在centos6.6上安装hadoop完全分布式集群并运行第一个程序
在centos6.6上安装hadoop完全分布式集群并运行第一个程序
1.依赖的环境:
虚拟机:vmware11
计算机硬件:内存4G以上;磁盘20G以上;
操作系统:centos6.6
2.需要的版本:
虚拟机:
官方下载地址:
https://my.vmware.com/cn/web/vmware/details?downloadGroup=WKST-1110-WIN&productId=462&rPId=7464
Hadoop2.3.0;
官方下载地址:
http://www.apache.org/dyn/closer.cgi/hadoop/common/(下载稳定的版本)
CentOS-6.6-i386-bin-DVD1.iso
官方下载地址:
http://mirrors.aliyun.com/centos/6.6/isos/i386/CentOS-6.6-i386-bin-DVD1.iso
jdk-8u40-linux-i586.tar.gz
官方下载地址:http://www.oracle.com/technetwork/cn/java/javase/downloads/jdk7-downloads-1880260-zhs.html
eclipse-jee-luna-SR2-linux-gtk.tar.gz
官方下载地址:
https://eclipse.org/downloads/?osType=linux
hadoop-eclipse-plugin-2.6.0
官方下载地址:
https://codeload.github.com/winghc/hadoop2x-eclipse-plugin/zip/master
3.配置过程
安装centos6.6,将四台用户名统一设为hadoop;分为master、slave1、slave2、slave3;
修改hostname : vim /etc/sysconfig/network
修改hosts文件 : vim /etc/hosts
关闭防火墙,selinux设为disabled;
在root权限下关闭防火墙:/sbin/service iptables stop
禁用selinux
编辑 “/etc/selinux/config”文件,设置”SELINUX=disabled”
设置hadoop权限 :先root 再chmod 777 /etc/sudoers 然后再gedit /etc/sudoers修改hadoop权限
设置公钥,使用命令: ssh-keygen -t rsa 一路按回车即可
主要是设置ssh的密钥和密钥的存放路径。 路径为~/.ssh下。
打开~/.ssh 下面有三个文件
authorized_keys,已认证的keys(有可能没有)
id_rsa,私钥
id_rsa.pub,公钥 三个文件。
下面就是关键的地方了,(我们要做ssh认证。进行下面操作前,可以先搜关于认证和加密区别以及各自的过程。)
在master上将公钥放到authorized_keys里。
复制的方式:sudo cp ~/.ssh/ id_rsa.pub ~/.ssh/ authorized_key
或者如果没有authorized_keys使用touch命令新建,然后追加的方式命令:sudo cat id_rsa.pub >> authorized_keys
将master上的authorized_keys放到其他linux的~/.ssh目录下。
命令:sudo scp ~/.ssh/authorized_keys hadoop@slave1:~/.ssh
sudo scp authorized_keys 远程主机用户名@远程主机名或ip:存放路径。
修改authorized_keys权限,命令:chmod 644 authorized_keys (大部分使用chmod 700 .ssh 接着使用 chmod 600authorized_keys)
测试是否成功
ssh slave1输入用户名密码,然后退出,再次ssh slave2不用密码,直接进入系统。这就表示成功了。
jdk安装:将java的jdk放在usr/lib下的java目录中,
如果此目录中没有java目录的话就建一个,(先使用root权限,然后进入到usr/lib目录下,然后再新建)
操作命令如下:
hadoop@slave3:~$ su
root@slave3:/# cd /usr/lib
root@slave3:/usr/lib# mkdir java
将文件放到Downloads下,放之前,为了方便,我们将压缩包名改成了jdk.gz;然后通过命令将其放到/usr/lib/java中,四个ubuntu都要操作。
命令:
hadoop@slave2:~$ su
root@slave2:/home/hadoop# cd Downloads
root@slave2:/home/hadoop/Downloads# cp -r jdk.gz /usr/lib/java
然后解压缩 命令:tar -zxvf jdk.gz (此命令执行后,是解压到了Java底下的jdk1.7.0_75目录下)
然后设置环境变量
在hadoop权限下设置 命令:sudo vim ~/.bashrc
在最下面添加:

修改完后,用命令:source ~/.bashrc让配置文件生效。
4.上传hadoop,配置hadoop
通过winSCP,上传压缩包到Downloads下,先进入root模式,命令:su
然后将文件从Downloads下拷贝到/usr/local下,
命令为: cp –r hadoop-2.3.0.tar.gz /usr/local
然后进入到目录里面:命令:cd /usr/local
解压缩,命令:tar -zxvf hadoop-2.3.0.tar.gz (我们下载的hadoop压缩包名为hadoop-2.3.0.tar.gz)
再将解压后的目录名重命名一下,命令:sudo mv hadoop-2.3.0 hadoop
这样目录就变成/usr/local/hadoop
① 修改环境变量,将hadoop加进去(最后四个ubuntu都操作一次)
命令:sudo vim ~/.bashrc
在底下加上:
![]()
修改完后,用命令:source ~/.bashrc让配置文件生效。
② 修改/usr/local/hadoop/etc/hadoop下的配置文件(需要在root权限下操作)
配置文件主要为:hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-env.sh slaves yarn-site.xml
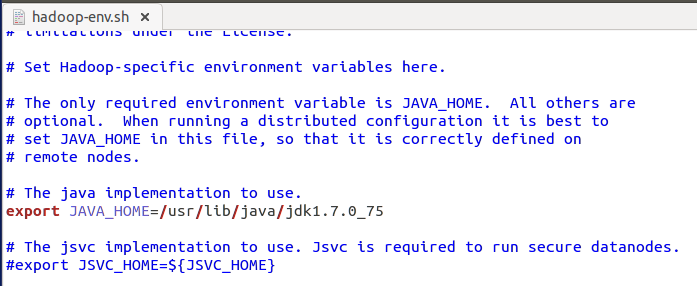
a.修改hadoop-env.sh配置:
我们打开使用的命令是:sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
增加java环境变量 export JAVA_HOME=”/usr/lib/java /jdk1.7.0_75 如下图所示:
b.修改yarn-env.sh配置:
修改JAVA_HOME值为 export JAVA_HOME=”/usr/lib/java /jdk1.7.0_75,打开命令同上,如下图所示:

c.修改slaves配置,写入所有从节点主机名:
此处有两种方案:
(1)第一种(每行一个)
去掉”localhost”,每行添加一个主机名,把剩余的Slave主机名都填上。
我们采用的是这种,如图所示:

(2)第二种
去掉”localhost”,加入集群中所有Slave机器的IP,也是每行一个。
d.修改core-site.xml配置文件:
修改Hadoop核心配置文件core-site.xml,这里配置的是HDFS master(即namenode)的地址和端口号。输入以下代码:
```
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://192.168.7.141 :9000value>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/local/ hadoop/tmpvalue >
<description>A base for other temporary directories.description>
property>
<property>
<name>hadoop.proxyuser.hduser.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.hduser.groupsname>
<value>*value>
property>
configuration>如下图所示:

e.修改hdfs-site.xml配置:
因有几个目录不存在,所以我们首先创建相关目录
命令:
mkdir /usr/local/hadoop/name
chown -R hadoop.hadoop /usr/local/hadoop/name
mkdir -p /usr/local /hadoop/data
chown -R hadoop.hadoop /usr/local /hadoop/data
打开hdfs-site.xml后输入以下代码:
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>master:9001value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/usr/local/hadoop/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/usr/local/hadoop/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>4value>
<description>storage copy numberdescription>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
configuration>如下图所示:

f.修改mapred-site.xml配置
这个文件不存在,需要自己拷贝对应的template文件。
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>master:19888value>
property>
<property>
<name>mapred.job.trackername>
<value>master:9001value>
<description>JobTracker visit pathdescription>
property>
configuration>如下图所示:

g.修改yarn-site.xml配置:
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>master:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>master:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>master:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>master:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>master:8088value>
property>
configuration>如下图所示:

③最后要记得,将hadoop的用户加进去,命令为
sudo chown -R hadoop:hadoop hadoop
sudo chown -R 用户名@用户组 目录名
④让hadoop配置生效(若使用vim才进行这个命令)
source hadoop-env.sh
⑤在master主库上格式化namenode,只格式一次
su - hadoop
hadoop namenode -format
⑥启动hadoop
切到/usr/local/hadoop/bin目录下,执行 start-all.sh启动所有程序
⑦查看进程,是否启动
jps

注:hadoop2.3.0环境下面会出现“Name or service not known”的错误,需要在配置中添加如下设置:
Hadoop用户下 :sudo gedit ~/.bashrc
#hadoop variable settings
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib" 如下图所示:

所有节点采用相同的配置文件和安装目录,直接整个目录copy过去安装把master上面的所有hadoop目录copy到slave1,slave2,slave3上面去,命令与拷贝authorized_key命令相似。
上面的hadoop-env.sh,core-site.xml,mapred-site.xml,hdfs-site.xml,master,slave几个文件包含在hadoop目录中,将hadoop包拷贝到其他电脑上后,在四台ubunt中都是一样的。
成功界面:


5.在centos上安装eclipse及插件
下载Eclipse:从上面提到的网站进行下载。
解压elipse:
在/home/hadoop/hadoop/目录中,解压elipse到目录下:
tar -zxvf eclipse-jee-luna-SR1-linux-gtk-x86_64.tar.gz
启动eclipse:
登录到虚拟机桌面,启动eclipse;
我们此处出现问题:显示Java RunTime Environment (JRE) or Java Development Kit (JDK) must be available in order to run Eclipse. No java virtual machine was found after searching the following locations:…
解决办法:在终端进入你的eclipse目录,然后输入:
mkdir jre
cd jre
ln -s 你的JDK目录/bin
完成后打开eclipse
加载eclipse插件:
下载hadoop-eclipse-plugin-2.6.0.jar,从文章开始的地址下载
将hadoop-eclipse-plugin-2.6.0.jar拷贝到 eclipse的plugins目录:
启动eclipse,打开窗口 window–>preferences ,配置Hadoop MapReduce的安装路径,如下图所示:

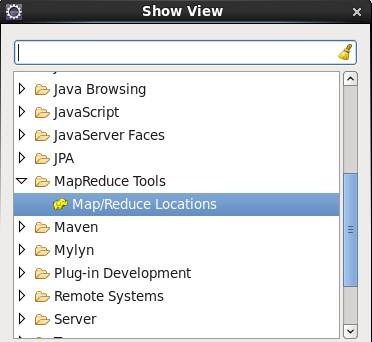
打开MapReduce视图
点击eclipse菜单Window–>Show View–>Other 窗口,选择 MapReducer Locations,如下图所示:
添加完毕后在视图区域中出现MapReduce视图,同时在视图区域右上方出现蓝色小象的添加按钮,如下图所示

启动hadoop
start-all.sh
新建Hadoop Location
点击蓝色小象新增按钮,提示输入MapReduce和HDFS Master相关信息,其中:
Lacation Name:为该位置命名;
MapReduce Master:与$HADOOP_DIRCONF/mapred-site.xml配置保持一致;
HDFS Master:与$HADOOP_DIRCONF/core-site.xml配置保持一致
User Name:登录hadoop用户名,可以随意填写
使用elipse上传测试数据
配置完毕后,在eclipse的左侧DFS Locations出现CentOS HDFS的目录树,该目录为HDFS文件系统中的目录信息:

为运行MapReduce,通过eclipse上传测试数据,可以在DFS Locations相对应目录点击右键,选择Upload file to DFS出现选择文件界面,如下图所示:

或者是用命令传到hdfs上,hadoop fs -put /home/hadoop/hadoop/Company.txt /input01
可以看到Company.txt已经成功上传到HDFS文件系统中
在此处出现问题,出现上传文件成功但文件显示无内容;
解决办法: 检查防火墙和selinux是否禁用
在root权限下关闭防火墙:
/sbin/service iptables stop
禁用selinux
编辑 “/etc/selinux/config”文件,设置”SELINUX=disabled”
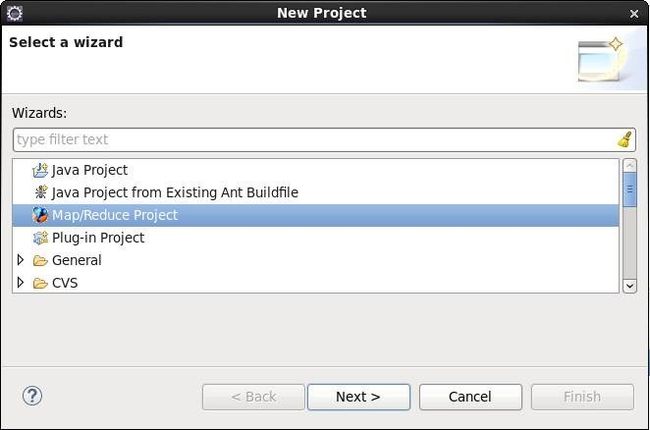
创建MapReduce项目
安装插件之后,可以在New Project页面建立Map/Reduce Project:
需要注意的是填写完项目名称后,需要指定Hadoop MapReduce运行包的路径,填写完毕后点击完成即可
编写代码
创建WordCount,将源码中的WordCount.java代码复制到新建的类中,新建时应该为package写上如图所示,

设置运行参数
打开WordCount.java,点击Run-Run Configurations设置运行参数,需要在Arguments页签填写MaxTemperature运行的输入路径和输出路径参数,需要注意的是输入、输出路径参数路径需要全路径,否则运行会报错;
输入输出的路径如图所示:

运行并查看结果
设置运行参数完毕后,点击运行按钮:
运行成功后,刷新CentOS HDFS中的输出路径,打开part-r-00000文件,可以看到运行结果:

后期问题记录:
1. 一个节点无法接受block数据
节点被拉黑,到hdfs-default.xml中修改
<property>
<name>dfs.hosts.excludename>
Names a file that contains a list of hosts that are
not permitted to connect to the namenode. The full pathname of the
file must be specified. If the value is empty, no hosts are
excluded.
property>