Spark修炼之道(高级篇)——Spark源码阅读:第一节 Spark应用程序提交流程
作者:摇摆少年梦
微信号: zhouzhihubeyond
spark-submit 脚本应用程序提交流程
在运行Spar应用程序时,会将spark应用程序打包后使用spark-submit脚本提交到Spark中运行,执行提交命令如下:
root@sparkmaster:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/bin#
./spark-submit --master spark://sparkmaster:7077
--class SparkWordCount --executor-memory 1g
/root/IdeaProjects/SparkWordCount/out/artifacts/SparkWord
Count_jar/SparkWordCount.jar hdfs://ns1/README.md
hdfs://ns1/SparkWordCountResult为弄清楚整个流程,我们先来分析一下spark-submit脚本,spark-submit脚本内容如下:
#!/usr/bin/env bash
SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
# disable randomized hash for string in Python 3.3+
export PYTHONHASHSEED=0
#spark-submit最终调用的是spark-class脚本
#传入的类是org.apache.spark.deploy.SparkSubmit
#及其它传入的参数,如deploy mode、executor-memory等
exec "$SPARK_HOME"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"spark-class脚本会加载spark配置的环境变量信息、定位依赖包spark-assembly-1.5.0-hadoop2.4.0.jar文件(以spark1.5.0为例)等,然后再调用org.apache.spark.launcher.Main正式启动Spark应用程序的运行,具体如下:
# Figure out where Spark is installed
#定位SAPRK_HOME目录
export SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
#加载load-spark-env.sh,运行环境相关信息
#例如配置文件conf下的spark-env.sh等
. "$SPARK_HOME"/bin/load-spark-env.sh
# Find the java binary
# 定位JAVA_HOME目录
if [ -n "${JAVA_HOME}" ]; then
RUNNER="${JAVA_HOME}/bin/java"
else
if [ `command -v java` ]; then
RUNNER="java"
else
echo "JAVA_HOME is not set" >&2
exit 1
fi
fi
# Find assembly jar
#定位spark-assembly-1.5.0-hadoop2.4.0.jar文件(以spark1.5.0为例)
#这意味着任务提交时无需将该JAR文件打包
SPARK_ASSEMBLY_JAR=
if [ -f "$SPARK_HOME/RELEASE" ]; then
ASSEMBLY_DIR="$SPARK_HOME/lib"
else
ASSEMBLY_DIR="$SPARK_HOME/assembly/target/scala-$SPARK_SCALA_VERSION"
fi
num_jars="$(ls -1 "$ASSEMBLY_DIR" | grep "^spark-assembly.*hadoop.*\.jar$" | wc -l)"
if [ "$num_jars" -eq "0" -a -z "$SPARK_ASSEMBLY_JAR" ]; then
echo "Failed to find Spark assembly in $ASSEMBLY_DIR." 1>&2
echo "You need to build Spark before running this program." 1>&2
exit 1
fi
ASSEMBLY_JARS="$(ls -1 "$ASSEMBLY_DIR" | grep "^spark-assembly.*hadoop.*\.jar$" || true)"
if [ "$num_jars" -gt "1" ]; then
echo "Found multiple Spark assembly jars in $ASSEMBLY_DIR:" 1>&2
echo "$ASSEMBLY_JARS" 1>&2
echo "Please remove all but one jar." 1>&2
exit 1
fi
SPARK_ASSEMBLY_JAR="${ASSEMBLY_DIR}/${ASSEMBLY_JARS}"
LAUNCH_CLASSPATH="$SPARK_ASSEMBLY_JAR"
# Add the launcher build dir to the classpath if requested.
if [ -n "$SPARK_PREPEND_CLASSES" ]; then
LAUNCH_CLASSPATH="$SPARK_HOME/launcher/target/scala-$SPARK_SCALA_VERSION/classes:$LAUNCH_CLASSPATH"
fi
export _SPARK_ASSEMBLY="$SPARK_ASSEMBLY_JAR"
# The launcher library will print arguments separated by a NULL character, to allow arguments with
# characters that would be otherwise interpreted by the shell. Read that in a while loop, populating
# an array that will be used to exec the final command.
#执行org.apache.spark.launcher.Main作为Spark应用程序的主入口
CMD=()
while IFS= read -d '' -r ARG; do
CMD+=("$ARG")
done < <("$RUNNER" -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@")
exec "${CMD[@]}"从上述代码中,可以看到,通过org.apache.spark.launcher.Main类启动org.apache.spark.deploy.SparkSubmit的执行,SparkSubmit部分源码如下:
//SparkSubmit Main方法
def main(args: Array[String]): Unit = {
//任务提交时设置的参数,见图2
val appArgs = new SparkSubmitAarguments(args)
if (appArgs.verbose) {
// scalastyle:off println
printStream.println(appArgs)
// scalastyle:on println
}
appArgs.action match {
//任务提交时,执行submit(appArgs)
case SparkSubmitAction.SUBMIT => submit(appArgs)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
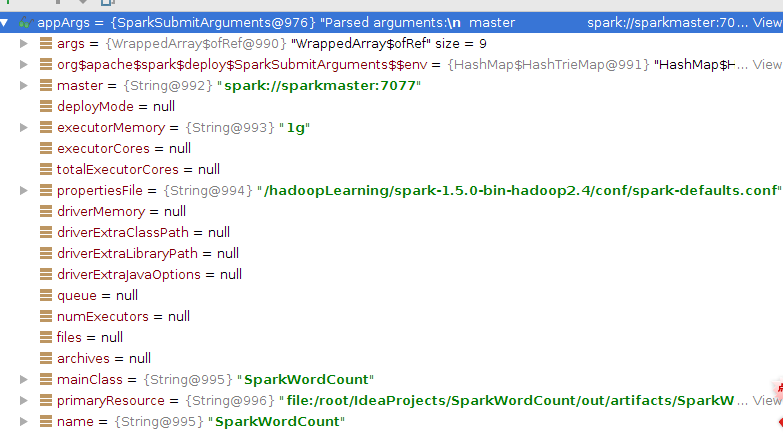
图1 appArgs = new SparkSubmitAarguments(args)参数
进入submit方法:
/**
* Submit the application using the provided parameters.
*
* This runs in two steps. First, we prepare the launch environment by setting up
* the appropriate classpath, system properties, and application arguments for
* running the child main class based on the cluster manager and the deploy mode.
* Second, we use this launch environment to invoke the main method of the child
* main class.
*/
private def submit(args: SparkSubmitArguments): Unit = {
//运行参数等信息,见图2
val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args)
//定义在submit方法中的方法doRunMain()
def doRunMain(): Unit = {
if (args.proxyUser != null) {
val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser,
UserGroupInformation.getCurrentUser())
try {
proxyUser.doAs(new PrivilegedExceptionAction[Unit]() {
override def run(): Unit = {
//执行runMain方法
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
})
} catch {
case e: Exception =>
// Hadoop's AuthorizationException suppresses the exception's stack trace, which
// makes the message printed to the output by the JVM not very helpful. Instead,
// detect exceptions with empty stack traces here, and treat them differently.
if (e.getStackTrace().length == 0) {
// scalastyle:off println
printStream.println(s"ERROR: ${e.getClass().getName()}: ${e.getMessage()}")
// scalastyle:on println
exitFn(1)
} else {
throw e
}
}
} else {
//执行runMain方法
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
}
// In standalone cluster mode, there are two submission gateways:
// (1) The traditional Akka gateway using o.a.s.deploy.Client as a wrapper
// (2) The new REST-based gateway introduced in Spark 1.3
// The latter is the default behavior as of Spark 1.3, but Spark submit will fail over
// to use the legacy gateway if the master endpoint turns out to be not a REST server.
if (args.isStandaloneCluster && args.useRest) {
try {
// scalastyle:off println
printStream.println("Running Spark using the REST application submission protocol.")
// scalastyle:on println
//调用submit方法中的doRunMain方法
doRunMain()
} catch {
// Fail over to use the legacy submission gateway
case e: SubmitRestConnectionException =>
printWarning(s"Master endpoint ${args.master} was not a REST server. " +
"Falling back to legacy submission gateway instead.")
args.useRest = false
submit(args)
}
// In all other modes, just run the main class as prepared
} else {
//调用submit方法中的doRunMain方法
doRunMain()
}
}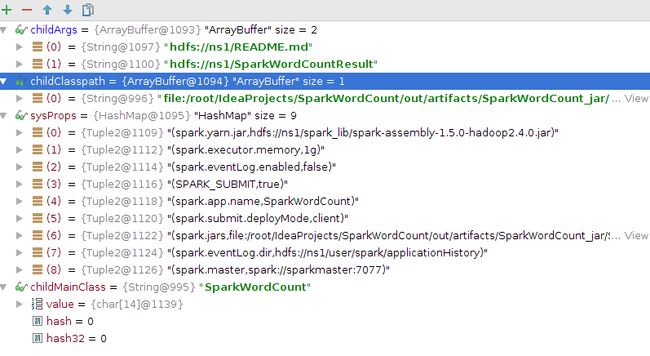
图2 任务提交时设置的参数,
从上面的代码可以看到,最终调用的是runMain方法,其源码如下:
/**
* Run the main method of the child class using the provided launch environment.
*
* Note that this main class will not be the one provided by the user if we're
* running cluster deploy mode or python applications.
*/
private def runMain(
childArgs: Seq[String],
childClasspath: Seq[String],
sysProps: Map[String, String],
childMainClass: String,
verbose: Boolean): Unit = {
// scalastyle:off println
if (verbose) {
printStream.println(s"Main class:\n$childMainClass")
printStream.println(s"Arguments:\n${childArgs.mkString("\n")}")
printStream.println(s"System properties:\n${sysProps.mkString("\n")}")
printStream.println(s"Classpath elements:\n${childClasspath.mkString("\n")}")
printStream.println("\n")
}
// scalastyle:on println
val loader =
if (sysProps.getOrElse("spark.driver.userClassPathFirst", "false").toBoolean) {
new ChildFirstURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
} else {
new MutableURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
}
Thread.currentThread.setContextClassLoader(loader)
for (jar <- childClasspath) {
addJarToClasspath(jar, loader)
}
for ((key, value) <- sysProps) {
System.setProperty(key, value)
}
var mainClass: Class[_] = null
try {
//复用反射加载childMainClass,这里为SparkWordCount
mainClass = Utils.classForName(childMainClass)
} catch {
case e: ClassNotFoundException =>
e.printStackTrace(printStream)
if (childMainClass.contains("thriftserver")) {
// scalastyle:off println
printStream.println(s"Failed to load main class $childMainClass.")
printStream.println("You need to build Spark with -Phive and -Phive-thriftserver.")
// scalastyle:on println
}
System.exit(CLASS_NOT_FOUND_EXIT_STATUS)
}
// SPARK-4170
if (classOf[scala.App].isAssignableFrom(mainClass)) {
printWarning("Subclasses of scala.App may not work correctly. Use a main() method instead.")
}
//调用反射机制加载main方法,即SparkWordCount中的main方法
val mainMethod = mainClass.getMethod("main", new Array[String](0).getClass)
if (!Modifier.isStatic(mainMethod.getModifiers)) {
throw new IllegalStateException("The main method in the given main class must be static")
}
def findCause(t: Throwable): Throwable = t match {
case e: UndeclaredThrowableException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: InvocationTargetException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: Throwable =>
e
}
try {
//执行main方法,即执行SparkWordCount
mainMethod.invoke(null, childArgs.toArray)
} catch {
case t: Throwable =>
throw findCause(t)
}
}mainMethod.invoke(null, childArgs.toArray)方法执行完毕后,进入SparkWordCount的main方法,执行Spark应用程序,如下图 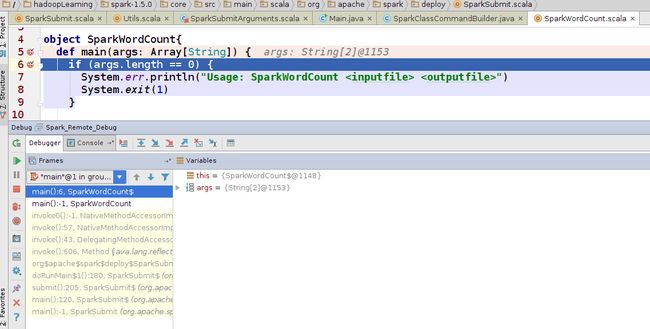
至此,正式完成Spark应用程序执行的提交。