WordCount案例及MapReduce运行的三种方式
目录
一、MapReduce案例准备
二、运行方式一:本地执行
三、运行方式二:打jar包,集群执行
四、运行方式三:以idea为入口,集群执行
一、MapReduce案例准备
在Idea中创建一个MapReduce工程,对指定目录下文件的单词个数进行统计。MapReduce框架在使用时,需要编写三个类:CountDriver,CountMapper,CountReducer。其中CountDriver为最终的执行类;CountMapper继承Mapper类,重写map方法,实现Map阶段的计算逻辑;CountReducer类继承Reducer类,重写reduce方法,实现reduce阶段的计算逻辑。
使用maven工具,创建新的maven工程,在其main目录下创建以上3个类。实现代码如下
1、CountMapper类
package com.blog.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class CountMapper extends Mapper {
private Text outKey = new Text();
private IntWritable outValue = new IntWritable(1);
/**
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//将文档的一行数据转化成java的String类,
String line = value.toString();
//以空格分隔字符串
String[] words = line.split(" ");
//遍历字符串数组,获得单词
for (String word : words) {
//java字符转化为Text类型
outKey.set(word);
//以写出
context.write(outKey,outValue);
}
}
}
2、CountReducer类
package com.blog.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class CountReducer extends Reducer {
private IntWritable outValue = new IntWritable();
/**
* @param key
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
//遍历封装的value
for (IntWritable value : values) {
//intwritable类转化成integer,并累加,获得key出现的次数。
sum += value.get();
}
//integer型转化为intwritable
outValue.set(sum);
//以写出
context.write(key,outValue);
}
} 3、CountDriver类
package com.blog.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class CountDriver {
public static void main(String[] args) {
try {
//1 创建job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2 关联jar
job.setJarByClass(CountDriver.class);
//3 关联mapper 和 reducer
job.setMapperClass(CountMapper.class);
job.setReducerClass(CountReducer.class);
//4 定义mapper的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5 定义reducer的输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6 定义输入输出路径
FileInputFormat.addInputPath(job,new Path("D:/hadoopTest/input"));
FileOutputFormat.setOutputPath(job,new Path("D:/hadoopTest/output"));
//7 提交任务
job.waitForCompletion(true);
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
二、运行方式一:本地执行
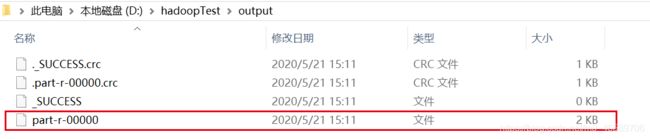
完成MapReducer工程后,即可在idea上运行。查看输出路径的output目录。
三、运行方式二:打jar包,集群执行
1、将编写的MapReduce工程打成jar包,将jar包上传服务器,在集群运行。打包之前需进行以下调整:
//6 定义输入输出路径,将输入输出路径更改为命令行输入参数
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));2、使用maven工具,将mapred工程打jar包,传入服务器,并在服务器上执行。执行命令如下:
[lp@hadoop102 myjar]$ ll
总用量 16
-rw-r--r--. 1 lp lp 15568 5月 21 13:25 mapreduce-1.0-SNAPSHOT.jar
[lp@hadoop102 myjar]$ hadoop jar mapreduce-1.0-SNAPSHOT.jar com.blog.wordcount.CountDriver /test/ /output
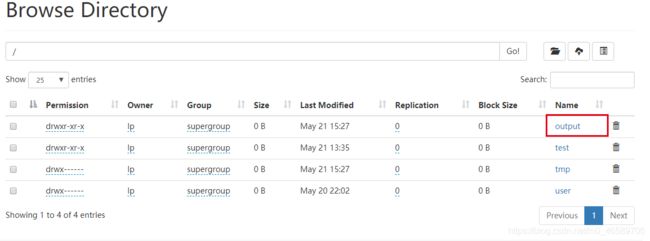
3、运行完成后,可在web端查看结果。
四、运行方式三:以idea为入口,集群执行
将MapReduce工程以idea为入口,在集群上运行,那么需要进行以下调整。
1、增加配置信息,以下四个是必须的。
//1 创建job对象
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop102:9820");
// 指定MapReduce运行在Yarn上
conf.set("mapreduce.framework.name","yarn");
// 指定mapreduce可以在远程集群运行
conf.set("mapreduce.app-submission.cross-platform","true");
//指定Yarn resourcemanager的位置
conf.set("yarn.resourcemanager.hostname","hadoop103");
Job job = Job.getInstance(conf);2、由于集群只能运行jar包,所以需将完成上述配置的工程打jar包,并将jar包关联到job中。
//2 关联jar包,添加jar的路径
job.setJar("D:\\hadoopTest\\mapreduce\\target\\mapreduce-1.0-SNAPSHOT.jar");3、修改idea端配置

进入配置界面后,需完成以下配置

完成以上配置,就可以直接在idea内运行,查看web端的文件输出如下:

五、总结
以上就是MapReduce工程的三种运行方式,本地运行仅供学习使用。另外的两种集群运行方式,可以根据具体情况具体选择。
