Android常用面向对象设计模式
对于开发人员来说,设计模式有时候就是一道坎,但是设计模式又非常有用,过了这道坎,它可以让你水平提高一个档次。而在android开发中,必要的了解一些设计模式又是必须的,因为设计模式在Android源码中,可以说是无处不在。下面要说的java面向对象的设计模式,对于想深入学习设计模式的同学,这里推荐两本书:《Android源码设计模式解析与实战》、《大话设计模式》。
前言
设计模式(Design pattern)是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。
使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性。毫无疑问,设计模式于己于他人于系统都是多赢的;设计模式使代码编制真正工程化;设计模式是软件工程的基石脉络,如同大厦的结构一样。这是官方的专业解释。大白话意思就是说 设计模式是经验的总结,模板的运用。
因为设计模式是基于对象的特征以及对象之间形成的关系基础上总结的,所以想要了解面向对象的设计模式之前,需要先了解面向对象的两个知识点:面向对象三大基本特性和面向对象类设计中类之间的关系。
面向对象三大基本特性
三大特性是:封装、继承、多态
封装
所谓封装,也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。封装是面向对象的特征之一,是对象和类概念的主要特性。 简单的说,一个类就是一个封装了数据以及操作这些数据的代码的逻辑实体。在一个对象内部,某些代码或某些数据可以是私有的,不能被外界访问。通过这种方式,对象对内部数据提供了不同级别的保护,以防止程序中无关的部分意外的改变或错误的使用了对象的私有部分。
public class Person {
private String name;
private int gender;
private int age;
public String getName() {
return name;
}
public String getGender() {
return gender == 0 ? "man" : "woman";
}
public void work() {
if (18 <= age && age <= 50) {
System.out.println(name + " is working very hard!");
} else {
System.out.println(name + " can't work any more!");
}
}
}
以上 Person 类封装 name、gender、age 等属性,外界只能通过 get() 方法获取一个 Person 对象的 name 属性和 gender 属性,而无法获取 age 属性,但是 age 属性可以供 work() 方法使用。
继承
所谓继承是指可以让某个类型的对象获得另一个类型的对象的属性的方法。它支持按级分类的概念。继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。 通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”。继承的过程,就是从一般到特殊的过程。要实现继承,可以通过“继承”(Inheritance)和“组合”(Composition)来实现。继承概念的实现方式有二类:实现继承与接口继承。实现继承是指直接使用基类的属性和方法而无需额外编码的能力;接口继承是指仅使用属性和方法的名称、但是子类必须提供实现的能力;
继承可以使用 extends 和 implements 这两个关键字来实现继承,而且所有的类都是继承于 java.lang.Object,当一个类没有继承的两个关键字,则默认继承object(这个类在 java.lang 包中,所以不需要 import)祖先类。extends是单继承,而implements可以多继承。
- extends单继承
public class A {
public int a;
private int b;
public void methodA();
}
public class B extends A{
//拥有A非private属性a和方法methodA()
}
- implements多继承
public interface A {
public void methodA();
}
public interface B {
public void methodB();
}
public class C implements A,B {
//拥有并需要实现A、B的methodA和methodB
}
多态
多态是指子类对象可以直接赋给父类变量(父类引用指向子类对象),但运行时依然表现出子类的行为特征,也就是说,同一类型的对象在执行同一个方法时,可能表现出多种行为特征。多态存在的三个必要条件:
- 继承
- 重写
- 父类引用指向子类对象
public class Test {
public static void main(String[] args) {
People p1 = new Man();
People p2 = new Woman();
//调用人的吃饭方法,实际最终调用的是男人大口吃饭的方法
p1.eat();
//调用人的吃饭方法,实际最终调用的是女人小口吃饭的方法
p2.eat();
}
}
//父类:人类
public class People{
public void eat(){
System.out.println("吃");
}
}
//子类:男人
public class Man extends People{
public void eat(){
System.out.println("大口吃");
}
}
//子类:女人
public class Woman extends People{
public void eat(){
System.out.println("小口吃");
}
}
当使用多态方式调用方法时,首先检查父类中是否有该方法,如果没有,则编译错误;如果有,再去调用子类的同名方法。
多态的好处:可以使程序有良好的扩展,并可以对所有类的对象进行通用处理。
面向对象类设计中类之间的关系
所谓的设计正是采用恰当的方式组织类关。因此谈设计我认为首先要从类之间的关系开始说起.在java开发中,有很多时候我们是在不断的处理类与类之间关系,其中这六种关系是:依赖、关联、聚合、组合、继承、实现,他们的耦合度依次增强。
依赖(Dependence)
依赖关系讲求的临时性和偶然性。
比如在实际生活中我们做一件事情都需要临时借助其他物体的帮助,但是并不是永久的。比如:人要开车,人临时要借辆车还有临时车牌即可上路了。一般而言,依赖关系。在Java语言中体现为局域变量、方法的形参,或者对静态方法的调用。
public class Person{
//Car作为形参,被Person临时依赖,用完就归还
public void drive(Car car){
//局部变量TemporaryDrivingLicense表示临时车牌,用完可以丢掉
TemporaryDrivingLicense license;
//静态方法的调用也是依赖关系
}
}
关联(Association)
如果说依赖关系讲求的临时性,偶然性的话,那么关联关系则是一种持久性的关系。与依赖关系不同,关联对象的双方地位同级,存在长期,固定的对应关系,即关联是一种强依赖。
关联关系共分为两种:单向关联和双向关联。所谓单向关联通俗点讲就是“你中有我,但我中未必有你”,比如小明拥有一辆车(注意和小明开车进行区分),但车这个对象可不拥有你。和单向关联相对应的是双向关联,也即是“你中有我,我中有你”,比如夫妻就是一种双向关联。在Java语言中体现为对象作为另一个类的成员变量。
public class Person{
private Car car;
public void setCar(Car car){
this.car=car;
}
}
- 双向关联
public class Husband{
private Wife wife=new Wife();
public void say(){
System.out.println("my wife name:"+wife.getName());
}
}
public class Wife{
private Husband husband=new Husband();
public void say(){
System.out.println("my husband name:"+husband.getName());
}
}
聚合(Aggregation)
聚合关系是一种强关联关系,和关联之间最主要的区别是在语意上:聚合之间的关系更像是”整体-部分”,同时,部分脱离整体还是可以存活的。
有点组装的含义,而关联关系的对象间是相互独立的,不存在组装关系。比如:在现实世界中,分子是由原子组成的,汽车是由各种零部件组成的等,这都是聚合关系的最好说明。这里要注意,组成A类型分子的原子也可以组成B类型的分子,这说明什么呢?也就是部分可以单独存在。换句话说就是整体和部分两者的生命周期不是同步的。比如:水分子是由氧原子和氢原子组成的,你不能说没有水分子就没有氧原子和氢原子吧。在Java语言中聚合和关联两者的形式一致,都体现为对象作为另一个类的成员变量。
//车是轮胎和引擎的聚合,但是轮胎脱离车还是可以存活的
public class Car{
private Tyre tyre;//轮胎
private Engine engine;//引擎
public void setTyre(Tyre tyre){
this.tyre=tyre;
}
public void setEngine(Engine engine){
this.engine=engine;
}
}
组合(Composition)
组合和聚合非常类似,也是一种强关联关系,都表示的”整体-部分”,但不同的是“整体”负责“部分”的生命周期,他们之间是共生共死的,并且“部分”单独存在时没有任何意义。
不难发现,组合是一种强聚合关系.比如,人这个生命体由不同器官构成,其中我们拿心脏来说一下,人要活着必须依靠心脏,心脏不能脱离人这个生命体,两者一旦分开,都会死亡。在Java语言中体现为对象作为另一个类的成员变量。
public class People{
private Heart heart;
public People(){
heart=new Heart();
}
}
继承(Generalization)
继承表示类与类(或者接口与接口)之间的父子关系。
在java中,用关键字extends表示继承关系。
public class A {
}
public class B extends A{
}
实现(Implementation)
表示一个类实现一个或多个接口的方法。接口定义好操作的集合,由实现类去完成接口的具体操作。
在java中使用implements表示。
public interface A {
public void methodA();
}
public class B implements A{
@Override
public void methodA(){
}
}
关联、聚合、组合只能配合语义,结合上下文才能够判断出来,而只给出一段代码让我们判断是关联,聚合,还是组合关系,则是无法判断的。以上就是面向对象的基本特征及对象之间的关系,也可以说是对象的思想。在运用面向对象的思想进行软件设计时,前人又总结了六大原则,所有的设计模式都是在这六条原则基础上总结的。
设计模式六大原则
在软件设计的过程中,只要我们尽量遵循以下六条设计原则,设计出来的软件一定会是一个优秀的软件,它必定足够健壮、足够稳定,并以极大的灵活性来迎接随时而来的需求变更等因素。
- 单一职责原则(Single Responsibility Principle)
- 里氏替换原则(Liskov Substitution Principle)
- 依赖倒置原则(Dependence Inversion Principle)
- 接口隔离原则(Interface Segregation Principle)
- 迪米特法则(Law Of Demeter)
- 开闭原则(Open Close Principle)
单一职责原则
定义:不要存在多于一个导致类变更的原因。通俗的说,即一个类只负责一项职责。
问题由来:类C存在两个职责D1和D2。当由于职责D1需求发生改变而需要修改类C时,有可能会导致原本运行正常的职责D2功能发生故障。
解决方案:遵循单一职责原则。分别建立两个类DClass1、DClass2,使DClassA完成职责D1功能,DClass1完成职责D2功能。这样,当修改类DClass1时,不会使职责D2发生故障风险;同理,当修改DClass1时,也不会使职责D2发生故障风险。
public class ImageLoader {
//图片内存缓存
private LruCache<String,Bitmap> mImageCache;
public void displayImage(final String url, final ImageView imageView){
Bitmap bitmap = mImageCache.get(url);
if(bitmap != null){
imageView.setImageBitmap(bitmap);
return;
}
imageView.setTag(url);
Bitmap bitmap = downloadImage(url);
if(bitmap == null){
return;
}
if (imageView.getTag().equals(url)) {
imageView.setImageBitmap(bitmap);
}
mImageCache.put(url,bitmap);
}
}
我们一般都会这样这样简单的实现一个图片加载工具类,这样写功能虽然实现了,但是代码是有问题的,代码耦合严重,随着ImageLoader功能越来越多,这个类会越来越大,代码越来越复杂。按照单一职责原则,我们应该把ImageLoader拆分一下,把各个功能独立出来。下面代码将ImageLoader一分为二,ImageLoader只负责图片加载的逻辑,ImageCache负责缓存策略,这样,ImageLoader的代码变少了,职责也清晰了,并且如果缓存策略改变了的话,只需要修改ImageCache而不需要在修改ImageLoader了。
public class ImageLoader {
//图片缓存
ImageCache mImageCache = new ImageCache();
public void displayImage(final String url, final ImageView imageView){
...
}
}
public class ImageCache {
//图片内存缓存
private LruCache<String,Bitmap> mImageCache;
public Bitmap get(String url){
return mImageCache.get(url);
}
public void put(String url,Bitmap bitmap){
mImageCache.put(url,bitmap);
}
}
说到单一职责原则,很多人都会不屑一顾。因为它太简单了。稍有经验的程序员即使从来没有读过设计模式、从来没有听说过单一职责原则,在设计软件时也会自觉的遵守这一重要原则,因为这是常识。在软件编程中,谁也不希望因为修改了一个功能导致其他的功能发生故障。而避免出现这一问题的方法便是遵循单一职责原则。虽然单一职责原则如此简单,并且被认为是常识,但是即便是经验丰富的程序员写出的程序,也会有违背这一原则的代码存在。为什么会出现这种现象呢?因为有职责扩散。所谓职责扩散,就是因为某种原因,职责P被分化为粒度更细的职责P1和P2。
比如:类T只负责一个职责P,这样设计是符合单一职责原则的。后来由于某种原因,也许是需求变更了,也许是程序的设计者境界提高了,需要将职责P细分为粒度更细的职责P1,P2,这时如果要使程序遵循单一职责原则,需要将类T也分解为两个类T1和T2,分别负责P1、P2两个职责。但是在程序已经写好的情况下,这样做简直太费时间了。所以,简单的修改类T,用它来负责两个职责是一个比较不错的选择,虽然这样做有悖于单一职责原则。(这样做的风险在于职责扩散的不确定性,因为我们不会想到这个职责P,在未来可能会扩散为P1,P2,P3,P4……Pn。所以记住,在职责扩散到我们无法控制的程度之前,立刻对代码进行重构。)
遵循单一职责原的优点有:
- 可以降低类的复杂度,一个类只负责一项职责,其逻辑肯定要比负责多项职责简单的多。
- 提高类的可读性,提高系统的可维护性。
- 变更引起的风险降低,变更是必然的,如果单一职责原则遵守的好,当修改一个功能时,可以显著降低对其他功能的影响。
里氏替换原则
定义1:如果对每一个类型为 T1的对象 t1,都有类型为 T2 的对象t2,使得以 T1定义的所有程序 P 在所有的对象 t1 都代换成 t2 时,程序 P 的行为没有发生变化,那么类型 T2 是类型 T1 的子类型。
定义2:所有引用基类(父类)的地方必须能透明地使用其子类的对象。简单地说就是父类能出现的地方,子类就能出现,并且替换为子类也不会产生任何异常。
肯定有不少人跟我刚看到这项原则的时候一样,对这个原则的名字充满疑惑。其实原因就是这项原则最早是在1988年,由麻省理工学院的一位姓里的女士(Barbara Liskov)提出来的。
问题由来:有一功能P1,由类A完成。现需要将功能P1进行扩展,扩展后的功能为P,其中P由原有功能P1与新功能P2组成。新功能P由类A的子类B来完成,则子类B在完成新功能P2的同时,有可能会导致原有功能P1发生故障。
解决方案:当使用继承时,遵循里氏替换原则。类B继承类A时,除添加新的方法完成新增功能P2外,尽量不要重写父类A的方法,也尽量不要重载父类A的方法。
继承包含这样一层含义:父类中凡是已经实现好的方法(相对于抽象方法而言),实际上是在设定一系列的规范和契约,虽然它不强制要求所有的子类必须遵从这些契约,但是如果子类对这些非抽象方法任意修改,就会对整个继承体系造成破坏。而里氏替换原则就是表达了这一层含义。
继承作为面向对象三大特性之一,在给程序设计带来巨大便利的同时,也带来了弊端。比如使用继承会给程序带来侵入性,程序的可移植性降低,增加了对象间的耦合性,如果一个类被其他的类所继承,则当这个类需要修改时,必须考虑到所有的子类,并且父类修改后,所有涉及到子类的功能都有可能会产生故障。
举例说明继承的风险,我们需要完成一个两数相减的功能,由类A来负责。
public class A {
public int func1(int a, int b){
return a - b;
}
}
...
A a = new A();
System.out.println("100 - 50 = " + a .func1(100,50));//100 - 50 = 50
System.out.println("100 - 80 = " + a .func1(100,80));//100 - 80 = 20
后来,我们需要增加一个新的功能:完成两数相加,然后再与100求和,由类B来负责。即类B需要完成两个功能:
public class B extends A {
public int func1(int a, int b){
return a - b;
}
public int func2(int a, int b){
return func1(a, b) + 100;
}
}
...
B b = new B();
//可以写为:A a = new B(); 输出结果:a .func1(100,50)) ==> 100 - 50 = 150
System.out.println("100 - 50 = " + b .func1(100,50));//100 - 50 = 150
System.out.println("100 - 80 = " + b .func1(100,80));//100 - 80 = 180
System.out.println("100 + 20 + 100 = " + b .func2(100,80));//100 + 20 + 100 = 220
们发现原本运行正常的相减功能发生了错误。原因就是类B在给方法起名时无意中重写了父类的方法,造成所有运行相减功能的代码全部调用了类B重写后的方法,造成原本运行正常的功能出现了错误。在本例中,引用基类A完成的功能,换成子类B之后,发生了异常。在实际编程中,我们常常会通过重写父类的方法来完成新的功能,这样写起来虽然简单,但是整个继承体系的可复用性会比较差,特别是运用多态比较频繁时,程序运行出错的几率非常大。如果非要重写父类的方法,比较通用的做法是:原来的父类和子类都继承一个更通俗的基类,原有的继承关系去掉,采用依赖、聚合,组合等关系代替。
里氏替换原则通俗的来讲就是:子类可以扩展父类的功能,但不能改变父类原有的功能。它包含以下4层含义:
- 子类可以实现父类的抽象方法,但不能覆盖父类的非抽象方法。
- 子类中可以增加自己特有的方法。
- 当子类的方法重载父类的方法时,方法的前置条件(即方法的形参)要比父类方法的输入参数更宽松。
- 当子类的方法实现父类的抽象方法时,方法的后置条件(即方法的返回值)要比父类更严格。
依赖倒置原则
定义:高层模块不应该依赖低层模块,二者都应该依赖其抽象;抽象不应该依赖细节;细节应该依赖抽象。
问题由来:类A直接依赖类B,假如要将类A改为依赖类C,则必须通过修改类A的代码来达成。这种场景下,类A一般是高层模块,负责复杂的业务逻辑;类B和类C是低层模块,负责基本的原子操作;假如修改类A,会给程序带来不必要的风险。
解决方案:将类A修改为依赖接口I,类B和类C各自实现接口I,类A通过接口I间接与类B或者类C发生联系,则会大大降低修改类A的几率。
依赖倒置原则基于这样一个事实:相对于细节的多变性,抽象的东西要稳定的多。以抽象为基础搭建起来的架构比以细节为基础搭建起来的架构要稳定的多。在java中,抽象指的是接口或者抽象类,细节就是具体的实现类,使用接口或者抽象类的目的是制定好规范和契约,而不去涉及任何具体的操作,把展现细节的任务交给他们的实现类去完成。
依赖倒置原则的核心思想是面向接口编程,我们依旧用一个例子来说明面向接口编程比相对于面向实现编程好在什么地方。场景是这样的,母亲给孩子讲故事,只要给她一本书,她就可以照着书给孩子讲故事了。代码如下:
public class Book {
public String getContent(){
return "这是阿拉伯的故事";
}
}
public class Mother{
public say(Book book){
return System.out.println("妈妈开始讲故事:" + book.getContent());
}
}
...
Mother motner = new Mother();
motner.say(new Book());//妈妈开始讲故事: 这是阿拉伯的故事
运行良好,假如有一天,需求变成这样:不是给书而是给一份报纸,让这位母亲讲一下报纸上的故事,报纸的代码如下:
public class Newspaper{
public String getContent(){
return "这是报纸新闻";
}
}
这时候你会发,这位母亲她居然不会读报纸上的故事,这太荒唐了,只是将书换成报纸,居然必须要修改Mother才能读。假如以后需求换成杂志呢?换成网页呢?还要不断地修改Mother,这显然不是好的设计。原因就是Mother与Book之间的耦合性太高了,必须降低他们之间的耦合度才行。
我们引入一个抽象的接口IReader。读物,只要是带字的都属于读物:
public interface IReader{
public String getContent();
}
Mother类与接口IReader发生依赖关系,而Book和Newspaper都属于读物的范畴,他们各自都去实现IReader接口,这样就符合依赖倒置原则了,代码修改为:
public class Book implements IReader{
public String getContent(){
return "这是阿拉伯的故事";
}
}
public class Newspaper implements IReade{
public String getContent(){
return "这是报纸新闻";
}
}
public class Mother{
public say(IReade reader){
return System.out.println("妈妈开始讲故事:" + book.getContent());
}
}
...
Mother motner = new Mother();
motner.say(new Book());//妈妈开始讲故事: 这是阿拉伯的故事
motner.say(new Newspaper ());//妈妈开始讲故事: 这是报纸新闻
这样修改后,无论以后怎样扩展Client类,都不需要再修改Mother类了。这只是一个简单的例子,实际情况中,代表高层模块的Mother类将负责完成主要的业务逻辑,一旦需要对它进行修改,引入错误的风险极大。所以遵循依赖倒置原则可以降低类之间的耦合性,提高系统的稳定性,降低修改程序造成的风险。
采用依赖倒置原则给多人并行开发带来了极大的便利,比如上例中,原本Mother类与Book类直接耦合时,Mother类必须等Book类编码完成后才可以进行编码,因为Mother类依赖于Book类。修改后的程序则可以同时开工,互不影响,因为Mother与Book类一点关系也没有。参与协作开发的人越多、项目越庞大,采用依赖导致原则的意义就越重大。现在很流行的TDD开发模式就是依赖倒置原则最成功的应用。
传递依赖关系有三种方式,以上的例子中使用的方法是接口传递,另外还有两种传递方式:构造方法传递和setter方法传递,相信用过Spring框架的,对依赖的传递方式一定不会陌生。
在实际编程中,我们一般需要做到如下3点:
- 低层模块尽量都要有抽象类或接口,或者两者都有。
- 变量的声明类型尽量是抽象类或接口。
- 使用继承时遵循里氏替换原则。
接口隔离原则
定义:客户端不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上。
问题由来:类A通过接口I依赖类B,类C通过接口I依赖类D,如果接口I对于类A和类B来说不是最小接口,则类B和类D必须去实现他们不需要的方法。
解决方案:将臃肿的接口I拆分为独立的几个接口,类A和类C分别与他们需要的接口建立依赖关系。也就是采用接口隔离原则。
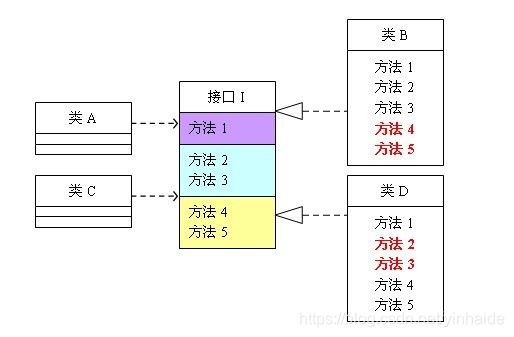
public interface I {
public void method1();
public void method2();
public void method3();
public void method4();
public void method5();
}
public classd B implements I {
public void method1(){
}
public void method2(){
}
public void method3(){
}
//对于B来说,接口I的method4和method5不是必须的,
//但是因为I中有这两个方法,B必须要实现,违反了接口隔离原则
public void method4(){
}
public void method5(){
}
}
可以看到,如果接口过于臃肿,只要接口中出现的方法,不管对依赖于它的类有没有用处,实现类中都必须去实现这些方法,这显然不是好的设计。如果将这个设计修改为符合接口隔离原则,就必须对接口I进行拆分。在这里我们将原有的接口I拆分为三个接口,拆分后的设计如图2所示:
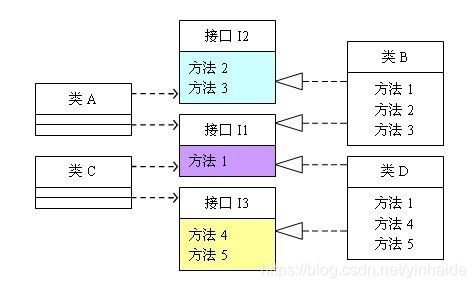
public interface I1 {
public void method1();
}
public interface I2 {
public void method2();
public void method3();
}
public interface I3 {
public void method4();
public void method5();
}
public classd B implements I1, I2 {
public void method1(){
}
public void method2(){
}
public void method3(){
}
}
public classd D implements I1, I3 {
public void method1(){
}
public void method4(){
}
public void method5(){
}
}
接口隔离原则的含义是:建立单一接口,不要建立庞大臃肿的接口,尽量细化接口,接口中的方法尽量少。也就是说,我们要为各个类建立专用的接口,而不要试图去建立一个很庞大的接口供所有依赖它的类去调用。本文例子中,将一个庞大的接口变更为3个专用的接口所采用的就是接口隔离原则。在程序设计中,依赖几个专用的接口要比依赖一个综合的接口更灵活。接口是设计时对外部设定的“契约”,通过分散定义多个接口,可以预防外来变更的扩散,提高系统的灵活性和可维护性。
说到这里,很多人会觉的接口隔离原则跟之前的单一职责原则很相似,其实不然。其一,单一职责原则原注重的是职责;而接口隔离原则注重对接口依赖的隔离。其二,单一职责原则主要是约束类,其次才是接口和方法,它针对的是程序中的实现和细节;而接口隔离原则主要约束接口接口,主要针对抽象,针对程序整体框架的构建。
采用接口隔离原则对接口进行约束时,要注意以下几点:
- 接口尽量小,但是要有限度。对接口进行细化可以提高程序设计灵活性是不挣的事实,但是如果过小,则会造成接口数量过多,使设计复杂化。所以一定要适度。
- 为依赖接口的类定制服务,只暴露给调用的类它需要的方法,它不需要的方法则隐藏起来。只有专注地为一个模块提供定制服务,才能建立最小的依赖关系。
- 提高内聚,减少对外交互。使接口用最少的方法去完成最多的事情。
迪米特法则
定义:一个对象应该对其他对象保持最少的了解。
问题由来:类与类之间的关系越密切,耦合度越大,当一个类发生改变时,对另一个类的影响也越大。
解决方案:尽量降低类与类之间的耦合。
自从我们接触编程开始,就知道了软件编程的总的原则:低耦合,高内聚。无论是面向过程编程还是面向对象编程,只有使各个模块之间的耦合尽量的低,才能提高代码的复用率。低耦合的优点不言而喻,但是怎么样编程才能做到低耦合呢?那正是迪米特法则要去完成的。
迪米特法则又叫最少知道原则,最早是在1987年由美国Northeastern University的Ian Holland提出。通俗的来讲,就是一个类对自己依赖的类知道的越少越好。也就是说,对于被依赖的类来说,无论逻辑多么复杂,都尽量地的将逻辑封装在类的内部,对外除了提供的public方法,不对外泄漏任何信息。迪米特法则还有一个更简单的定义:只与直接的朋友通信。首先来解释一下什么是直接的朋友:每个对象都会与其他对象有耦合关系,只要两个对象之间有耦合关系,我们就说这两个对象之间是朋友关系。耦合的方式很多,依赖、关联、组合、聚合等。其中,我们称出现成员变量、方法参数、方法返回值中的类为直接的朋友,而出现在局部变量中的类则不是直接的朋友。也就是说,陌生的类最好不要作为局部变量的形式出现在类的内部。
下面以租房的例子来理解说明这个原则。租房大多数通过中介来租,我们假设设定的情景为:我们只要求房子的面积和租金,其他的一概不管,中介提供给我们符合要求的房子。
public class Room {
//房子
public float area;//面积
public float price;//加个
...
}
public class Mediator {
//中介
private List<Room> mRooms = new ArrayList<>();//中介有若干个房子
...
public List<Room> getRooms(){
return mRooms;
}
}
public class Tenant {
//租户
private static final float roomArea = 100;//租户要求的面积
private static final float roomPrice = 1000;//租户要求的价格
private static final float diffArea = 20f;//面积接收差
private static final float diffPrice = 100f;//价格接收差
public void rentRoom(Mediator mediator){
//开始向租房子
List<Room> rooms = mediator.getRooms();//中介提供的所有的房子
for (Room room : rooms) {
//租户自己在所有房子里面找合适的
boolean isSuitable = Math.abs(room.price - roomPrice) < diffPrice && Math.abs(room.area - roomArea) < diffArea;
if(isSuitable){
System.out.print("租到房子了" + room.toString());
break;
}
}
}
}
从上面的代码看出,Tenant不仅依赖Mediator,还需要频繁的与Room打交道,租户类只需要通过中介找到一间符合要求的房子即可。如果把这些检索都放在Tenant中,就弱化了中介的作用,而且导致Tenant和Room耦合度较高。当Room变化的时候,Tenant也必须跟着变化,而且Tenant还和Mediator耦合,这样关系就显得有些混乱了。我们需要根据迪米特原则进行解耦:
public class Mediator {
//中介
private List<Room> mRooms = new ArrayList<>();//中介的房子
...
public Room rentOut(float price,float difPrice,float area,float difArea){
//中介按要求找符合的房子
for (Room room : mRooms) {
boolean isSuitable = Math.abs(room.price - price) < difPrice && Math.abs(room.area - area) < difArea;
if (isSuitable) {
return room;
}
}
return null;
}
}
public class Tenant {
//租户
private static final float roomArea = 100;//租户要求的面积
private static final float roomPrice = 1000;//租户要求的价格
private static final float diffArea = 20f;//面积接收差
private static final float diffPrice = 100f;//价格接收差
public void rentRoom(Mediator mediator) {
//租户像中介要房子
Room room = mediator.rentOut(roomPrice, diffPrice , roomArea, diffArea );
if(null != room){
System.out.print("租到房子了" + room.toString());
}
}
}
我们将对Room的操作移到了Mediator中,这本来就是Mediator的职责,根据租户的条件检索符合的房子,并且将房子返回给用户即可。这样租户就不需要知道有关Room的细节,比如和房东签合同,房产证的真伪等。只需要关注和我们相关的即可。
迪米特法则的初衷是降低类之间的耦合,由于每个类都减少了不必要的依赖,因此的确可以降低耦合关系。但是凡事都有度,虽然可以避免与非直接的类通信,但是要通信,必然会通过一个“中介”来发生联系,例如本例中,总公司就是通过分公司这个“中介”来与分公司的员工发生联系的。过分的使用迪米特原则,会产生大量这样的中介和传递类,导致系统复杂度变大。所以在采用迪米特法则时要反复权衡,既做到结构清晰,又要高内聚低耦合。
开闭原则
定义:一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。简单说就是,你现在写的代码在面对需求变更时能够这样轻松应对:通过继承来实现新需求,不修改内部代码。
问题由来:在软件的生命周期内,因为变化、升级和维护等原因需要对软件原有代码进行修改时,可能会给旧代码中引入错误,也可能会使我们不得不对整个功能进行重构,并且需要原有代码经过重新测试。
解决方案:当软件需要变化时,尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有的代码来实现变化。软件内部代码只因错误修改,而不能是因为新增的需求
例如我们自己实现ImageLoader,其中肯定包括缓存的实现,根据上一节的单一职责原则,我肯定知道将缓存提出来为ImageCache类,然后在ImageLoder中。下个星期产品说每次app重新打开都需要重新下载图片,这样太费流量了,于是我到ImageCache类中将内存缓存改为DiskCache磁盘缓存。这时候你只能去改ImageLoader的源代码,将ImageCache替换为DiskCache,这明显违反开闭原则原则。正确的做法是抽象出缓存的通用接口:
public interface ImageCache {
//抽象接口
public Bitmap get(String url);
public void put(String url, Bitmap bitmap);
}
public class DiskCache implements ImageCache {
//磁盘缓存
@Override
public Bitmap get(String url) {
}//实现磁盘缓存相关逻辑
@Override
public void put(String url, Bitmap bitmap) {
}//实现磁盘缓存相关逻辑
}
public class MemoryCache implements ImageCache {
内存缓存
@Override
public Bitmap get(String url) {
}//实现内存缓存相关逻辑
@Override
public void put(String url, Bitmap bitmap) {
}//实现内存缓存相关逻辑
}
public class ImageLoader {
//默认缓存方式为内存缓存
ImageCache mImageCache = new MemoryCache();
//设置缓存方式
public void setImageCache(ImageCache cache){
mImageCache = cache;
}
public void displayImage(final String url, final ImageView imageView){
Bitmap bitmap = mImageCache.get(url);
...
mImageCache.put(url,bitmap);
}
}
产品说要磁盘缓存:
setImageCache(new DiskCaChe)
产品说要内存缓存:
setImageCache(new MemoryCaChe)
其实笔者认为,开闭原则无非就是想表达这样一层意思:用抽象构建框架,用实现扩展细节。因为抽象灵活性好,适应性广,只要抽象的合理,可以基本保持软件架构的稳定。而软件中易变的细节,我们用从抽象派生的实现类来进行扩展,当软件需要发生变化时,我们只需要根据需求重新派生一个实现类来扩展就可以了。当然前提是我们的抽象要合理,要对需求的变更有前瞻性和预见性才行。
说到这里,再回想一下前面说的5项原则,恰恰是告诉我们用抽象构建框架,用实现扩展细节的注意事项而已:单一职责原则告诉我们实现类要职责单一;里氏替换原则告诉我们不要破坏继承体系;依赖倒置原则告诉我们要面向接口编程;接口隔离原则告诉我们在设计接口的时候要精简单一;迪米特法则告诉我们要降低耦合。而开闭原则是总纲,他告诉我们要对扩展开放,对修改关闭。
Android常用设计模式
1、单例模式
定义:确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例。
单例模式的首要条件就是构造方法私有化、没有接口,不能扩展,不能继承。它违反了职责单一原则,因为他把所有的职责囊括在一个实例中。但是在一些使用场景,还是考虑单例的便利性。单例主要有两种种实现方式,懒汉模式和饿汉模式。
- 饿汉模式
在类加载时就完成了初始化,是线程安全的,但是加载比较慢,获取对象比较快。如果这个实例不被使用,造成内存浪费。 - 懒汉模式
在类加载的时候不被初始化,在调用的时候才会创建对象实例。如果不做线程同步保护,在多线程情况下可能会被创建多个实例。
设计单例的时候一定要考虑内存浪费、线程安全、被克隆(实现Cloneable接口)、被序列化(实现Serializable接口)以及被反射问题,防止单例被破坏,产生不止一个实例对象。
饿汉模式
- 静态常量
public class Singleton {
//在类初始化时,已经自行实例化,所以是线程安全的。
private static final Singleton singleton = new Singleton();
public static Singleton getInstance() {
return singleton;
}
}
优点:
1、写法简单,线程安全。
缺点:
1、过早的创建对象,并且不能在初始化时传参。
2、没有懒加载的效果,如果没有使用的话会造成内存浪费。
3、无法抵御反射对单例的破坏问题(通过反射创建新的单例)。
//验证反射破坏单例唯一性
private static void checkInvokeDestroy(Singleton singleton) throws IllegalAccessException , InstantiationException, InvocationTargetException {
Class clazz = singleton.getClass();
Constructor<Singleton> constructor = clazz.getDeclaredConstructors()[0];
constructor.setAccessible(true);//设置允许访问私有的构造器
Singleton singleton1 = constructor.newInstance();
if (singleton1 != null && singleton1.getClass().equals(singleton.getClass())) {
System.out.println("是同一个对象:"+singleton == singleton1);//打印为不同的对象
}
}
如何解决反射对单例的破坏问题:只要在构造函数中加单例非空判断即可。
public class Singleton {
//在类初始化时,已经自行实例化,所以是线程安全的。
private static final Singleton singleton = new Singleton();
private Singleton() {
//如果已存在,直接抛出异常,保证只会被new 一次
if (singleton != null) {
throw new RuntimeException("对象已存在不可重复创建");
}
}
public static Singleton getInstance() {
return singleton;
}
}
假如你这个单例有被序列化的需求(如在bundle中传递数据),需要实现Serializable接口:
public class Singleton implements Serializable{
}
那么这个单例将面临被序列化创建新的实例对象的问题。
private static void checkSerializeDestroy(Singleton hungrySingleton) throws IOException, ClassNotFoundException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(hungrySingleton);//原对象的序列化
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
Singleton hungrySingleton_new= (Singleton) ois.readObject();//新的序列化产生的对象
System.out.println(hungrySingleton == hungrySingleton_new);//打印为false,即存在两个序列化对象
}
如何解决序列化对单例的破坏问题?我们注意到上面序列化最终会调用readObject()方法返回一个实例对象,假如这个实例对象最终返回的是原来的对象而非新的对象不就解决了?具体的过程我们就不分析,跟进readObject()内部我们会发现一个最终的调用方法:readResolve()。如果存在该方法,就返回一个对象,如果不存在就创建新对象。那么简单了,我们直接在readResolve方法中返回我们原来的实例对象即可。
public class Singleton implements Serializable{
private Object readResolve(){
return singleton;
}
}
最终抵御反射和序列化对单例的破坏问题的饿汉式单例模式:
public class Singleton implements Serializable{
//在类初始化时,已经自行实例化,所以是线程安全的。
private static final Singleton singleton = new Singleton();
private Singleton() {
//如果已存在,直接抛出异常,保证只会被new 一次,解决反射破坏单例的方案
if (singleton != null) {
throw new RuntimeException("对象已存在不可重复创建");
}
}
public static Singleton getInstance() {
return singleton;
}
//解决被序列化破坏单例的问题
private Object readResolve(){
return singleton;
}
}
- 枚举单例
枚举类单例有非常多的优点,如果不考虑饿汉式可能的内存浪费问题,可誉为最优的单例方案:
- 线程安全
在类加载的时候已经创建好对象实例,是线程安全的。 - 克隆安全
Enum类已经将clone()方法定义为final了,所以枚举不能被克隆的,所以枚举对于克隆是安全的。 - 序列化是安全
我们在上面你分析的序列化readObject()方法,针对枚举对象的时候,优先判断,返回的是底层默认缓存的是唯一对象,所以枚举对序列化是安全的。 - 反射安全
对于枚举被反射的问题,上面提到的反射代码constructor.newInstance()底层有一段代码,if ((clazz.getModifiers() & Modifier.ENUM) != 0) throw new IllegalArgumentException(“Cannot reflectively create enum objects”);当判断是枚举类的时候,就直接抛出异常了。所以,枚举对于反射是安全的。
public class User {
//私有化构造函数
private User(){
}
//定义一个静态枚举类
static enum SingletonEnum implements Serializable{
//创建一个枚举对象,该对象天生为单例
INSTANCE;
private User user;
//私有化枚举的构造函数
private SingletonEnum(){
user = new User();
}
public User getInstnce(){
return user;
}
}
//对外暴露一个获取User对象的静态方法
public static User getInstance(){
return SingletonEnum.INSTANCE.getInstnce();
}
}
懒汉模式
- 静态内部类
类的静态属性只会在第一次加载类的时候初始化,所以在这里,JVM帮助我们保证了线程的安全性,在类进行初始化时,别的线程是无法进入的。使用到java内部类的加载时机,只有在内部类的静态成员被调用时才会去加载静态内部类,所以同样是延迟加载,效率高,不会造成内存浪费。只要处理好克隆、序列化以及反射的问题,这种单例模式也是非常推荐使用的。
public class Singleton implements Serializable{
private Singleton() {
//如果已存在,直接抛出异常,保证只会被new 一次,解决反射破坏单例的方案
if (InnerClass.singleton != null) {
throw new RuntimeException("对象已存在不可重复创建");
}
}
private static class InnerClass{
private static Singleton singleton = new Singleton ();
}
public static Singleton getInstance(){
return InnerClass.singleton;
}
//解决被序列化破坏单例的问题
private Object readResolve(){
return InnerClass.singleton;
}
}
- 双重校验锁(DCL)
在类加载时,不创建实例,因此类加载速度快,但运行时获取对象的速度慢。volatile+synchronized在Java 5以上能保证线程安全(Java 5 以前的 JMM (Java 内存模型)是存在缺陷的,即时将变量声明成 volatile 也不能完全避免重排序),只要考虑好克隆,序列化以及反射的问题,是建议使用的单例,也目前使用最广泛的单例。
public class Singleton implements Serializable{
//volatile防止指令重排序,内存可见(缓存中的变化及时刷到主存,并且其他的线程副本内存失效,必须从主存获取),但不保证原子性
private static volatile Singleton singleton = null;
private Singleton() {
//如果已存在,直接抛出异常,保证只会被new 一次,解决反射破坏单例的方案
if (singleton != null) {
throw new RuntimeException("对象已存在不可重复创建");
}
}
public static Singleton getInstance(){
//第一次判断,假设会有好多线程,如果singleton 没有被实例化,那么就会到下一步获取锁,只有一个能获取到,
//如果已经实例化,那么直接返回了,减少除了初始化时之外的所有锁获取等待过程
//如果没有第一次判断的话,在多线程高并发情况下每个线程都要获取synchronized锁,这是非常耗内存的事
if(singleton == null){
synchronized (Singleton.class){
//第二次判断是因为假设有两个线程A、B,两个同时通过了第一个if,然后A获取了锁,进入然后判断singleton是null,他就实例化了singleton,然后他出了锁,
//这时候线程B经过等待A释放的锁,B获取锁了,如果没有第二个判断,那么他还是会去new Singleton(),再创建一个实例,所以为了防止这种情况,需要第二次判断
if(singleton == null){
//下面这句代码其实分为三步:
//1.开辟内存分配给这个对象
//2.初始化对象
//3.将内存地址赋给虚拟机栈内存中的singleton变量
//注意上面这三步,如果没有volatile修饰变量singleton,第2步和第3步的顺序是随机的,这是计算机指令重排序的问题
//假设有两个线程,其中一个线程执行下面这行代码,如果第三步先执行了,就会把没有初始化的内存赋值给singleton
//然后恰好这时候有另一个线程执行了第一个判断if(singleton == null),然后就会发现singleton指向了一个内存地址
//这另一个线程就直接返回了这个没有初始化的内存,就会出问题。
singleton = new Singleton();
}
}
}
return singleton;
}
//解决被序列化破坏单例的问题
private Object readResolve(){
return singleton;
}
}
可能很多人对内存可见、指令重排序、原子性、线程副本内存、主存等概念一知半解,下面我们针对volatile来详细说明。
volatile通常被比喻成"轻量级的synchronized",也是Java并发编程中比较重要的一个关键字。和synchronized不同,volatile是一个变量修饰符,只能用来修饰变量。无法修饰方法及代码块等。volatile的用法比较简单,只需要在声明一个可能被多线程同时访问的变量时,使用volatile修饰就可以了。
主内存和工作内存
Java内存模型规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了该线程中是用到的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需要自己的工作内存和主存之间进行数据同步进行。所以,就可能出现线程1改了某个变量的值,但是线程2不可见的情况。
缓存一致性协议
每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器要对这个数据进行修改操作的时候,会强制重新从系统内存里把数据读到处理器缓存里。
volatile的原理
为了提高处理器的执行速度,在处理器和内存之间增加了多级缓存来提升。但是由于引入了多级缓存,就存在缓存数据不一致问题。但是,对于volatile变量,当对volatile变量进行写操作的时候,JVM会向处理器发送一条lock前缀的指令,将这个缓存中的变量回写到系统主存中。但是就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题,所以在多处理器下,为了保证各个处理器的缓存是一致的,就会实现上面提到的缓存一致性协议。
所以,如果一个变量被volatile所修饰的话,在每次数据变化之后,其值都会被强制刷入主存。而其他处理器的缓存由于遵守了缓存一致性协议,也会把这个变量的值从主存加载到自己的缓存中。这就保证了一个volatile在并发编程中,其值在多个缓存中是内存可见的
volatile与可见性
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。Java中的volatile关键字提供了一个功能,那就是被其修饰的变量在被修改后可以立即同步到主内存,被其修饰的变量在每次是用之前都从主内存刷新。因此,可以使用volatile来保证多线程操作时变量的可见性。
volatile与指令重排
有序性即程序执行的顺序按照代码的先后顺序执行。除了引入了时间片以外,由于处理器优化和指令重排等,CPU还可能对输入代码进行乱序执行,比如load->add->save 有可能被优化成load->save->add 。这就是可能存在有序性问题。
而volatile除了可以保证数据的可见性之外,还有一个强大的功能,那就是他可以禁止指令重排优化等。普通的变量仅仅会保证在该方法的执行过程中所依赖的赋值结果的地方都能获得正确的结果,而不能保证变量的赋值操作的顺序与程序代码中的执行顺序一致。volatile可以禁止指令重排,这就保证了代码的程序会严格按照代码的先后顺序执行。这就保证了有序性。被volatile修饰的变量的操作,会严格按照代码顺序执行:load->add->save。
volatile与原子性
原子性是指一个操作是不可中断的,要全部执行完成,要不就都不执行。线程是CPU调度的基本单位。CPU有时间片的概念,会根据不同的调度算法进行线程调度。当一个线程获得时间片之后开始执行,在时间片耗尽之后,就会失去CPU使用权。所以在多线程场景下,由于时间片在线程间轮换,就会发生原子性问题。为了保证原子性,需要通过字节码指令monitorenter和monitorexit,但是volatile和这两个指令之间是没有任何关系的。所以,volatile是不能保证原子性的。可使用其他方式来保证原子性,如synchronized或者concurrent包等。我们举一个volatile修饰的count++变量:
count++; 这条语句由3条指令组成:
(1)将 count 的值从内存加载到 cpu 的某个寄存器r
(2)将 寄存器r 的值 +1,结果存放在 寄存器s
(3)将 寄存器s 中的值写回内存
所以,如果有多个线程同时在执行 count++;,在某个线程执行完第(3)步之前,其它线程是看不到它的执行结果的。在没有 volatile 的时候,执行完 count++,执行结果其实是写到CPU缓存中,没有马上写回到内存中,后续在某些情况下(比如CPU缓存不够用)再将CPU缓存中的值flush到内存。正因为没有马上写到内存,所以不能保证其它线程可以及时见到执行的结果。在有 volatile 的时候,执行完 count++,执行结果写到CPU缓存中,并且同时写回到内存,因为已经写回内存了,所以可以保证其它线程马上看到执行的结果。但是,volatile 并没有保证原子性,在某个线程执行(1)(2)(3)的时候,volatile 并没有锁定 count 的值,也就是并不能阻塞其他线程也执行(1)(2)(3)。可能有两个线程同时执行(1),所以(2)计算出来一样的结果,然后(3)存回的也是同一个值。最后可能会出现,最后结果少于++的个数。
优点
- 在单例模式中,活动的单例只有一个实例,对单例类的所有实例化得到的都是相同的一个实例。这样就 防止其它对象对自己的实例化,确保所有的对象都访问一个实例
- 单例模式具有一定的伸缩性,类自己来控制实例化进程,类就在改变实例化进程上有相应的伸缩性。
- 提供了对唯一实例的受控访问。
- 由于在系统内存中只存在一个对象,因此可以 节约系统资源,当 需要频繁创建和销毁的对象时单例模式无疑可以提高系统的性能。
- 避免对共享资源的多重占用。
缺点
- 不适用于变化的对象,如果同一类型的对象总是要在不同的用例场景发生变化,单例就会引起数据的错误,不能保存彼此的状态。
- 由于单利模式中没有抽象层,因此单例类的扩展有很大的困难。
- 单例类的职责过重,在一定程度上违背了“单一职责原则”。
- 滥用单例将带来一些负面问题,如为了节省资源将数据库连接池对象设计为的单例类,可能会导致共享连接池对象的程序过多而出现连接池溢出;如果实例化的对象长时间不被利用,系统会认为是垃圾而被回收,这将导致对象状态的丢失。
适用场景
- 需要频繁实例化然后销毁的对象。
- 创建对象时耗时过多或者耗资源过多,但又经常用到的对象。
- 有状态的工具类对象。
- 频繁访问数据库或文件的对象。
Android中的单例模式
- InputMethodManager
系统的输入法操作类就是一个单例模式,只是少了一层非空判断。应用层暂无法调用,值供底层使用,相信底层已经做了线程安全的考虑。
static InputMethodManager sInstance;
public static InputMethodManager getInstance() {
synchronized (InputMethodManager.class) {
if (sInstance == null) {
try {
sInstance = new InputMethodManager(Looper.getMainLooper());
} catch (ServiceNotFoundException e) {
throw new IllegalStateException(e);
}
}
return sInstance;
}
}
2、Builder模式
定义:将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
Builder模式能够避免创建对象时,传递各种组合的构造参数,让它支持链式调用,使代码可读性大大增强。假设有一个Car类,我们通过该Car类来构建一大批汽车,这个Car类里有很多属性,最常见的比如颜色,价格等等:
public class Car {
Color color;
double price;
public Color getColor() {
return color;
}
public void setColor(Color color) {
this.color = color;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
//外部类提供一个私有构造函数供内部类调用,
//在该构造函数中完成成员变量的赋值,取值为Builder对象中对应的成变量的值。
private Car(Builder builder) {
this.color = builder.color;
this.price = builder.price;
}
//定义一个静态内部类Builder,内部的成员变量和外部类一样
public static class Builder {
Color color;
double price;
//Builder类通过一系列的方法用于成员变量的赋值,并返回当前对象本身(this)
public Builder color(Color color){
this.color=color;
return this;
}
//Builder类通过一系列的方法用于成员变量的赋值,并返回当前对象本身(this)
public Builder price(double price){
this.price=price;
return this;
}
//Builder类提供一个外部类的创建方法(build、create),
//该方法内部调用了外部类的一个私有构造函数,入参就是内部类Builder
public Car build() {
//build或者create构建对象
return new Car(this);
}
}
}
使用的时候:
Car car = new Car.Builder()
.color(Color.BLUE)
.price(129800)
.build();
综上,我们总结一下build模式的要点:
- 1、定义一个静态内部类Builder,内部的成员变量和外部类一样。
- 2、Builder类通过一系列的方法用于成员变量的赋值,并返回当前对象本身(this)。
- 3、Builder类提供一个外部类的创建方法(build、create),该方法内部调用了外部类的一个私有构造函数,入参就是内部类Builder。
- 4、外部类提供一个私有构造函数供内部类调用,在该构造函数中完成成员变量的赋值,取值为Builder对象中对应的成变量的值。
优点
Builder模式通常作为配置类的构建器将配置的构建和表示分离开来,同时也是将配置从目标类中隔离出来,避免作为过多的setter方法,并且隐藏内部的细节。Builder模式比较常见的实现形式是通过链式调用,这样使得代码更加简洁、易懂。
缺点
内部类与外部类相互引用,可能会导致内存消耗比增大,不过鉴于现在的手机内存来讲,这点几乎影响比较小。
使用场景
- 复杂对象的创建,内部包含多个部件或者零件,都可以装配到一个对象中。.如AlertDialog.Builder()。
- 用于框架的初始化,初始化之后无法对框架内部数据再做改动。如FileDownloader框架的初始化。
- 创建或初始化对象时,参数多,并且参数都具有默认值。
Android中的Builder模式
- AlertDialog
我们经常用到对话框,其实对话框就是基于Builder模式创建的。
AlertDialog.Builder builder = new AlertDialog.Builder(this);
AlertDialog dialog=builder.setTitle("对话框")
.setIcon(android.R.drawable.ic_dialog)
.setView(R.layout.custom_view)
.create();
dialog.show();
3、策略模式
策略模式定义了一些列的算法,并将每一个算法封装起来,而且使它们还可以相互替换。策略模式让算法独立于使用它的客户而独立变换。
举个例子:假设我们要返工,而返工的方式有很多策略,有步行,有坐火车,有坐飞机等等。而如果不使用任何模式,我们的代码可能就是这样子的。
public class WorkStrategy{
enum Strategy{
WALK,PLANE,SUBWAY
}
private Strategy strategy;
public WorkStrategy(Strategy strategy){
this.strategy=strategy;
}
public void backToWork(){
if(strategy == Strategy.WALK){
print("walk");
}else if(strategy == Strategy.PLANE){
print("plane");
}else if(strategy == Strategy.SUBWAY){
print("subway");
}
}
public static void main(String[] args) {
//可选有Strategy.PLANE、Strategy.SUBWAY
WorkStrategy walk=new WorkStrategy(Strategy.WALK);//
walk.backToWork();
}
}
这样做有一个致命的缺点,一旦出行的方式要增加,我们就不得不增加新的else if语句,而这违反了面向对象的原则之一,对修改封闭。而这时候,策略模式则可以完美的解决这一切。
- 首先,需要定义一个策略接口。
public interface Strategy {
void backToWork();
}
- 然后根据不同的出行方式实行对应的接口
public class WalkStrategy implements Strategy{
@Override
public void backToWork() {
System.out.println("walk");
}
}
public class PlaneStrategy implements Strategy{
@Override
public void backToWork() {
System.out.println("plane");
}
}
public class SubwayStrategy implements Strategy{
@Override
public void backToWork() {
System.out.println("subway");
}
}
- 此外还需要一个包装策略的类,并调用策略接口中的方法
public class WorkStrategy{
Strategy strategy;
public void setStrategy(Strategy strategy) {
this.strategy = strategy;
}
public void backToWork() {
if (strategy != null) {
strategy.backToWork();
}
}
}
- 测试一下代码
public class Main {
public static void main(String[] args) {
WorkStrategy workContext=new WorkStrategy();
//可选有new WalkStrategy()、new SubwayStrategy()
workContext.setStrategy(new PlaneStrategy());
workContext.backToWork();
}
}
可以看到,应用了策略模式后,如果我们想增加新的出行方式,完全不必要修改现有的类,我们只需要实现策略接口即可,这就是面向对象中的对扩展开放准则。假设现在我们增加了一种自行车出行的方式。只需新增一个类即可。
public class BikeStrategy implements Strategy{
@Override
public void backToWork() {
System.out.println("bike");
}
}
优点
- 策略模式提供了管理相关的算法族的办法。策略类的等级结构定义了一个算法或行为族。恰当使用继承可以把公共的代码移到父类里面,从而避免重复的代码。
- 策略模式提供了可以替换继承关系的办法。继承可以处理多种算法或行为。如果不是用策略模式,那么使用算法或行为的环境类就可能会有一些子类,每一个子类提供一个不同的算法或行为。但是,这样一来算法或行为的使用者就和算法或行为本身混在一起。决定使用哪一种算法或采取哪一种行为的逻辑就和算法或行为的逻辑混合在一起,从而不可能再独立演化。继承使得动态改变算法或行为变得不可能。
- 使用策略模式可以避免使用多重条件转移语句。多重转移语句不易维护,它把采取哪一种算法或采取哪一种行为的逻辑与算法或行为的逻辑混合在一起,统统列在一个多重转移语句里面,比使用继承的办法还要原始和落后。
缺点
- 客户端必须知道所有的策略类,并自行决定使用哪一个策略类。这就意味着客户端必须理解这些算法的区别,以便适时选择恰当的算法类。换言之,策略模式只适用于客户端知道所有的算法或行为的情况。
- 策略模式造成很多的策略类。有时候可以通过把依赖于环境的状态保存到客户端里面,而将策略类设计成可共享的,这样策略类实例可以被不同客户端使用。换言之,可以使用享元模式来减少对象的数量。
使用场景
- 如果在一个系统里面有许多类,它们之间的区别仅在于它们的行为,那么使用策略模式可以动态地让一个对象在许多行为中选择一种行为。
- 一个系统需要动态地在几种算法中选择一种。那么这些算法可以包装到一个个的具体算法类里面,而这些具体算法类都是一个抽象算法类的子类。换言之,这些具体算法类均有统一的接口,由于多态性原则,客户端可以选择使用任何一个具体算法类,并只持有一个数据类型是抽象算法类的对象。
- 一个系统的算法使用的数据不可以让客户端知道。策略模式可以避免让客户端涉及到不必要接触到的复杂的和只与算法有关的数据。
- 如果一个对象有很多的行为,如果不用恰当的模式,这些行为就只好使用多重的条件选择语句来实现。
Android中的策略模式
- ValueAnimator
我们知道,在属性动画中,有一个东西叫做插值器,它的作用就是根据时间流逝的百分比来来计算出当前属性值改变的百分比。平时我们使用的时候,通过设置不同的插值器,实现不同的动画速率变换效果,比如线性变换,回弹,自由落体等等。这些都是插值器接口的具体实现,也就是具体的插值器策略。
ValueAnimator animator = ValueAnimator.ofInt(0, percent);
animator.addUpdateListener((animation) -> {
int currentValue = (int) animation.getAnimatedValue();
//doSomething();
});
//属性值变化的策略,可替换策略:LinearInterpolator、AccelerateDecelerateInterpolator、DecelerateInterpolator等
animator.setInterpolator(new OvershootInterpolator());
animator.setDuration(1000);
animator.start();
4、观察者模式
定义对象间的一种一对多的依赖关系,当一个对象的状态发送改变时,所有依赖于它的对象都能得到通知并被自动更新。
举个例子:有一种短信服务,比如天气预报服务,一旦你订阅该服务,你只需按月付费,付完费后,每天一旦有天气信息更新,它就会及时向你发送最新的天气信息。这些被订阅的事物可以拥有多个订阅者,也就是一对多的关系。当然,严格意义上讲,这个一对多可以包含一对一,因为一对一是一对多的特例。
观察者:我们称它为Observer,有时候我们也称它为订阅者,即Subscriber。
被观察者:我们称它为Observable,即可以被观察的东西,有时候还会称之为主题,即Subject。
我们以天气为例子:
//天气实体,订阅的天气对象
public class Weather {
private String description;//天气内容
public Weather(String description) {
this.description = description;
}
public String getDescription() {
return description;
}
}
//订阅回调接口
public interface Observer<T> {
void onUpdate(Observable<T> observable,T data);
}
//被订阅者
public class Observable<T> {
//所有的订阅对象列表
List<Observer<T>> mObservers = new ArrayList<Observer<T>>();
//订阅者注册订阅
public void register(Observer<T> observer) {
synchronized (this) {
//考虑多线程同步注册问题
if (!mObservers.contains(observer))
mObservers.add(observer);
}
}
//订阅者解除订阅
public synchronized void unregister(Observer<T> observer) {
mObservers.remove(observer);
}
//有新消息通知观察者
public void notifyObservers(T data) {
for (Observer<T> observer : mObservers) {
observer.onUpdate(this, data);
}
}
}
测试:
//被观察者
Observable<Weather> observable = new Observable<Weather>();
//观察者1
Observer<Weather> observer1 = new Observer<Weather>() {
@Override
public void onUpdate(Observable<Weather> observable, Weather data) {
System.out.println("观察者1:"+data.getDescription());
}
};
//观察者2
Observer<Weather> observer2 = new Observer<Weather>() {
@Override
public void onUpdate(Observable<Weather> observable, Weather data) {
System.out.println("观察者2:"+data.getDescription());
}
};
observable.register(observer1);
observable.register(observer2);
Weather weather1 = new Weather("晴转多云");
observable.notifyObservers(weather1); //观察者1和观察者2都能收到消息
observable.unregister(observer1); //观察者1解除订阅
Weather weather2 = new Weather("多云转阴");
observable.notifyObservers(weather2); //只有观察者2收到消息
优点
- 观察者模式在被观察者和观察者之间建立一个抽象的耦合。被观察者角色所知道的只是一个具体观察者列表,每一个具体观察者都符合一个抽象观察者的接口。被观察者并不认识任何一个具体观察者,它只知道它们都有一个共同的接口。
由于被观察者和观察者没有紧密地耦合在一起,因此它们可以属.于不同的抽象化层次。如果被观察者和观察者都被扔到一起,那么这个对象必然跨越抽象化和具体化层次。 - 观察者模式支持广播通讯。被观察者会向所有的登记过的观察者发出通知。
缺点
- 如果一个被观察者对象有很多的直接和间接的观察者的话,将所有的观察者都通知到会花费很多时间。
- 如果在被观察者之间有循环依赖的话,被观察者会触发它们之间进行循环调用,导致系统崩溃。在使用观察者模式是要特别注意这一点。
- 如果对观察者的通知是通过另外的线程进行异步投递的话,系统必须保证投递是以自恰的方式进行的。
- 虽然观察者模式可以随时使观察者知道所观察的对象发生了变化,但是观察者模式没有相应的机制使观察者知道所观察的对象是怎么发生变化的。
适用场景
- 对一个对象状态的更新,需要其他对象同步更新,而且其他对象的数量动态可变。
- 对象仅需要将自己的更新通知给其他对象而不需要知道其他对象的细节。
Android中的观察者模式
- LocalBroadcastManager
Android的广播机制,其本质也是观察者模式。调用registerReceiver方法注册广播,调用unregisterReceiver方法取消注册,之后直接使用sendBroadcast发送广播,发送广播之后,注册的广播会收到对应的广播信息,这就是典型的观察者模式。
LocalBroadcastManager localBroadcastManager = LocalBroadcastManager.getInstance(context);
localBroadcastManager.registerReceiver(receiver,filter);
localBroadcastManager.unregisterReceiver(receiver);
localBroadcastManager.sendBroadcast(intent)
5、适配器模式
将一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口不匹配而无法在一起工作的两个类能够在一起工作。
生活中的手机充电器就是一个适配器的例子,手机一般都是在5V的电压下进行充电,但是外部的电压都是220V,那怎么办,这就需要充电器去适配了,将220V的电压转换为5V。
根据适配器模式的定义,我们知道有三个角色参与了其中的工作:
- Target:即目标角色,如5V电源。定义把其他类转换为何种接口,也就是我们期望的接口。
- Adaptee:被适配角色,如220V电源。一般是已存在的类,需要适配新的接口。
- Adapter:适配器,把源角色接口转换为目标角色期望的接口,如220V转5V。
适配器模式的分类:
- 对象适配器模式
- 类适配器模式
下面是对象适配器的例子:
//被适配对现货:220V电源
public class ElectricAdaptee{
public int getElectric() {
return 220;
}
}
//适配器接口:220V转5V
interface Adapter {
int electric220To5();
}
//适配器实现类:将220v转为5v,输出目标角色
public class TargetAdapter implements Adapter {
private Electric mElectric;//对象适配器持有源目标对象
public PhoneAdapter(Electric electric) {
//通过构造方法传入对象
mElectric = electric;
}
@Override
public int electric220To5() {
int electric = mElectric.getElectric();
/经过一系列转换变成5V
return 5;
}
}
测试:
Electric electric = new Electric();
Adapter adapter = new PhoneAdapter(electric);//传递一个对象给适配器
System.out.println("适配转换后的电压:" + adapter .electric220To5());//220V成功转为5V
将对象适配器改为类对象适配器:
//被适配对现货:220V电源
public class ElectricAdaptee{
public int getElectric() {
return 220;
}
}
//适配器接口:220V转5V
interface Adapter {
int electric220To5();
}
//适配器实现类:将220v转为5v,输出目标角色
public class TargetAdapter extends ElectricAdaptee implements Adapter {
public PhoneAdapter(Electric electric) {
//通过构造方法传入对象
mElectric = electric;
}
@Override
public int electric220To5() {
//继承了被适配对象的方法
int electric = getElectric();
/经过一系列转换变成5V
return 5;
}
}
类适配器模式没什么优势,用得比较少,接下来把他们做一下对比:
- 类适配器采用了继承的方式来实现,而对象适配器是通过传递对象来实现,这是一种组合的方式。
- 类适配器由于采用了继承,可以重写父类的方法;对象适配器则不能修改对象本身的方法等。
- 适配器通过继承都获得了父类的方法,客户端使用时都会把这些方法暴露出去,增加了一定的使用成本;对象适配器则不会。
- 类适配器只能适配他的父类,这个父类的其他子类都不能适配到;而对象适配器可以适配不同的对象,只要这个对象的类型是同样的。
- 类适配器不需要额外的引用;对象适配器需要额外的引用来保存对象。
优点
- 将目标类和适配者类解耦,通过引入一个适配器类来重用现有的适配者类,无需修改原有结构。
- 增加了类的透明性和复用性,将具体的业务实现过程封装在适配者类中,对于客户端类而言是透明的,而且提高了适配者的复用性,同一适配者类可以在多个不同的系统中复用。
- 灵活性和扩展性都非常好,通过使用配置文件,可以很方便的更换适配器,也可以在不修改原有代码的基础上 增加新的适配器,完全符合开闭原则。
缺点
- 一次最多只能适配一个适配者类,不能同时适配多个适配者。
- 适配者类不能为最终类,在C#中不能为sealed类
- 目标抽象类只能为接口,不能为类,其使用有一定的局限性。
- 过多的使用适配器会让系统显得过于凌乱。如果不是很有必要,可以不适用适配器而是直接对系统进行重构。
应用场合
- 系统需要使用现有的类,而此类的接口不符合系统的需要,即接口不兼容。
- 想要建立一个可以重复使用的类,用于与一些彼此之间没有太大关联的一些类,包括一些可能在将来引进的一些类一起工作。
- 需要一个统一的输出接口,而输入端的接口不可预知。
Android中的适配器模式
- ListView
相信我们都用过ListView,可能现在大家都转为RecyclerView了,但是依旧会用到他们的Adapter适配器。在使用ListView时,每一项的布局和数据都不一样,但是最后输出都可以看作是一个View,这就对应了上面的适配器模式应用场景的第三条:需要一个统一的输出接口,而输入端的接口不可预知。
class Adapter extends BaseAdapter {
private List<String> mDatas;//数据源:Adapter持有数据源,典型的对象适配器模式
public Adapter(List<String> datas) {
mDatas = datas;
}
//下面的四个方法都是适配器转换的适配方案
@Override
public int getCount() {
return mDatas.size(); }
@Override
public long getItemId(int position) {
return position; }
@Override
public Object getItem(int position) {
return mDatas.get(position);}
@Override
public View getView(int position, View convertView, ViewGroup parent) {
...
return convertView;
}
}
6、模板模式
定义一个操作中的算法的框架,而将一些步骤延迟到子类中。使得子类可以不改变一个算法的结构即可重新定义该算法的某些特定步骤。
模板模式主要有两个概念:
- 抽象父类(AbstractClass):实现了模板方法,定义了算法的骨架。
- 具体子类(ConcreteClass):实现抽象类中的抽象方法,即不同的对象的具体实现细节。
我们举个简单的例子,比如我们平时做面包,按照一个步骤模板:
- 材料:不同的面包需要各种不同的配料。
- 火力:不同的面包需要各种不同的火力。
- 时间:不同的面包成型的时间不一。
public abstract class AbstractBread{
/**
* 具体的整个过程
*/
public void doBread(){
this.material();
this.fire();
this.time();
}
/**
* 需要的材料
*/
protected abstract void material();
/**
* 火力大小
*/
protected abstract void fire();
/**
* 做多长时间
*/
protected abstract void time();
}
按照这个做面包的模板,我可以做出很多种类的面包:豆沙面包、蓝莓面包等:
//红豆沙面包
public class BeanBread extends AbstractBread{
@Override
protected void material() {
System.out.println("加入面粉和红豆沙,");
}
@Override
protected void fire() {
System.out.println("微波加热,");
}
@Override
protected void time() {
System.out.println("十五分钟搞定。");
}
}
//蓝莓面包
public class BlueberryBread extends AbstractBread{
@Override
protected void material() {
System.out.println("加入面粉和蓝莓,");
}
@Override
protected void fire() {
System.out.println("光波加热,");
}
@Override
protected void time() {
System.out.println("十分钟搞定。");
}
}
现在可以做面包了:
AbstractBread beanBread = new BeanBread ();
beanBread .doBread();//加入面粉和红豆沙,微波加热,十五分钟搞定。
AbstractBread blueberryBread = new BlueberryBread ();
blueberryBread .doBread();//加入蓝莓和红豆沙,广播加热,十分钟搞定。
这样我们就实现了使用模板模式的一个完整的实例。照着这个模板,我们可以做出许许多多的面包。其实,模板模式说得通俗点一点就是 :完成一件事情,有固定的数个步骤,但是每个步骤根据对象的不同,而实现细节不同;就可以在父类中定义一个完成该事情的总方法,按照完成事件需要的步骤去调用其每个步骤的实现方法。每个步骤的具体实现,由子类完成。
优点
- 具体细节步骤实现定义在子类中,子类定义详细处理算法是不会改变算法整体结构。
- 代码复用的基本技术,在数据库设计中尤为重要。
- 存在一种反向的控制结构,通过一个父类调用其子类的操作,通过子类对父类进行扩展增加新的行为,符合“开闭原则”。
缺点
- 每个不同的实现都需要定义一个子类,会导致类的个数增加,系统更加庞大。
应用场景
- 在多个子类中拥有相同的方法,而且逻辑相同时,可以将这些方法抽出来放到一个模板抽象类中。
- 程序主框架相同,细节不同的情况下,也可以使用模板方法。
Android中的模板模式
- Activity
相信做过Android开发的人都用过Activity,同时也了解它的生命周期。Activity的生命周期函数就是个窗体模板,按照这个模板我们可以产生各种各类的窗体。
public classActivity{
protected void onCreate(){
}
protected void onStart(){
}
protected void onResume(){
}
protected void onPause(){
}
protected void onStop(){
}
protected void onDestroy(){
}
}
7、装饰者模式
动态地给一个对象添加一些额外的职责。就增加功能来说,装饰模式相比生成子类更为灵活。
装饰者模式在生活中应用实际上也非常广泛,一如一间房,放上厨具,它就是厨房;放上床,就是卧室。通常我们扩展类的功能是通过继承的方式来实现,但是装饰者模式是通过组合的方式来实现,这是继承的替代方案之一。涉及角色及说明:
- Component(抽象组件):接口或者抽象类,被装饰的最原始的对象。具体组件与抽象装饰角色的父类。
- ConcreteComponent(具体组件):实现抽象组件的接口。
- Decorator(抽象装饰角色):一般是抽象类,抽象组件的子类,同时持有一个被装饰者的引用,用来调用被装饰者的方法;同时可以给被装饰者增加新的职责。
- ConcreteDecorator(具体装饰类):抽象装饰角色的具体实现。
就以装修房间为例子,讲一下实现。
1、创建抽象组件(Component)
//这里是一个抽象房子类,定义一个装修的方法:
public abstract class Room {
public abstract void fitment();//装修方法
}
2、创建具体组件(ConcreteComponent)
//现在有一间新房子,实现了装修的具体步骤,继承Room
public class NewRoom extends Room {
@Override
public void fitment() {
System.out.println("拿着要装修的家具,放在了指定的位置。");
}
}
3、创建抽象装饰角色(Decorator)
//定义一个抽象的装饰角色,继承Room,拥有父类相同的方法
public abstract class RoomDecorator extends Room {
private Room mRoom;//持有被装饰者的引用,这里是需要装修的房间
public RoomDecorator(Room room) {
this.mRoom = room;
}
@Override
public void fitment() {
mRoom.fitment();//调用被装饰者的方法
}
}
4、创建具体装饰类(ConcreteDecorator)
//卧室类,继承自RoomDecorator
public class Bedroom extends RoomDecorator {
public Bedroom(Room room) {
super(room);
}
@Override
public void fitment() {
super.fitment();
addBedding();
}
private void addBedding() {
System.out.println("装修成卧室:添加卧具。");
}
}
//厨房类,继承自RoomDecorator
public class Kitchen extends RoomDecorator {
public Kitchen(Room room) {
super(room);
}
@Override
public void fitment() {
super.fitment();
addKitchenware();
}
private void addKitchenware() {
System.out.println("装修成厨房:添加厨具。");
}
}
客户端测试:
Room newRoom = new NewRoom();//有一间新房间
RoomDecorator bedroom = new Bedroom(newRoom);
bedroom.fitment();//装修成卧室:添加卧具。拿着要装修的家具,放在了指定的位置。
RoomDecorator kitchen = new Kitchen(newRoom);
kitchen.fitment();//装修成厨房:添加厨具。拿着要装修的家具,放在了指定的位置。
优点
- 采用组合的方式,可以动态的扩展功能,同时也可以在运行时选择不同的装饰器,来实现不同的功能。
- 有效避免了使用继承的方式扩展对象功能而带来的灵活性差,子类无限制扩张的问题。
- 被装饰者与装饰者解偶,被装饰者可以不知道装饰者的存在,同时新增功能时原有代码也无需改变,符合开放封闭原则。
缺点
- 装饰层过多的话,维护起来比较困难。
- 如果要修改抽象组件这个基类的话,后面的一些子类可能也需跟着修改,较容易出错。
应用场景
- 需要扩展一个类的功能,或给一个类增加附加功能时。
- 需要动态的给一个对象增加功能,这些功能可以再动态的撤销。
- 当不能采用继承的方式对系统进行扩充或者采用继承不利于系统扩展和维护时。
Android中的装饰着模式
- Context
Context是个由Android系统提供其实现的抽象类,它是提供应用环境(application environment)信息的接口。通过它可以访问到应用的资源和类,以及进行一些系统级别的操作,比如加载activity、发送广播和接收intent等。Context整个继承装饰体系就是采用装饰着模式。

我们以**startActivit()**方法看下它在Context体系是如何继承装饰的。
1、抽象组件(Component)
public abstract class Context {
public abstract void startActivity(@RequiresPermission Intent intent,@Nullable Bundle options);
}
2、具体组件(ConcreteComponent)
ContextImpl是Context的具体实现类,源码位于android.app包中,但它在API文档中找不到,是一个默认访问权限的类,也就是说它只允许android.app包中的类可以调用它,或者只有和它同包的类才可以通过其父类的方法使用它。它为Activity、Service等应用组件提供基本的context对象。
class ContextImpl extends Context {
@Override
public void startActivity(Intent intent, Bundle options) {
warnIfCallingFromSystemProcess();
// Calling start activity from outside an activity without FLAG_ACTIVITY_NEW_TASK is
// generally not allowed, except if the caller specifies the task id the activity should
// be launched in.
if ((intent.getFlags() & Intent.FLAG_ACTIVITY_NEW_TASK) == 0
&& options != null && ActivityOptions.fromBundle(options).getLaunchTaskId() == -1) {
throw new AndroidRuntimeException(
"Calling startActivity() from outside of an Activity "
+ " context requires the FLAG_ACTIVITY_NEW_TASK flag."
+ " Is this really what you want?");
}
mMainThread.getInstrumentation().execStartActivity(
getOuterContext(), mMainThread.getApplicationThread(), null,
(Activity) null, intent, -1, options);
}
}
3、抽象装饰角色(Decorator)
ContextWrapper是Context类的代理实现,ContextWrapper中实现Context的方法全是通过mBase来实现的。这样它(ContextWrapper)派生出的子类就可以在不改变原始context(mBase)的情况下扩展Context的行为。
public class ContextWrapper extends Context {
//Context包装类
Context mBase;//持有Context引用
public ContextWrapper(Context base) {
//这里的base实际上就是ContextImpl
mBase = base;
}
@Override
public void startActivity(Intent intent) {
mBase.startActivity(intent);//调用ContextImpl的startActivity()方法
}
}
4、具体装饰类(ConcreteDecorator)
ContextThemeWrapper继承ContextWrapper,Activity 继承ContextThemeWrapper并重写了ContextWrapper的startActivity()函数内部处理。其他的Service和Application等都大同小异,只不过扩展了不同的行为。
public class Activity extends ContextThemeWrapper{
@Override
public void startActivity(Intent intent, @Nullable Bundle options) {
if (options != null) {
startActivityForResult(intent, -1, options);
} else {
// Note we want to go through this call for compatibility with
// applications that may have overridden the method.
startActivityForResult(intent, -1);
}
}
}
8、原型模式
用原型实例指定创建对象的种类,并通过拷贝这些原型创建新的对象。
简单来说就是拷贝一个对象,但是要注意深拷贝和浅拷贝。下面举例子:
//1、实现Cloneable接口
public class Person implements Cloneable{
private String name;
private int age;
public Person(){
}
//...省略get和set
//2、实现clone方法中的拷贝逻辑
@Override
public Object clone(){
Person person = null;
try {
person=(Person)super.clone();
person.name = this.name;
person.age = this.age;
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return person;
}
}
测试:
Person p1=new Person();
p1.setName("张三");
p1.setAge(18);
System.out.println(p);//Person{name=’张三’, age=18}
Person p2= (Person) p.clone();
System.out.println(p2);//Person{name=’张三’, age=18}
p2.setName("李四");
System.out.println(p1);//Person{name=’张三’, age=18}
System.out.println(p2);//Person{name=’李四’, age=18}
试想一下,两个不同的人,除了姓名不一样,其他三个属性都一样,用原型模式进行拷贝就会显得异常简单,这也是原型模式的应用场景之一。
但是假设Person类里还有一个属性叫兴趣爱好,是一个List集合,就像这样子:
//1、实现Cloneable接口
public class Person implements Cloneable{
...
private ArrayList<String> hobbies = new ArrayList<String>();
public Person(){
}
//...省略get和set
//2、实现clone方法中的拷贝逻辑
@Override
public Object clone(){
Person person = null;
try {
person = (Person)super.clone();
...
person.hobbies = this.hobbies;
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return person;
}
}
测试:
Person p1=new Person();
p1.setName("张三");
p1.setAge(18);
ArrayList <String> hobbies=new ArrayList<String>();
hobbies.add("篮球");
hobbies.add("编程");
p.setHobbies(hobbies);
System.out.println(p);//Person{name=’张三’, age=18, hobbies=[篮球, 编程]}
Person p2= (Person) p.clone();
System.out.println(p2);//Person{name=’张三’, age=18, hobbies=[篮球, 编程]}
p2.setName("李四");
p2.getHobbies().add("游泳");
System.out.println(p1);//Person{name=’张三’, age=18, hobbies=[篮球, 编程, 游泳]}
System.out.println(p2);//Person{name=’李四’, age=18, hobbies=[篮球, 编程, 游泳]}
你会发现原来的对象的hobby也发生了变换。其实导致这个问题的本质原因是我们只进行了浅拷贝,也就是只拷贝了引用,最终两个对象指向的引用是同一个,一个发生变化另一个也会发生变换,显然解决方法就是使用深拷贝。
@Override
public Object clone(){
Person person = null;
try {
person = (Person)super.clone();
...
person.hobbies=(ArrayList<String>)this.hobbies.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return person;
}
注意person.hobbies=(ArrayList)this.hobbies.clone();,不再是直接引用而是进行了一份拷贝。再运行一下,就会发现原来的对象不会再发生变化了。
当然,深克隆还有另外一种表示:序列化。对于实现序列化接口的对象,直接用下面的代码即可实现深度克隆,非常方便:
//深克隆,对象T必须要 implements Serializable接口
public <T> T deepClone() {
T stu = null;
try {
stu = null;
ByteArrayOutputStream bo = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bo);
oos.writeObject(this);
ByteArrayInputStream bi = new ByteArrayInputStream(bo.toByteArray());
ObjectInputStream oi = new ObjectInputStream(bi);
stu = (T) oi.readObject();
} catch (Exception e) {
e.printStackTrace();
}
return stu;
}
优点
- 使用原型模型创建一个对象比直接new一个对象更有效率,因为它直接操作内存中的二进制流,特别是复制大对象时,性能的差别非常明显。
- 隐藏了制造新实例的复杂性,使得创建对象就像我们在编辑文档时的复制粘贴一样简单。
缺点
- 由于使用原型模式复制对象时不会调用类的构造方法,所以原型模式无法和单例模式组合使用,因为原型类需要将clone方法的作用域修改为public类型,那么单例模式的条件就无法满足了。
- 使用原型模式时不能有final对象。
- Object类的clone方法只会拷贝对象中的基本数据类型,对于数组,引用对象等只能另行拷贝。这里涉及到深拷贝和浅拷贝的概念。
应用场景
- 一个对象需要提供给其他对象访问,而且各个调用者可能都需要修改其值时,可以考虑使用原型模式拷贝多个对象供调用者使用,即保护性拷贝。
Android中的原型模式
- Intent
用法也显得十分简单,一旦我们要用的Intent与现有的一个Intent很多东西都是一样的,那我们就可以直接拷贝现有的Intent,再修改不同的地方,便可以直接使用。
public class Intent implements Parcelable, Cloneable{
@Override
public Object clone() {
return new Intent(this);
}
public Intent(Intent o) {
this.mAction = o.mAction;
this.mData = o.mData;
this.mType = o.mType;
this.mPackage = o.mPackage;
this.mComponent = o.mComponent;
this.mFlags = o.mFlags;
this.mContentUserHint = o.mContentUserHint;
if (o.mCategories != null) {
this.mCategories = new ArraySet<String>(o.mCategories);
}
if (o.mExtras != null) {
this.mExtras = new Bundle(o.mExtras);
}
if (o.mSourceBounds != null) {
this.mSourceBounds = new Rect(o.mSourceBounds);
}
if (o.mSelector != null) {
this.mSelector = new Intent(o.mSelector);
}
if (o.mClipData != null) {
this.mClipData = new ClipData(o.mClipData);
}
}
}
9、工厂模式
定义一个用于创建对象的接口,让子类决定实例化哪个类。
工厂模式多用于需要生成复杂对象的地方,用new就可以完成创建的对象就无需使用。由于工厂模式依赖抽象的架构,实例化的任务交由子类去完成,所以有很好的扩展性,降低了对象之间的耦合度。工厂模式可以分成三类:
- 1、工厂方法模式
- 2、简单/静态工厂模式
- 3、抽象工厂模式
因为简单/静态工厂模式是在工厂方法模式上缩减,抽象工厂模式是在工厂方法模式上再增强,所以下面将按照1、2、3的顺序讲。
工厂方法模式
工厂方法模式的实质是:定义一个创建对象的接口,但让实现这个接口的类来决定实例化哪个类。工厂方法让类的实例化推迟到子类中进行。
工厂方法模式包含如下角色:
- Product:抽象产品
- ConcreteProduct:具体产品(多个产品)
- Factory:抽象工厂
- ConcreteFactory:具体工厂(多个工厂,与产品一对一)
下面以汽车工厂造车为例:
//1、定义一个通用的汽车抽象类
public abstract class Car{
public abstract void move();//所有车都会动
}
//2、继承Car,定义奔驰汽车
public class BenzCat extends Car{
//奔驰汽车
@Override
public void move() {
System.out.println("通过汽油动起来");
}
}
//3、继承Car,定义特斯拉汽车
public class TeslaCat extends Car{
//特斯拉汽车
@Override
public void move() {
System.out.println("通过电动起来");
}
}
//4、定义造车工厂接口
public interface CarFactory{
//造车工厂
Car createCar();//负责造车
}
//5、实现造车接口,定义造奔驰工厂
public class BenzCarFactory implements CarFactory {
//奔驰工厂,负责造奔驰车
@Override
public Car createCar() {
return new BenzCat ();
}
}
//6、实现造车接口,定义造特斯拉工厂
public class TeslaCarFactory implements CarFactory {
//特斯拉工厂,负责造奔驰车
@Override
public Car createCar() {
return new TeslaCat();
}
}
测试:
CarFactory factory = new BenzCarFactory();
factory.createCar().move();//通过汽油动起来
CarFactory factory = new TeslaCarFactory();
factory.createCar().move();//通过电动起来
为了解耦,一个产品对应一个工厂。在系统中加入新产品时,无须修改抽象工厂和抽象产品提供的接口,无须修改客户端,也无须修改其他的具体工厂和具体产品,而只要添加一个具体工厂和具体产品就可以了。这样,系统的可扩展性也就变得非常好,完全符合“开闭原则”。但是也同时带来他的缺陷:增加产品,需要增加新的工厂类,导致系统类的个数成对增加,在一定程度上增加了系统的复杂性。
简单工厂模式
简单工厂模式是属于创建型模式,又叫做静态工厂方法(Static Factory Method)模式。简单工厂模式是由一个工厂对象决定创建出哪一种产品类的实例。简单工厂模式是工厂模式家族中最简单实用的模式,可以理解为是不同工厂模式的一个特殊实现。
简单工厂模式其实和他的名字一样,很简单。先来看看它的组成:
- Product:抽象产品
- ConcreteProduct:具体产品(多个产品)
- ConcreteFactory:具体工厂(单个工厂,与产品一对多)
下面还是以汽车工厂造车为例:
//1、定义一个通用的汽车抽象类
public abstract class Car{
public abstract void move();//所有车都会动
}
//2、继承Car,定义奔驰汽车
public class BenzCat extends Car{
//奔驰汽车
@Override
public void move() {
System.out.println("通过汽油动起来");
}
}
//3、继承Car,定义特斯拉汽车
public class TeslaCat extends Car{
//特斯拉汽车
@Override
public void move() {
System.out.println("通过电动起来");
}
}
//4、实现造车工厂,生产多种汽车
public class CarFactory{
//工厂,负责造各种各样的车
public static <T extends Car> T createCar(Class<T> c) {
T car = null;
try {
//通过类名(ClassName)来实例化具体的类,用的是反射机制来实现。
car = (T) Class.forName(c.getName()).newInstance();
} catch (Exception e) {
e.printStackTrace();
}
return car;
}
}
测试:
CarFactory.createCar(BenzCat.class).move();//通过汽油动起来
CarFactory.createCar(TeslaCat.class).move();//通过电动起来
简单工厂模式中,一个工厂对应多个产品,实现简单。同时屏蔽产品的具体实现,调用者只关心产品的接口。但是如果要增加新的产品,需要修改工厂类,不符合开放-封闭原则。工厂类集中了所有实例的创建逻辑,违反了高内聚责任分配原则。
抽象工厂模式
提供一个创建一系列相关或相互依赖对象的接口,而无须指定它们具体的类。
抽象工厂模式就比较复杂了,我们一般的应用都用不到。抽象工厂模式提供了一种方式,可以将同一产品族的单独的工厂封装起来。在正常使用中,客户端程序需要创建抽象工厂的具体实现,然后使用抽象工厂作为接口来创建这一主题的具体对象。客户端程序不需要知道(或关心)它从这些内部的工厂方法中获得对象的具体类型,因为客户端程序仅使用这些对象的通用接口。抽象工厂模式将一组对象的实现细节与他们的一般使用分离开来。
产品族
来认识下什么是产品族: 位于不同产品等级结构中,功能相关的产品组成的家族。如下面的例子,就有两个产品族:跑车族和商务车族。

用途
抽象工厂模式和工厂方法模式一样,都符合开放-封闭原则。但是不同的是,工厂方法模式在增加一个具体产品的时候,都要增加对应的工厂。但是抽象工厂模式只有在新增一个类型的具体产品时才需要新增工厂。也就是说,工厂方法模式的一个工厂只能创建一个具体产品。而抽象工厂模式的一个工厂可以创建属于一类类型的多种具体产品。工厂创建产品的个数介于简单工厂模式和工厂方法模式之间。
在以下情况下可以使用抽象工厂模式:
- 一个系统不应当依赖于产品类实例如何被创建、组合和表达的细节,这对于所有类型的工厂模式都是重要的。
- 系统中有多于一个的产品族,而每次只使用其中某一产品族。
- 属于同一个产品族的产品将在一起使用,这一约束必须在系统的设计中体现出来。
- 系统提供一个产品类的库,所有的产品以同样的接口出现,从而使客户端不依赖于具体实现。
抽象工厂模式包含如下角色:
- Factory(抽象工厂):用于声明生成抽象产品的方法
- ConcreteFactory(具体工厂):实现了抽象工厂声明的生成抽象产品的方法,生成一组具体产品,这些产品构成了一个产品族,每一个产品都位于某个产品等级结构中;
- Product(抽象产品):为每种产品声明接口,在抽象产品中定义了产品的抽象业务方法;
- Product(具体产品):定义具体工厂生产的具体产品对象,实现抽象产品接口中定义的业务方法。
本文的例子采用一个汽车代工厂造汽车的例子。假设我们是一家汽车代工厂商,我们负责给奔驰和特斯拉两家公司制造车子。我们简单的把奔驰车理解为需要加油的车,特斯拉为需要充电的车。其中奔驰车中包含跑车和商务车两种,特斯拉同样也包含奔驰车和商务车。

以上场景,我们就可以把跑车和商务车分别对待,对于跑车有单独的工厂创建,商务车也有单独的工厂。这样,以后无论是再帮任何其他厂商造车,只要是跑车或者商务车我们都不需要再引入工厂。同样,如果我们要增加一种其他类型的车,比如越野车,我们也不需要对跑车或者商务车的任何东西做修改。
public interface BenzCar {
//加汽油的奔驰车接口
public void gasUp();
}
public interface TeslaCar {
//充电的特斯拉接口
public void charge();
}
public class BenzSportCar implements BenzCar {
//奔驰跑车
public void gasUp() {
System.out.println("给我的奔驰跑车加最好的汽油");
}
}
public class BenzBusinessCar implements BenzCar{
//奔驰商务车
public void gasUp() {
System.out.println("给我的奔驰商务车加一般的汽油");
}
}
public class TeslaSportCar implements TeslaCar {
//特斯拉跑车
public void charge() {
System.out.println("给我特斯拉跑车冲满电");
}
}
public class TeslaBusinessCar implements TeslaCar {
//特斯拉商务车
public void charge() {
System.out.println("不用给我特斯拉商务车冲满电");
}
}
public interface CarFactory {
//汽车工厂
public BenzCar getBenzCar();
public TeslaCar getTeslaCar();
}
public class SportCarFactory implements CarFactory {
//跑车工厂
public BenzCar getBenzCar() {
return new BenzSportCar();
}
public TeslaCar getTeslaCar() {
return new TeslaSportCar();
}
}
public class BusinessCarFactory implements CarFactory {
//商务车工厂
public BenzCar getBenzCar() {
return new BenzBusinessCar();
}
public TeslaCar getTeslaCar() {
return new TeslaBusinessCar();
}
}
对于增加新的产品族,工厂方法模式很好的支持了“开闭原则”,对于新增加的产品族,只需要对应增加一个新的具体工厂即可,对已有代码无须做任何修改。对于增加新的产品等级结构,需要修改所有的工厂角色,包括抽象工厂类,在所有的工厂类中都需要增加生产新产品的方法,不能很好地支持“开闭原则”。抽象工厂模式的这种性质称为“开闭原则”的倾斜性,抽象工厂模式以一种倾斜的方式支持增加新的产品,它为新产品族的增加提供方便,但不能为新的产品等级结构的增加提供这样的方便。
优缺点
- 工厂方法模式
优点:
1、继承了简单工厂模式的优点
2、符合开放-封闭原则
缺点:
1、增加产品,需要增加新的工厂类,导致系统类的个数成对增加,在一定程度上增加了系统的复杂性。
- 简单工厂模式
优点:
1、屏蔽产品的具体实现,调用者只关心产品的接口。
2、实现简单
缺点:
1、增加产品,需要修改工厂类,不符合开放-封闭原则
2、工厂类集中了所有实例的创建逻辑,违反了高内聚责任分配原则
- 抽象工厂模式
优点:
1、是隔离了具体类的生成,使得客户并不需要知道什么被创建,而且每次可以通过具体工厂类创建一个产品族中的多个对象。
2、增加或者替换产品族比较方便,增加新的具体工厂和产品族很方便;
缺点:
1、增加新的产品等级结构很复杂,需要修改抽象工厂和所有的具体工厂类。
2、对“开闭原则”的支持呈现倾斜性。
应用场景
对于复杂对象,使用工厂方法模式相对于直接new一个实例有很大优势的场景。
Android中的工厂模式
- Calandar
日历我们经常用到,当你调用Calendar.getInstance()创建一个单例日历的时候,其实是调用Calendar静态工厂模式创建一个GregorianCalendar日历产品。只是唯一不同点就是,静态工厂和抽象产品类合在了一起,都放在Calendar抽象类中,方便调用,减少类的数量。除了Calandar,还有Executors、BitmapFactory等都采用工厂模式,具体就不分析了。
//抽象日历类+静态日历工厂的集合类
public abstract class Calendar{
public static Calendar getInstance() {
//创建产品
return createCalendar(TimeZone.getDefault(), Locale.getDefault(Locale.Category.FORMAT));
}
//创建GregorianCalendar产品
private static Calendar createCalendar(TimeZone zone,Locale aLocale){
// BEGIN Android-changed: only support GregorianCalendar here
return new GregorianCalendar(zone, aLocale);
// END Android-changed: only support GregorianCalendar here
}
}
//抽象日历类的实现
public class GregorianCalendar extends Calendar {
//方法省略
}
10、代理模式
为其他对象提供一种代理以控制这个对象的访问。
代理两个字我们平时接触的还是很多的,比如我们经常使用http代理,我们的人事代理,我们的法务代理,其实都是我们不想做一件事情,让另一个对象帮我来做这个事情.。
涉及角色及说明:
- Subject(抽象主题类):接口或者抽象类,声明真实主题与代理的共同接口方法。
- RealSubject(真实主题类):也叫做被代理类或被委托类,定义了代理所表示的真实对象,负责具体业务逻辑的执行,客户端可以通过代理类间接的调用真实主题类的方法。
- Proxy(代理类):也叫委托类,持有对真实主题类的引用,在其所实现的接口方法中调用真实主题类中相应的接口方法执行。
- Client(客户端类):使用代理模式的地方。
代理模式分为静态代理模式与动态代理模式
- 静态代理就是在程序运行前就已经存在代理类的字节码文件,代理类和委托类的关系在运行前就确定了。上面的例子实现就是静态代理。
- 动态代理类的源码是在程序运行期间根据反射等机制动态的生成,所以不存在代理类的字节码文件。代理类和委托类的关系是在程序运行时确定。
静态代理
以香港代购为例,部分大陆的人想买香港的东西只能去有通行证的人去代购:
//1、抽象主题:购买接口
public interface IPeople {
//定义人购买的接口,每个人都会买东西
void buy();
}
//2、真实主题类:广东人,具备买的能力
public class GuandDongPeople implements IPeople {
@Override
public void buy() {
//具体实现
System.out.println("广东人想要买一个香港的手机");
}
}
//3、代理类:香港代购,具备买的能力,同时持有购买者(广东人)的引用
public class AgentProxy implements IPeople {
IPeople mIPeople;//持有IPeople类的引用(广东人)
public AgentProxy(IPeople iPeople) {
mIPeople= iPeople;
}
@Override
public void buy() {
System.out.println("我是香港代购:");
mIPeople.buy();//调用了被代理者(广东人)的buy()方法,
}
}
测试:
IPeople guangdongPeople= new GuandDongPeople();//创建广东购买人
IPeople agentProxy= new AgentProxy(guangdongPeople); //创建香港代购类并将guangdongPeople作为构造函数传递
agentProxy.buy(); //调用香港代购的buy(),输出:我是香港代购:广东人想要买一个香港的手机
静态代理的局限性:
- 静态代理如果接口新增一个方法,除了所有实现类(真实主题类)需要实现这个方法外,所有代理类也需要实现此方法。增加了代码维护的复杂度。
- 代理对象只服务于一种类型的对象,如果要服务多类型的对象。必须要为每一种对象都进行代理,静态代理在程序规模稍大时就无法胜任了。
动态代理
依旧以香港代购为例:
//1、抽象主题:购买接口
public interface IPeople {
//定义人购买的接口,每个人都会买东西
void buy();
}
//2、真实主题类:广东人,具备买的能力
public class GuandDongPeople implements IPeople {
@Override
public void buy() {
//具体实现
System.out.println("广东人想要买一个香港的手机");
}
}
//3、通用的代理类:香港代购,实现InvocationHandler接口
public class AgentProxy implements InvocationHandler {
private Object obj;//被代理的对象
public AgentProxy(Object obj) {
this.obj = obj;
}
//重写invoke()方法
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("香港代购动态代理调用方法: "+method.getName());
Object result = method.invoke(obj, args);//调用被代理的对象的方法
return result;
}
}
测试:
IPeople guandDong= new GuandDongPeople();
AgentProxy agentProxy = new AgentProxy(guandDong);
ClassLoader loader = guandDong.getClass().getClassLoader(); //获取ClassLoader
IPeople agent = (People) Proxy.newProxyInstance(loader , new Class[]{
People.class}, agentProxy); //通过 Proxy 创建香港代购实例 ,实际上通过反射来实现的。
agent.buy();//香港代购动态代理调用方法: buy 广东人想要买一个香港的手机
动态代理的优点:
- 可以通过一个代理类完成全部的代理功能,接口中声明的所有方法都被转移到调用处理器一个集中的方法中处理(InvocationHandler.invoke)。当接口方法数量较多时,我们可以进行灵活处理,而不需要像静态代理那样每一个方法进行中转。
- 动态代理的应用使我们的类职责更加单一,复用性更强。
动态代理的缺点:
- 不能对类进行代理,只能对接口进行代理,如果我们的类没有实现任何接口,那么就不能使用这种方式进行动态代理(因为$Proxy()这个类集成了Proxy,Java的集成不允许出现多个父类)。
优点
- 代理作为调用者和真实主题的中间层,降低了模块间和系统的耦合性。
- 可以以一个小对象代理一个大对象,达到优化系统提高运行速度的目的。
- 代理对象能够控制调用者的访问权限,起到了保护真实主题的作用。
缺点
- 由于在调用者和真实主题之间增加了代理对象,因此可能会造成请求的处理速度变慢。
- 实现代理模式需要额外的工作(有些代理模式的实现非常复杂),从而增加了系统实现的复杂度。
应用场景
- 当一个对象不能或者不想直接访问另一个对象时,可以通过一个代理对象来间接访问。为保证客户端使用的透明性,委托对象和代理对象要实现同样的接口。
- 被访问的对象不想暴露全部内容时,可以通过代理去掉不想被访问的内容。
根据适用范围,代理模式可以分为以下几种:
- 远程代理:为一个对象在不同的地址空间提供局部代表,这样系统可以将Server部分的事项隐藏。
- 虚拟代理:如果要创建一个资源消耗较大的对象,可以先用一个代理对象表示,在真正需要的时候才真正创建。
- 保护代理:用代理对象控制对一个对象的访问,给不同的用户提供不同的访问权限。
- 智能引用:在引用原始对象的时候附加额外操作,并对指向原始对象的引用增加引用计数。
Android中的代理模式
- AIDL
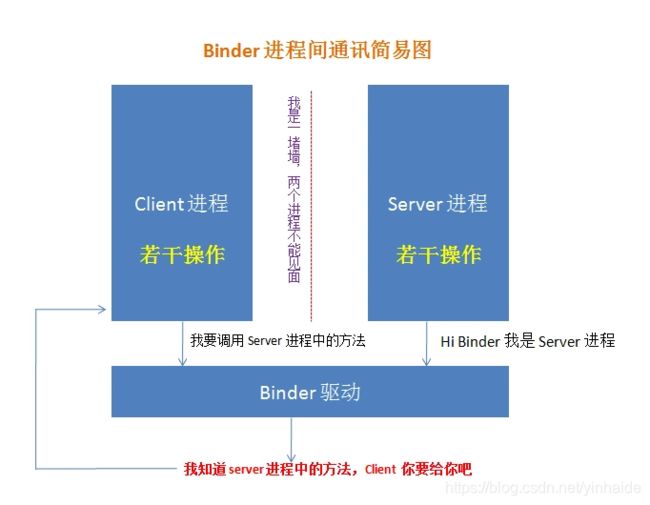
AIDL (Android Interface Definition Language) 是一种接口定义语言,用于生成可以在Android设备上两个进程之间进行进程间通信(interprocess communication, IPC)的代码。由于两个进程不能直接进行通讯(为了安全系统有进程隔离机制),而AIDL能够实现进程间通信,其内部是通过Binder机制来实现的。AIDL采用的是远程代理模式。
我们定义一个AIDL文件:
interface CustomAIDL {
String getStr() ;
}
build一下会生成文件:app\build\generated\source\aidl\debug\包名\CustomAIDL.java
public interface CustomAIDL extends android.os.Interface {
//IInterface 代表远程 Server
public static abstract class Stub extends android.os.Binder implements com.yinhaide.aidl.CustomAIDL {
//Binder的唯一标识,一般用当前的类名表示。
private static final java.lang.String DESCRIPTOR = "com.de.aidl.CustomAIDL";
//Binder绑定远程Server
public Stub() {
this.attachInterface(this, DESCRIPTOR); }
//用于将服务端的Binder对象转换为客户端需要的AIDL接口类型的对象。
public static com.de.aidl.CustomAIDL asInterface(android.os.IBinder obj) {
if ((obj == null)) {
return null;}
android.os.IInterface iin = obj.queryLocalInterface(DESCRIPTOR);
cliet 和 Server是否在同一个进程
if (((iin != null) && (iin instanceof com.de.aodl.CustomAIDL))) {
return ((com.de.aidl.CustomAIDL) win);
}
return new com.de.aidl.CustomAIDL.Stub.Proxy(obj);//远程代理
}
@Override
public android.os.IBinder asBinder() {
return this;}//返回Binder对象
@Override
public boolean onTransact(int code, android.os.Parcel data, android.os.Parcel reply, int flags) throws android.os.RemoteException {
//此方法运行在服务端中的Binder线程池中,当客户端发起跨进程请求时,远程请求会通过系统底层封装后交由此方法处理。
case INTERFACE_TRANSACTION: {
reply.writeString(DESCRIPTOR);
return true;
}
case TRANSACTION_getStr: {
data.enforceInterface(DESCRIPTOR);
java.lang.String _result = this.getStr();
reply.writeNoException();
reply.writeString(_result);
return true;
}
}
return super.onTransact(code, data, reply, flags);
}
// 此方法运行在客户端,实现对远程对象的访问
private static class Proxy implements com.de.aodl.CustomAIDL {
private android.os.Binder mRemote;
Proxy(android.os.IBinder remote) {
mRemote = remote; }
@Override
public android.os.IBinder asBinder() {
return mRemote; }
public java.lang.String getInterfaceDescriptor() {
return DESCRIPTOR; }
@Override
public java.lang.String getStr() throws android.os.RemoteException {
//读取服务端写过来的数据
android.os.Parcel _data = android.os.Parcel.obtain();
android.os.Parcel _reply = android.os.Parcel.obtain();
java.lang.String _result;
try {
_data.writeInterfaceToken(DESCRIPTOR);
mRemote.transact(Stub.TRANSACTION_getStr, _data, _reply, 0);
_reply.readException();
_result = _reply.readString();
} finally {
_reply.recycle();
_data.recycle();
}
return _result;
}
}
static final int TRANSACTION_getStr = (android.os.IBinder.FIRST_CALL_TRANSACTION + 0);
}
public java.lang.String getStr() throws android.os.RemoteException;
}
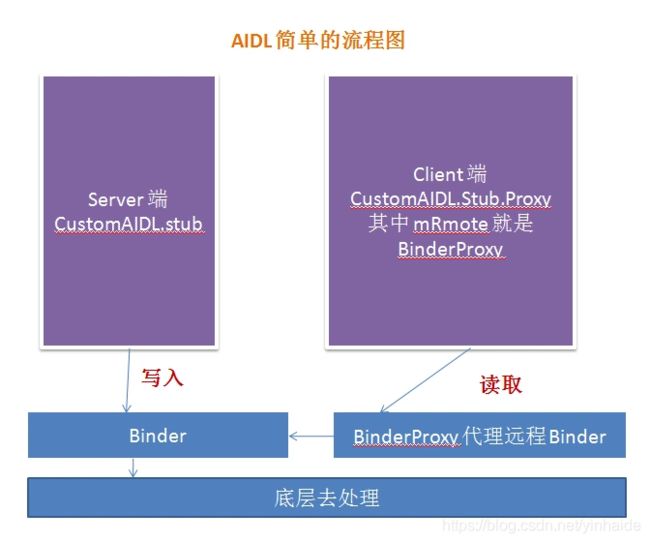
上面的图就是一个简单的 AIDL 的流程图,方便理解认为 CustomAIDL.stub 就是远程进程,它把信息注册到 Binder 中, CustomAIDL.Stub.Proxy 就是一个代理,代理什么呢?代理远程的 Binder ,远程 Binder 把方法传给 Client 就完成了两个进程间通信。
11、状态模式
行为是由状态来决定的,不同状态下有不同行为。
状态模式和策略模式的结构几乎是一模一样的,主要是他们表达的目的和本质是不同。状态模式的行为是平行的、不可替换的,策略模式的行为是彼此独立可相互替换的。
Android中的状态模式
- WIFI
当WIFI开启时,自动扫描周围的接入点,然后以列表的形式展示;当wifi关闭时则清空。这里wifi管理模块就是根据不同的状态执行不同的行为。
12、责任链模式
使多个对象都有机会处理请求,从而避免请求的发送者和接受者直接的耦合关系,将这些对象连成一条链,并沿这条链传递该请求,直到有对象处理它为止。
其实理解也不难,当一个系统存在多级关系就会存在责任链,怎么处理责任链时间关系就是这里所说的责任链模式。
Android中的责任链模式
- View
在Android处理点击事件时,父View先接收到点击事件,如果父View不处理则交给子View,依次往下传递~
13、解释器模式
给定一个语言,定义它的语法,并定义一个解释器,这个解释器用于解析语言。
从定义中看起来比较抽象,其实,很简单,很容易理解!就是相当于自定义一个格式的文件,然后去解析它。不用理解的那么复杂!
Android中的解释器模式
- AndroidManifest.xml
四大组件需要在AndroidManifest.xml中定义,其实AndroidManifest.xml就定义了,等标签(语句)的属性以及其子标签,规定了具体的使用(语法),通过PackageManagerService(解释器)进行解析。
14、命令模式
命令模式将每个请求封装成一个对象,从而让用户使用不同的请求把客户端参数化;将请求进行排队或者记录请求日志,以及支持可撤销操作。
举个例子来理解:当我们点击“关机”命令,系统会执行一系列操作,比如暂停事件处理、保存系统配置、结束程序进程、调用内核命令关闭计算机等等,这些命令封装从不同的对象,然后放入到队列中一个个去执行,还可以提供撤销操作。
Android中的命令模式
- KeyEvent
一个比较典型的例子就是在Android事件机制中,底层逻辑对事件的转发处理。每次的按键事件会被封装成NotifyKeyArgs对象。通过InputDispatcher封装具体的事件操作。
15、备忘录模式
在不破坏封闭的前提下,捕获一个对象的内部状态,并在对象之外保存这个状态,这样,以后就可将对象恢复到原先保存的状态中。
其实就是相当于一个提前备份,一旦出现啥意外,能够恢复。像我们平时用的word软件,意外关闭了,它能帮我们恢复。其实就是它自动帮我们备份过。
Android中的备忘录模式
- onSaveInstanceState
Activity的onSaveInstanceState和onRestoreInstanceState就是用到了备忘录模式,分别用于保存和恢复。
16、迭代器模式
提供一种方法顺序访问一个容器对象中的各个元素,而不需要暴露该对象的内部表示。
相信熟悉Java的你肯定知道,Java中就有迭代器Iterator类,本质上说,它就是用迭代器模式。
Android中的迭代器模式
- Cursor
最典型的就是Cursor用到了迭代器模式,当我们使用SQLiteDatabase的query方法时,返回的就是Cursor对象,通过如下方式去遍历:while(cursor.moveToNext)。
17、访问者模式
封装一些作用于某种数据结构中各元素的操作,它可以在不改变这个数据结构的前提下定义作用于这些元素的新的操作。
访问者模式是23种设计模式中最复杂的一个,但他的使用率并不高,大部分情况下,我们不需要使用访问者模式,少数特定的场景才需要。
Android中的访问者模式
- APT
Android中运用访问者模式,其实主要是在编译期注解中,编译期注解核心原理依赖APT(Annotation Processing Tools),著名的开源库比如ButterKnife、Dagger、Retrofit都是基于APT。APT的详细使用这里不提。
18、中介者模式
中介者模式包装了一系列对象相互作用的方式,使得这些对象不必相互明显调用,从而使他们可以轻松耦合。当某些对象之间的作用发生改变时,不会立即影响其他的一些对象之间的作用保证这些作用可以彼此独立的变化,中介者模式将多对多的相互作用转为一对多的相互作用。
什么时候用中介者模式呢?其实,中介者对象是将系统从网状结构转为以调停者为中心的星型结构。
举个简单的例子,一台电脑包括:CPU、内存、显卡、IO设备。其实,要启动一台计算机,有了CPU和内存就够了。当然,如果你需要连接显示器显示画面,那就得加显卡,如果你需要存储数据,那就要IO设备,但是这并不是最重要的,它们只是分割开来的普通零件而已,我们需要一样东西把这些零件整合起来,变成一个完整体,这个东西就是主板。主板就是起到中介者的作用,任何两个模块之间的通信都会经过主板协调。
Android中的中介者模式
- Binder
我们知道系统启动时,各种系统服务会向ServiceManager提交注册,即ServiceManager持有各种系统服务的引用 ,当我们需要获取系统的Service时,比如ActivityManager、WindowManager等(它们都是Binder),首先是向ServiceManager查询指定标示符对应的Binder,再由ServiceManager返回Binder的引用。并且客户端和服务端之间的通信是通过Binder驱动来实现,这里的ServiceManager和Binder驱动就是中介者。
19、组合模式
将对象组成成树形结构,以表示“部分-整体”的层次结构,使得用户对单个对象和组合对象的使用具有一致性。
组合模式其实就是继承体系。
Android中的组合模式
- ViewGroup
我们知道,Android中View的结构是树形结构,每个ViewGroup包含一系列的View,而ViewGroup本身又是View。这是Android中非常典型的组合模式。
20、享元模式
使用享元对象有效地支持大量的细粒度对象。
享元模式我们平时接触真的很多,比如Java中的常量池,线程池等。主要是为了重用对象。
Android中的享元模式
- Message
线程通信中的Message,每次我们获取Message时调用Message.obtain()其实就是从消息池中取出可重复使用的消息,避免产生大量的Message对象。
21、外观模式
要求一个子系统的外部与其内部的通信必须通过一个统一的对象进行。
怎么理解呢,举个例子,我们在启动计算机时,只需按一下开关键,无需关系里面的磁盘、内存、cpu、电源等等这些如何工作,我们只关心他们帮我启动好了就行。实际上,由于里面的线路太复杂,我们也没办法去具体了解内部电路如何工作。主机提供唯一一个接口“开关键”给用户就好。
Android中的外观模式
- Context
Android内部有很多复杂的功能比如startActivty、sendBroadcast、bindService等等,这些功能内部的实现非常复杂,如果你看了源码你就能感受得到,但是我们无需关心它内部实现了什么,我们只关心它帮我们启动Activity,帮我们发送了一条广播,绑定了Activity等等就够了。
22、桥接模式
将抽象部分与实现部分分离,使他们独立地进行变化。
其实就是,一个类存在两个维度的变化,且这两个维度都需要进行扩展。
Android中的桥接模式
- View
对于一个View来说,它有两个维度的变化,一个是它的描述比如Button、TextView等等他们是View的描述维度上的变化,另一个维度就是将View真正绘制到屏幕上,这跟Display、HardwareLayer和Canvas有关。这两个维度可以看成是桥接模式的应用。
23、MVC、MVP、MVVP模式
MVC
全称为Model-View-Controller,也就是模型-视图-控制器。
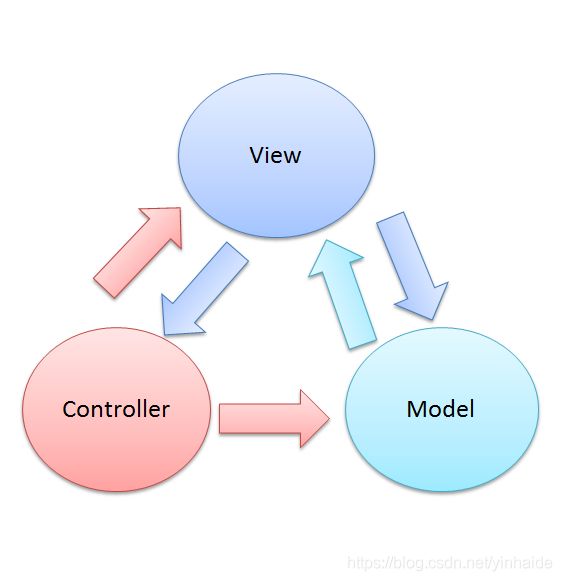
在Android中对MVC的应用很经典,我们的布局文件如main.xml就是对应View层,本地的数据库数据或者是网络下载的数据就是对应Model层,而Activity对应Controller层。
MVP
MVP全称为Model View Presenter,目前MVP在Android应用开发中越来越重要了。
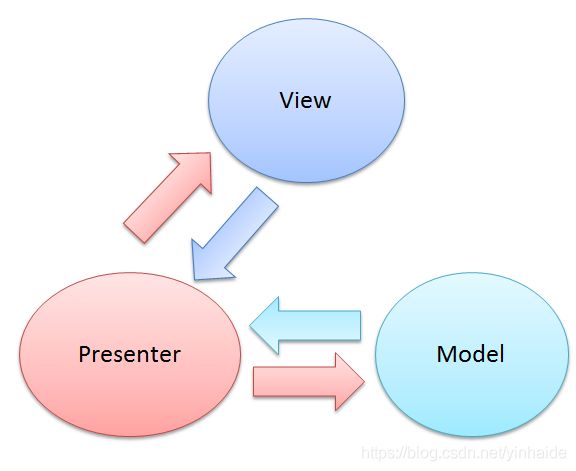
它降低了View与Model之间的耦合。彻底将View与Model分离。MVP不是一种标准化的模式,它由很多种实现。
MVVM
全称是Mode View ViewModel。
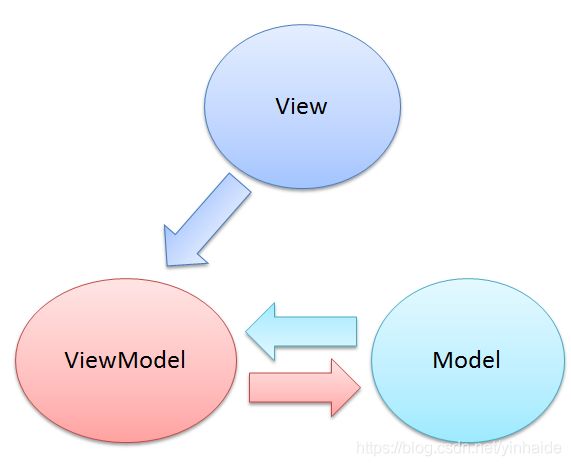
我们在使用ListView时,会自定义一个ViewHolder,在RecyclerView中是必须使用ViewHolder,这主要是提高性能,因为不需要每次去调用findViewById来获取View。其实ViewHolder就是个ViewModel。