C/C++ 文件写入读取
C 文件基本操作
1. 文件基本写入
要想实现一个文件的基本写入需要用到下面三个函数(基本流程):
| 步骤 | 函数 | 说明 | 备注 |
|---|---|---|---|
| 第一步 | fopen() | 打开文件 | fopen(“文件路径+文件名”, “模式(wb/ab/rb)”) 返回FILE* fp指针 |
| 第二步 | fwrite() | 写入文件 | fwrite(“写入的内容”, 1, “内容的大小(字节)”, “FILE* 指针对象”); |
| 第三步 | fclose() | 关闭文件 | fclose(“FILE* 指针对象”); 对文件进行写入/读取之后都需要关闭文件 |
- fopen()函数中常用的三种模式: wb/ab/rb
- wb模式:写入文件,写入的时候每次都会清空文件原有的内容
- ab模式:写入文件,每次写入内容都是追加到原文件的内容之后(不会清空原文件内容)
- rb模式:读取文件
示列:
wb模式写入
#includeab模式只需要把wb替换成ab就可以了,其它代码一样
// 打开文件
FILE* fp = fopen(fileName, "ab");
以字符串的方式写入int类型数据
#include2. 文件读取
2.1 读取全部内容
#include2.2 顺序读取
#include3. 随机访问
| 随机访问:比如MP3、MP4等文件拖动快进时就是随机读取( fseek()函数)) | |
| 功能 | 示列 |
| 调到第100个字节位置 | fseek(fp, 100, SEEK_SET); |
| 调到倒数100个字节的位置 | fseek(fp, 100, SEEK_END); |
| 调到当前位置往前100个字节 | fseek(fp, -100, SEEK_CUR); |
| 调到当前位置的往后100个字节 | fseek(fp, 100, SEEK_CUR); |
#include4. 文本形式存储与读写
4.1 以文本形式存储(按行存储,就是在结尾加一个\n)
#include4.2 按行读取、解析数据
使用fgets()函数,内部会检查,如果都到\n时,停止读取。返回实际读取的字节
#include写入到文本的数据:
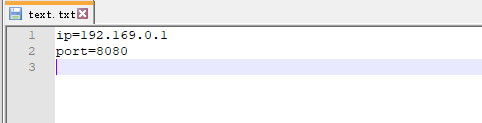
解析文本数据:
