关于protostuff序列化使用的注意事项
网上看了许多关于protostuff序列化和json序列化性能的对比,普遍表示protostuff序列化后的大小要比json序列化后的大小要小,但是我今天在将一个比较大的数组通过两种不同的方式序列化的时候,发现protostuff的大小比json要大很多。顿时有点怀疑人生,经过反复的测试发现了其中的原因。
问题复现:
假设原始数据是一个类似这样的json字符串(我把里面数组的元素拷贝了520个,这里我就复制了两个元素,下面说的Json数组都有520个元素)
{
"data": [
{
"ds": "2017-12-20",
"os": "all",
"channel": "11",
"version": "1.2.30",
"avg_play_cnt": 1,
"avg_play_percent": 0.18
},
{
"ds": "2017-12-20",
"os": "all",
"channel": "all",
"version": "1.2.30",
"avg_play_cnt": 1,
"avg_play_percent": 0.18
}
]
}
然后我定义了一个类来装载这个json数据:
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* @author : xiaojun
* TODO
* @Date : Created in 15:17 2017/12/27
* @since TODO
*/
public class MapListWrapper {
private List> data = new ArrayList<>();
public int size() {
return data.size();
}
public MapListWrapper() {
}
public MapListWrapper(List> data) {
this.data = data;
}
public List> getData() {
return data;
}
public void setData(List> data) {
this.data = data;
}
} 下面是protostuff序列化反序列化工具类:
import io.protostuff.LinkedBuffer;
import io.protostuff.ProtostuffIOUtil;
import io.protostuff.Schema;
import io.protostuff.runtime.RuntimeSchema;
import org.springframework.objenesis.Objenesis;
import org.springframework.objenesis.ObjenesisStd;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* 序列化工具类(基于 Protostuff 实现)
*/
public class SerializationUtil {
private static Map, Schema> cachedSchema = new ConcurrentHashMap<>();
private static Objenesis objenesis = new ObjenesisStd(true);
private SerializationUtil() {
}
/**
* 序列化(对象 -> 字节数组)
*/
@SuppressWarnings("unchecked")
public static byte[] serialize(T obj) {
Class cls = (Class) obj.getClass();
LinkedBuffer buffer = LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE);
try {
Schema schema = getSchema(cls);
return ProtostuffIOUtil.toByteArray(obj, schema, buffer);
} catch (Exception e) {
throw new IllegalStateException(e.getMessage(), e);
} finally {
buffer.clear();
}
}
/**
* 反序列化(字节数组 -> 对象)
*/
public static T deserialize(byte[] data, Class cls) {
try {
T message = objenesis.newInstance(cls);
Schema schema = getSchema(cls);
ProtostuffIOUtil.mergeFrom(data, message, schema);
return message;
} catch (Exception e) {
throw new IllegalStateException(e.getMessage(), e);
}
}
@SuppressWarnings("unchecked")
private static Schema getSchema(Class cls) {
Schema schema = (Schema) cachedSchema.get(cls);
if (schema == null) {
schema = RuntimeSchema.createFrom(cls);
cachedSchema.put(cls, schema);
}
return schema;
}
} 接下来是测试类:
import com.fasterxml.jackson.databind.ObjectMapper; import com.kingnet.kpg.reporter.api.redis.MapListWrapper; import com.kingnet.kpg.reporter.api.util.SerializationUtil; import java.io.File; /** * @author : xiaojun * TODO * @Date : Created in 17:06 2017/12/27 * @since TODO */ public class TestSerializer { public static void main(String[] args) throws Exception { ObjectMapper objectMapper = new ObjectMapper(); MapListWrapper mapListWrapper = objectMapper.readValue(new File("E:\\test.txt"), MapListWrapper.class);//520个元素的JSON字符串保存在test.txt文件 System.out.println(mapListWrapper.size()); byte[] bytes1 = objectMapper.writeValueAsBytes(mapListWrapper); System.out.println("bytes1:"+ bytes1.length); byte[] bytes2 = SerializationUtil.serialize(mapListWrapper); System.out.println("bytes2:"+ bytes2.length); MapListWrapper mapListWrapper2 = SerializationUtil.deserialize(bytes2,MapListWrapper.class); System.out.println(mapListWrapper2.size()); } }
执行结果如下:
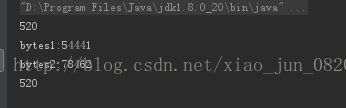
json转成byte数组只有54441个字节,而protostuff却有78462个字节,比json的字节数大很多。。。
然后我单独写一个类来映射数组中每个元素:
/**
* @author : xiaojun
* TODO
* @Date : Created in 17:32 2017/12/27
* @since TODO
*/
public class MyData {
private String ds;
private String os;
private String channel;
private String version;
private Integer avg_play_cnt;
private Double avg_play_percent;
public String getDs() {
return ds;
}
public void setDs(String ds) {
this.ds = ds;
}
public String getOs() {
return os;
}
public void setOs(String os) {
this.os = os;
}
public String getChannel() {
return channel;
}
public void setChannel(String channel) {
this.channel = channel;
}
public String getVersion() {
return version;
}
public void setVersion(String version) {
this.version = version;
}
public Integer getAvg_play_cnt() {
return avg_play_cnt;
}
public void setAvg_play_cnt(Integer avg_play_cnt) {
this.avg_play_cnt = avg_play_cnt;
}
public Double getAvg_play_percent() {
return avg_play_percent;
}
public void setAvg_play_percent(Double avg_play_percent) {
this.avg_play_percent = avg_play_percent;
}
}wrapper也写过一个:
import java.util.ArrayList;
import java.util.List;
/**
* @author : xiaojun
* TODO
* @Date : Created in 15:17 2017/12/27
* @since TODO
*/
public class MyDataListWrapper {
private List data = new ArrayList<>();
public int size() {
return data.size();
}
public MyDataListWrapper() {
}
public MyDataListWrapper(List data) {
this.data = data;
}
public List getData() {
return data;
}
public void setData(List data) {
this.data = data;
}
} import java.io.File;
/**
* @author : xiaojun
* TODO
* @Date : Created in 17:06 2017/12/27
* @since TODO
*/
public class TestSerializer {
public static void main(String[] args) throws Exception {
ObjectMapper objectMapper = new ObjectMapper();
MyDataListWrapper mapListWrapper = objectMapper.readValue(new File("E:\\test.txt"), MyDataListWrapper.class);
System.out.println(mapListWrapper.size());
byte[] bytes1 = objectMapper.writeValueAsBytes(mapListWrapper);
System.out.println("bytes1:"+ bytes1.length);
byte[] bytes2 = SerializationUtil.serialize(mapListWrapper);
System.out.println("bytes2:"+ bytes2.length);
MyDataListWrapper mapListWrapper2 = SerializationUtil.deserialize(bytes2,MyDataListWrapper.class);
System.out.println(mapListWrapper2.size());
}
}这下的执行结果为:
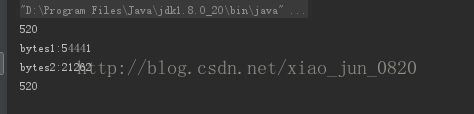
protobuff的序列化比json的序列化要小很多了。
改动的地方仅仅是将Wrapper类中的List
然后我又测试了一下序列化Map对象:
public static void testMapSerialize() throws Exception {
Map data = new HashMap<>();
for (int i = 0; i < 10000000; i++) {
data.put("key" + i, "data" + i);
}
ObjectMapper objectMapper = new ObjectMapper();
byte[] bytes1 = objectMapper.writeValueAsBytes(data);
byte[] bytes2 = SerializationUtil.serialize(new MapWrapper(data));
System.out.println("bytes1 length:"+bytes1.length);
System.out.println("bytes2 length:"+bytes2.length);
} public class MapWrapper {
private Map,String> data;
public MapWrapper(Map, String> data) {
this.data = data;
}
public Map, String> getData() {
return data;
}
public void setData(Map, String> data) {
this.data = data;
}
} 输出结果:
bytes1 length:267777781
bytes2 length:267777782
两者基本上没有什么区别。
然后测试了一下list POJO的序列化:
public static void testListPOJOSerialize() throws Exception {
List data = new ArrayList<>();
for (int i = 0; i < 10000000; i++) {
data.add(new MyVo("key" + i, "data" + i));
}
ObjectMapper objectMapper = new ObjectMapper();
byte[] bytes1 = objectMapper.writeValueAsBytes(data);
byte[] bytes2 = SerializationUtil.serialize(new MyDataListWrapper(data));
System.out.println("bytes1 length:" + bytes1.length);
System.out.println("bytes2 length:" + bytes2.length);
} public class MyDataListWrapper {
private List data = new ArrayList<>();
public int size() {
return data.size();
}
public MyDataListWrapper() {
}
public MyDataListWrapper(List data) {
this.data = data;
}
public List getData() {
return data;
}
public void setData(List data) {
this.data = data;
}
} 结果:
bytes1 length:427777781
bytes2 length:267777780
最后总结一下:
1 protobuff只能序列化pojo类,不能直接序列化List 或者Map,如果要序列化list或者map的话,需要用一个wrapper类包装一下
2 在序列化Map和List