飞桨Tracking目标跟踪库开源!涵盖业界主流的VOT算法,精准检测动态目标轨迹...
点击左上方蓝字关注我们

如何精准理解运动目标的行为呢?一起看看下面的视频,感受VOT技术的神奇吧!
从短视频中可以发现,视频中的目标是运动的,且不断变化。对于物体遮挡、形变、背景杂斑、尺度变换、快速运动等场景,如何又快又准确的预测结果?

实验论证,通过VOT(Visual Object Tracking, VOT)技术可以精准实现对视频中绿框标示的物体的运动轨迹跟踪。VOT通过跟踪图像序列中的特定运动目标,获得目标的运动参数,如:位置、速度、加速度和运动轨迹等,并进行后续处理与分析,实现对运动目标的行为理解。作为计算机视觉的重要分支之一,VOT技术在视频监控、互动娱乐、机器人视觉导航和医疗诊断等领域发挥着重要的作用,并具有广泛的发展前景。
飞桨PaddleCV新增“Tracking视频单目标跟踪模型库”,基于飞桨核心框架开发,涵盖四个业界领先的VOT算法:SiamFC、SiamRPN、SiamMask和ATOM。基于Tracking视频单目标跟踪模型库,开发者只需修改相关参数,便可以便捷、高效地在工业实践中应用VOT技术。
Tracking模型库路径:
https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/tracking
VOT相关算法通常分为生成式(generative model)和判别式(discriminative model)。
生成式:采用特征模型描述目标的外观特征,再最小化跟踪目标与候选目标之间的重构误差来确认目标。此方法着重于目标本身的特征提取,忽略目标的背景信息,因而在目标外观发生剧烈变化或者遮挡时,容易出现目标漂移或目标丢失。
判别式:将目标跟踪看做一个二元分类问题,通过训练关于目标和背景的分类器来从候选场景中确定目标,可以显著区分背景和目标,性能鲁棒,渐渐成为目标跟踪领域主流方法,目前大多数基于深度学习的目标跟踪算法都属于判别式方法。飞桨Tracking中的模型应用的都是此方法。
算法介绍
下面,我们一同解读一下Tracking模型库中四个模型(SiamFC、SiamRPN、SiamMask和ATOM)的实现原理。

1. SiamFC
SiamFC论文地址:
https://arxiv.org/pdf/1811.07628.pdf

图 SiamFC网络结构
SiamFC网络主体基于AlexNet,分为上、下两个权重共享的子网络,输入分别为模板图像(跟踪目标)和检测图像(搜索范围)。
-
模板图像:指目标区域的扩展纹理,通过padding补充模板周围背景的上下文信息。模板图像首先被resize到127×127×3,之后通过上分支子网络得到6×6×128的feature map。
-
检测图像:指模板图像4倍大小的检测区域。检测图像首先被resize到255×255×3,之后通过下分支子网络得到22×22×128的feature map。
使用交叉相关(cross-correlation)作为相似度的度量,计算两个feature map各个位置(区域)上的相似度,得到一个17×17×1的score map。该score map计算方式类似卷积,即:
-
将模板图像feature map作为卷积核,在检测图像feature map上进行滑窗,得到score map;
-
然后采用双线性插值对score map进行上采样得到分辨率放大16倍的score map,以获得更好的定位精度;
-
根据上采样后的score map,即可定位到跟踪目标在新一帧(检测图像)中的位置。
SiamFC预测时,不在线更新模板图像。这使得其计算速度很快,但同时也要求SiamFC中使用的特征具有足够鲁棒性,以便在后续帧中能够应对各种变化。另一方面,不在线更新模板图像的策略,可以确保跟踪漂移,在long-term跟踪算法上具有天然的优势。
基于Tracking复现的SiamFC模型精度:
使用VOT2018数据集,SiamFC指标与paper公开指标对比如下:

2. SiamRPN
SiamRPN论文地址:
http://openaccess.thecvf.com/content_cvpr_2018/papers/Li_High_Performance_Visual_CVPR_2018_paper.pdf
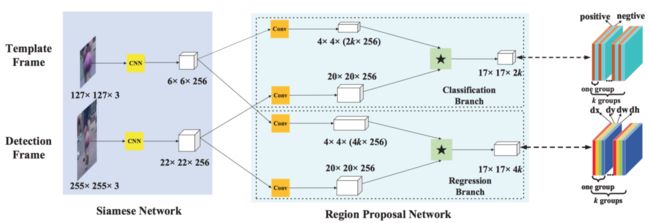
图 SiamRPN网络结构
SiamFC利用图像金字塔得到不同尺度的模板图像进行多尺度测试,从而得到跟踪目标的位置和尺度,但无法获得目标的长宽比,使得跟踪框无法紧密的贴合目标。相比SiamFC,SiamRPN在网络结构中引入Region Proposal Network(RPN)。将模板图像和检测图像的feature map复制双份,一份送入RPN的分类分支,另一份送入RPN的回归分支。通过RPN 中的anchor机制覆盖各种尺寸,使得Siamese网络拥有了多尺度检测的能力,并且可以更准确地回归出目标的位置、大小以及长宽比。
-
在RPN分类分支中,模板图像和检测图像的feature map都先经过一个卷积层,该卷积层主要对模板图像的feature map进行channel升维,使其变为检测图像feature map通道数的2k倍(k为RPN中设定的anchor数)。此后,将模板图像的feature map在channel上按序等分为2k份,作为2k个卷积核,在检测图像的feature map完成卷积操作,得到一个维度为2k的score map。该score map同样在channel上按序等分为k份,得到对应k个anchor的k个维度为2的score map,2个维度分别对应anchor中前景(目标)和后景(背景)的分类分数。
-
在RPN回归分支中,模板图像和检测图像的feature map,都先经过一个卷积层,该卷积层主要对模板图像的feature map进行channel升维,令其维度变为检测图像的feature map通道数的4k倍(k为RPN中设定的anchor数)。此后,将模板图像的feature map在channel上按序等分为4k份,作为4k个卷积核,在检测图像的feature map完成卷积操作,得到一个维度为4k的score map。该score map同样在channel上按序等分为k份,得到对应k个anchor的k个维度为4的score map,4个维度分别对应anchor左上角的横纵坐标值,以及长宽(x,y,w,h)。
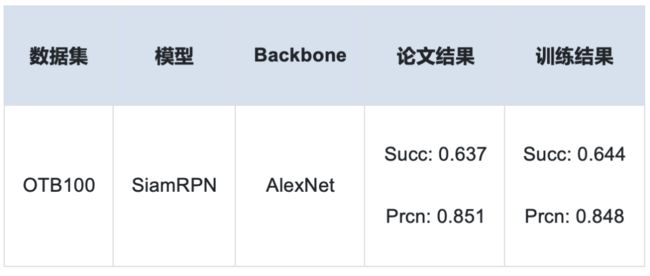
基于Tracking复现的SiamRPN模型精度
使用OTB100数据集,SiamRPN指标与paper公开指标对比如下:
3. SiamMask
SiamMask论文地址:
https://arxiv.org/pdf/1812.05050.pdf
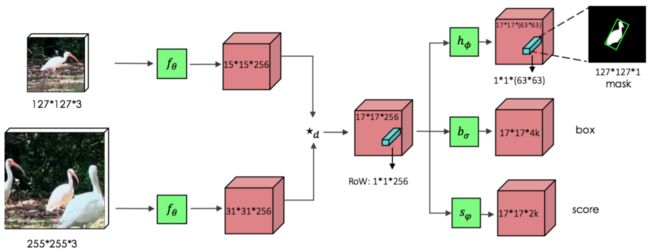
图 SiamMask网络结构
SiamRPN预测出的包围框结果更加精确,主要体现在包围框的尺寸和长宽比上,但是这些包围框都是轴对齐的包围框,不能很好地适应目标的旋转和变化。SiamMask基于SiamRPN,在score分支和bbox分支基础上增加了mask分支,同时对目标进行位置、大小和分割的预测,利用图像分割获得mask,得到带有方向的包围框,能更好地贴合目标的旋转和变化,以达到更高的IoU。SiamMask还应用了Depthwise Cross-correlation的方式,解决SiamRPN非对称的问题,并使用ResNet作为网络主体加深网络深度,以获得更多层次的特征。
除此之外,为了提高模型输出的mask的分辨率,SiamMask还应用了如下图所示的Refine模块,通过级联Refine的形式逐级将低语义信息高分辨率的feature map和上采样后的mask进行融合,最终得到同时拥有高语义信息和高分辨率的mask。

图 SiamMask Refine模块网络结构
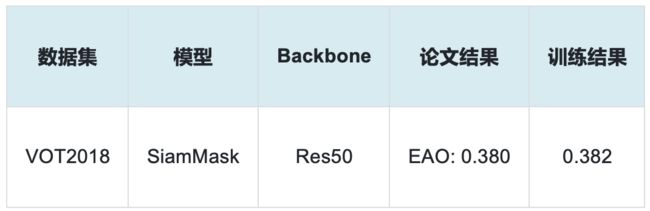
基于Tracking复现的SiamMask模型精度
使用VOT208数据集,SiamMask指标与paper公开指标对比如下:
4. ATOM(Accurate Tracking by Overlap Maximization)
受2018年ECCV的IoUNet 启发,提出一种IoU最大化的训练思路。
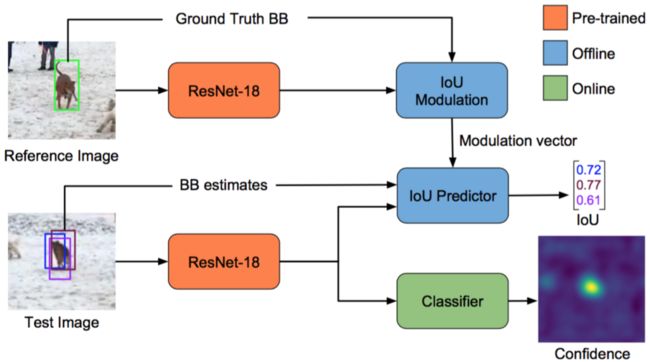
图 ATOM网络结构
ATOM论文地址:
https://arxiv.org/pdf/1811.07628.pdf
ATOM网络结构主要包含两个模块:目标估计模块(蓝色区域)和目标分类模块(绿色区域)。
-
目标估计模块:用于计算测试图片和参考图片的物体IoU,论文对该模块进行离线训练;
-
目标分类模块:仅由两层卷基层构成,回归出测试图片中各个位置出现目标物体的概率。
实际测试过程中,首先将上一帧物体坐标和尺寸作为Reference,利用目标分类模块计算当前帧的confidence map,将最高得分的位置作为目标在当前帧中的位置。这个坐标位置和前一帧中计算的目标size一起,就构成了初始的目标框。接下来基于该目标框,论文生成10个推荐区域,并利用目标估计模块计算它们与Reference的IoU数值,取前三个最大值对应的目标框,然后将它们的平均值作为最终的目标框,实现物体的在线跟踪。
基于Tracking复现的ATOM模型精度
使用VOT208数据集,ATOM指标与paper公开指标对比如下:

实验证明,使用飞桨Tracking复现的SiamFC、SiamRPN、SiamMask和ATOM模型精度均与原论文持平。更重要的是,Tracking开源了四种模型的网络结构源代码,开发者只需要在此基础上进行参数调整,就可以快速实现VOT技术。

手把手实践
1. 环境准备
工作环境为Linux,python3以及飞桨1.8.0及以上版本。
2. 数据集下载
目标跟踪的训练集和测试集是不同的,模型训练时往往使用多个训练集。目前主流的训练数据集有:VID、DET、COCO、Youtube-VOS、LaSOT、GOT-10K;主流的测试数据集有:OTB、VOT。
3. 下载目标跟踪库
git clone https://github.com/PaddlePaddle/models.git
git checkout develop
cd models/PaddleCV/tracking/
4. 安装第三方库,推荐使用Anaconda。
pip install -r requirements.txt
(可选)如下两个插件可提升文件读取效率,建议开发者安装。
# (可选) 1. 推荐安装:快速读取 jpeg 文件
apt-get install libturbojpeg
# (可选) 2. 推荐安装:进程控制
apt-get install build-essential libcap-dev
pip install python-prctl
5. 下载Backbone预训练模型。
准备SiamFC 、SiamRPN、SiamMask、ATOM模型的Backbone预训练模型。飞桨提供 ATOM ResNet18 和 ResNet50 的 backbone模型。单击如下链接可以下载所有预训练模型的压缩包,压缩包解压后的文件夹为 pretrained_models。
预训练模型下载链接:
https://paddlemodels.bj.bcebos.com/paddle_track/vot/pretrained_models.tar
6. 设置训练参数
所有训练工作都将利用ltr代码完成,需要进入models/PaddleCV/tracking/ltr路径。
在启动训练前,需要设置使用的数据集路径,以及训练模型保存的路径,这些参数在
ltr/admin/local.py中设置。
# 使用编辑器编辑文件 ltr/admin/local.py
# workspace_dir = './checkpoints' # 要保存训练模型的位置
# backbone_dir = Your BACKBONE_PATH # 训练SiamFC时不需要设置
# 并依次设定需要使用的训练数据集如 VID, LaSOT, COCO 等,比如:
# imagenet_dir = '/Datasets/ILSVRC2015/' # 设置训练集VID的路径
# 如果 ltr/admin/local.py 不存在,请使用代码生成
python -c "from ltr.admin.environment import create_default_local_file; create_default_local_file()"
7. 启动训练
通过组合不同的数据处理模块、样本采样模块、模型结构、目标函数以及训练设定,可以轻松实现各种VOT算法。
以ATOM为例,在“
ltr/train_settings/bbreg/atom_res50_vid_lasot_coco.py”文件中定义训练集为ImagenetVID、LaSOT和MSCOCOSeq,验证集为Got10K。采用ATOMProcessing数据处理器对样本进行处理,ATOMSampler采样器对训练样本进行采样,并通过AtomActor执行器对模型和目标函数进行封装。通过如下命令启动训练。
# 训练 ATOM ResNet50
python run_training.py bbreg atom_res50_vid_lasot_coco
飞桨还提供了其他模型的训练配置文件,可以按照如下方式启动训练。
# 训练 ATOM ResNet18
python run_training.py bbreg atom_res18_vid_lasot_coco
# 训练 SiamFC
python run_training.py siamfc siamfc_alexnet_vid
# 训练 SiamRPN AlexNet
python run_training.py siamrpn siamrpn_alexnet
# 训练 SiamMask-Base ResNet50
python run_training.py siammask siammask_res50_base
# 训练 SiamMask-Refine ResNet50,需要配置settings.base_model为最优的SiamMask-Base模型
python run_training.py siammask siammask_res50_sharp
8. 模型评估
模型训练完成后,进入pytracking路径,并在“pytracking/admin/local.py”文件中设置模型评估环境、测试数据和模型。
# 在VOT2018上评测ATOM模型
# -d VOT2018 表示使用VOT2018数据集进行评测
# -tr bbreg.atom_res18_vid_lasot_coco 表示要评测的模型,和训练保持一致
# -te atom.default_vot 表示加载定义超参数的文件pytracking/parameter/atom/default_vot.py
# -e 40 表示使用第40个epoch的模型进行评测,也可以设置为'range(1, 50, 1)' 表示测试从第1个epoch到第50个epoch模型
# -n 15 表示测试15次取平均结果,默认值是1
python eval_benchmark.py -d VOT2018 -tr bbreg.atom_res18_vid_lasot_coco -te atom.default_vot -e 40 -n 15
9. 结果可视化
数据集上评测完后,可以通过可视化跟踪器的结果定位问题,飞桨提供下面的方法来可视化跟踪结果。
# 开启 jupyter notebook,请留意终端是否输出 token
jupyter notebook --ip 0.0.0.0 --port 8888
在浏览器中输入“服务器IP地址+端口号”,在“
visualize_results_on_benchmark.ipynb” 文件查看可视化结果。
本文介绍了VOT几种主流算法的原理,以及应用Tracking视频单目标跟踪模型库进行VOT实践的操作方法,欢迎开发者们使用,并贡献您的奇思妙想。
如果您觉得效果还不错,欢迎“Star”;如果您有意见需要交流,欢迎“Issue”,Tracking视频单目标跟踪模型库开源代码和参考文档Github地址:
https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/tracking
如在使用过程中有问题,可加入飞桨官方QQ群进行交流:1108045677。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
飞桨官网地址:
https://www.paddlepaddle.org.cn/
飞桨开源框架项目地址:
GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle




END
今晚精彩直播
