如何让你的Oracle SQL/SP运行在Hive上?hplsql执行Oracle存储过程
关于hplsql的配置安装请见:https://blog.csdn.net/qq_34901049/article/details/107582460
基本环境:
已有基础集群环境(三个节点):
CentOS 6.8
Java8
hadoop2.7.2
hive 1.2.1
使用hplsql版本:
hplsql-0.3.31
前面提到hplsql看起来有助于企业从传统RDB业务架构升级到完全分布式中的Oracle SP转换执行。即实现Oracle SP on Hive的效果。
hplsql作为Apache Hive下的一个子模块,借助Antlr解析Oracle SP后运行在hive上;其若能提供完好的功能支持,将带来巨大的价值。而在官网( http://hplsql.org/home)可以看到最新版本发布于2017年九月;对应github( https://github.com/apache/hive/tree/master/hplsql)上发现该子项目最后针对源码的更新是在半年前,并且最近两年并不活跃(此文章撰写于2020年7月25日)。据说bug很多。。。
故而,以下针对具体操作场景拆分测试该工具的可行性。主要包括行级数据更新(insert、update、delete),以及流程控制语句、异常处理。最后试了试游标,发现不支持
来看看基本数据操作测试:增删改查。
注意确保对应服务已开启,如hdfs、yarn、hiveserver2

1 先来试试官网给出的例子( http://hplsql.org/include)
setMessage.sql
CREATE PROCEDURE set_message(IN name STRING, OUT result STRING)
BEGIN
SET result = 'Hello, ' || name || '!';
END;
inct.sql
INCLUDE setMessage.sql
DECLARE str STRING;
CALL set_message('this is SH', str);
PRINT str;
pass

2 试试最简单的查询
create or replace procedure proc_ht
as
begin
select * from action;
end proc_ht;
call proc_ht;
pass
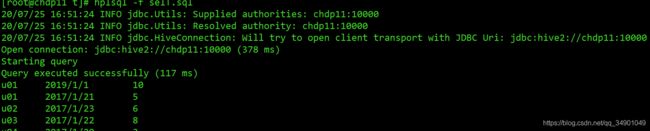
3 试试数据更新
注意在做数据更新前需要做额外配置,其中包含基本配置以及建表DDL的相应变化,详见:如何配置hive支持行级数据更新操作?
create or replace procedure proc_updateT(id in accountInfo.id%type)
as
begin
update accountInfo
set age = age + 10
where accountInfo.id = id;
end proc_updateT;
call proc_updateT(1);
select *from accountInfo;
pass

4 试试数据删除
不知道为什么这里采用传参的方式发现对应要删除的数据未被match上,干脆写成字面量3(where accountInfo.id = 3;)却可以。
select *from accountInfo;
create or replace procedure proc_delt(uid in accountInfo.id%type)
as
begin
delete from accountInfo
#where accountInfo.id = uid;
where accountInfo.id = 3;
end proc_delt;
call proc_delt(3);
commit;
select *from accountInfo;
pass

5 数据插入测试
select *from accountInfo;
create or replace procedure proc_inst
as
begin
insert into accountInfo values(4,'bt',18);
exception
when others then
DBMS_OUTPUT.PUT_LINE('msg: '|| sqlerrm);
end proc_inst;
call proc_inst;
select *from accountInfo;
pass
6 if、while语句判断测试(经测不支持i++、i:=i+1操作)
create or replace procedure loopifT(num in int)
as
i number;
begin
DBMS_OUTPUT.PUT_LINE('num: '||num);
if num>0 then
i=1;
while i<=num loop
DBMS_OUTPUT.PUT_LINE('i: '||i);
i=i+1;
end loop;
end if;
end loopifT;
call loopifT(5);
pass

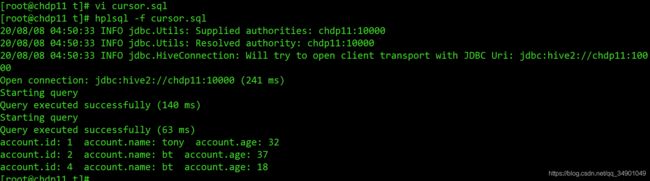
7 游标cursor
此处不支持cursor,但支持sys_refcursor.
create or replace procedure getCurResult(acc_cur out sys_refcursor)
as
begin
open acc_cur for select * from accountInfo;
end getCurResult;
create or replace procedure proc_cursor
as
account_cur sys_refcursor;
account_rec accountInfo%ROWTYPE;
begin
call getCurResult(account_cur);
while true loop
fetch account_cur into account_rec;
exit when account_cur%notfound;
DBMS_OUTPUT.PUT_LINE('account.id: '|| account_rec.id || ' account.name: '|| account_rec.name || ' account.age: '|| account_rec.age);
end loop;
exception
when others then
DBMS_OUTPUT.PUT_LINE('msg: '|| sqlerrm);
if account_cur%ISOPEN then
close account_cur;
end if;
close account_cur;
end proc_cursor;
call proc_cursor;
8 查询变量赋值(into)及API示例
create or replace procedure proc_ht(str in varchar2)
as
uid int;
begin
select id into uid from accountInfo;
DBMS_OUTPUT.PUT_LINE('uid: '|| uid);
DBMS_OUTPUT.PUT_LINE('substr: '|| substr(str,3,5));
DBMS_OUTPUT.PUT_LINE('substr: '|| substr(str,instr(str,'h'),2));
DBMS_OUTPUT.PUT_LINE('upper: '|| upper(str))
DBMS_OUTPUT.PUT_LINE('trim: '|| trim(' td d ')||'|')
end proc_ht;
call proc_ht('hello SH!');

总结:
基于上述测试,在hive已配置行级数据更新支持的前提下,运用hplsql运行Oracle SP且伴随简单数据操作如insert、update、delete是可行的。此外其支持基本流程控制语句、异常处理、sys_refcursor等(更多支持参考官网:http://hplsql.org/plsql)。总体来看,该工具对Oracle SP提供了大部分的兼容支持,以使得简单Oracle SP可直接运行在Hive上,而Hive亦可配置Hive on Spark以达到对应场景下更好的运算效率;如此处的Hive on Tez。
以上毕竟基于简单测试,实际可行性还得要回到复杂的生产环境下具体问题具体分析。