保留高阶。所以该算法的时间复杂度O(n²)
对数阶:
int i,n=100;
while(i<n){
i=i*2;
}
由于每次i*2之后,与n更接近,假设有x个2相乘大于或等于n,则退出循环之后,2的x次方 = n --》x = log2 n
故该算法的时间复杂度为:O(logn)
五、常见的时间复杂度所消耗时间从小到大依次
O(1) < O(logn) < O(n) < O(nlogn) < O(n²) < O(n的三次方) < O(2的n次方) < O(n!) < O(nn)
一般情况下最后三个时间复杂度。过于复杂不进行讨论。其中O(nlogn)的时间复杂度会在后面的算法进行大量讨论
六、算法的空间复杂度
写代码时,完全可以用空间来换取时间。比如我们在计算年份时是否是闰年的时候,我们可以采用两种方法。
方法一:我们需要进行一些计算,用当年年份除以4,看看有没有余数或者别的算法进行计算,判断今年是不是闰年。
方法二:我们在内存中存取2050个元素数组,并且我们把是闰年的年份给标记出来,只要通过索引就能查询到是否是闰年。
方法二就是采用空间也就是内存的大小去解决问题,但是一般的情况下,我们只讨论时间复杂度,很少去讨论空间复杂度。