Real-World Super-Resolution via Kernel Estimation and Noise Injection ---2020.08.10
介绍:2020 cvpr real world SR challenge NO.1
内容:论文翻译+实验细节
摘要:
不管blur和noise如何,最新的超分辨率方法在理想数据集上均具有出色的性能。但是,这些方法在现实世界中的图像超分辨率中始终会失败,因为它们大多数都从高质量图像采用简单的bicubic降采样来构造低分辨率(LR)和高分辨率(HR)对进行训练,这可能会丢失与频率相关的轨迹细节。为了解决这个问题,我们专注于通过估计各种模糊内核以及真实的噪声分布,为现实世界的图像设计一种新颖的降级框架。基于我们新颖的degradation framework,我们可以获得与现实世界图像common domain的LR图像。然后,我们提出了一个旨在更好感知的现实世界超分辨率模型。对合成噪声数据和真实世界图像进行的大量实验表明,我们的方法优于最新方法,从而降低了噪声并提高了视觉质量。此外,我们的方法还获得了NTIRE 2020挑战赛在现实世界超高分辨率解决方案上的冠军,这在很大程度上超越了其他竞争对手。

1. 引言
超分辨率(SR)任务是提高低质量图像的分辨率,并提高其清晰度[2]。 近年来,基于深度学习的方法[9,35,7,34,20,19,23]在保真性能方面取得了显著成果,其主要侧重于设计网络结构以进一步提高特定数据集的性能。 他们中的大多数人使用固定的 bicubic 运算进行下采样以构建训练数据对。 类似地,在测试阶段,将由bicubic下采样的输入图像馈送到设计的网络。 随后,将生成的结果与ground truth(GT)进行比较,以计算PSNR,SSIM和其他指标。
尽管保真度有所提高,但这些方法忽略的问题是使用理想的bicubic降采样是不合理的。 先前的方法通过理想的下采样方法构造数据:
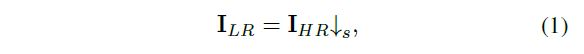
其中![]() 和
和![]() 分别表示LR和HR图像,而s表示scale factor。这使得获取训练模型的配对数据变得容易。 但是,使用这种已知且固定的down-sampling kernel,degraded image可能会丢失高频细节,但会使低频内容更清晰。 基于这样构造的配对数据,对SR模型f(·)进行训练,以最小化n个图像的平均误差:
分别表示LR和HR图像,而s表示scale factor。这使得获取训练模型的配对数据变得容易。 但是,使用这种已知且固定的down-sampling kernel,degraded image可能会丢失高频细节,但会使低频内容更清晰。 基于这样构造的配对数据,对SR模型f(·)进行训练,以最小化n个图像的平均误差:
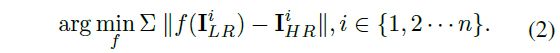
如果在相同的下采样数据集上进行测试,则生成的结果将与预期的一样。 但是,一旦我们直接对原始图像进行测试,结果就会变得非常模糊,并带有很多噪点。 主要原因是bicubic downsampling后的图像与原始图像不属于common domain。 由于domain gap,这些方法会产生令人不愉快的artifacts,并在真实世界的图像上失败。 例如,EDSR / ZSSR在图1中产生的真实图像结果不令人满意。因此,现实世界中超分辨率的关键问题是引入一种精确的degradation方法,以确保生成的低分辨率(LR)图像和原始图像具有same domain attributes。
我们首先分析不同kernel对下采样图像的影响[42、49、11]。 在我们进行分析之前,我们将原始真实图像定义为source domain X,将干净的高分辨率(HR)图像定义为target domain Y。我们发现不同程度的blur kernel直接影响下采样图像的模糊。 bicubic可被视为下采样的理想方式,因为它尽可能保留了来自X的信息。 但是,这些降采样后的图像的频率已更改为另一个域X'。在{X',Y}上进行训练时,由于所有信息在域X'中都很重要,因此该模型将尝试恢复所有细节。 该模型在![]() 上运行良好,但通常在Isrc∈X上失败,这是未处理的真实图像。 另一个问题是降采样后的图像几乎没有噪点,而X中的实际图像通常有很多。 仅对模糊内核的估计不能准确地对退化过程进行建模。
上运行良好,但通常在Isrc∈X上失败,这是未处理的真实图像。 另一个问题是降采样后的图像几乎没有噪点,而X中的实际图像通常有很多。 仅对模糊内核的估计不能准确地对退化过程进行建模。
在本文中,我们提出了一种新颖的逼真的超分辨率降级框架(RealSR),其中包含内核估计和噪声注入以保留原始域属性。一方面,我们首先使用现有的内核估计方法[3]来生成更逼真的LR图像。另一方面,我们提出了一种简单有效的方法,可以直接从原始图像中收集噪声并将其添加到降采样后的图像中。此外,我们为RealSR引入了patch discriminator[17],以避免生成伪像。
为了验证该方法的有效性,我们在合成数据集和真实数据集上进行了实验。实验结果表明,与最新方法相比,我们的方法可产生更清晰,更清晰的结果。
最后,我们进行了消融实验,以验证核估计,噪声注入和SR生成器的补丁鉴别器的有效性。
我们还参加了“ NTIRE 2020现实世界超分辨率挑战赛”,并且在两个方面都大大领先于其他竞争对手。
In summary, our overall contribution is three-fold:
• We propose a novel degradation framework RealSR under real-world setting, which provides realistic images for super-resolution learning.
• By estimating the kernel and noise, we explore the specific degradation of blurry and noisy images.
• We demonstrate that the proposed RealSR achieves state-of-the-art results in terms of visual quality.
2. 相关工作
Super resolution
近来,许多基于卷积神经网络(CNN)的SR网络[23、30、13、14、22、31、41]在bicubic下采样图像上实现了强大的性能。其中代表性的是EDSR [23],它使用深度残差网络来训练SR模型。张等 [46]提出了一种residual in residual structure,以形成非常深的网络,该网络比EDSR具有更好的性能。戴等[8]提出了一种second-order channel attention module,通过使用second-order feature statistics来进行更具判别性的表示,以自适应地重新调整信道方式的特征。哈里斯等[12]提出了深层反投影网络来利用迭代的上,下采样层,为每个阶段的投影误差提供了一种误差反馈机制。尽管作者在保真度方面取得了良好的性能,但是生成的图像的视觉效果较差并且显得模糊。为了解决这个问题,一些研究人员通过空间特征变换来增强逼真的纹理[47,48,38]。 Soh等提出了一种自然的歧管判别方法,以将HR图像与模糊或嘈杂的图像进行分类,以监督生成的图像的质量。此外,一些基于对抗性生成网络(GAN)的方法[21,44,39]更加关注视觉效果,引入了对抗性损失和知觉损失。
但是,这些在BICUBIC kernel生成的数据上训练的SR模型只能在干净的HR数据上很好地工作,因为该模型在训练过程中从未见过模糊/嘈杂的数据。 这与现实世界的需求不一致,并且真实的LR图像经常带有noise和blur。 为了解决这种冲突,Xu等人[40,5,4,45]直接使用特定的摄像设备从自然场景中收集原始照片对。 但是收集这样的配对数据需要严格的条件和大量的人工成本。 在本文中,我们通过分析真实图像的降级,着重研究了SR网络在真实数据中的训练策略。
Real-World Super-Resolution
为了克服现实世界中超分辨率的这些挑战,已经提出了结合去噪或去模糊的最新工作[42,49]。 这些方法在人工构建的模糊和添加了噪声的数据上进行了训练,从而进一步增强了SR模型的鲁棒性。 然而,这些显式建模方法需要足够的关于模糊/噪声的先验,因此应用范围受到限制。
最近,一系列现实世界中的超分辨率挑战[25,26]吸引了许多参与者。 提出了许多新颖的方法来解决这个问题。 例如,Fritsche等[10]提出了DSGAN模型来生成退化图像。 Lugmayr等[24]提出了一种用于现实世界中超分辨率的无监督学习方法。 ZSSR [32]放弃了对大数据的训练过程,而是为每个测试图像训练了一个小模型,因此特定模型更加关注图像的内部信息。 但是付出的代价是推理时间大大增加,这很难应用于真实场景。 与这些方法不同,我们显式估计真实图像中的内核退化,这对于生成clear and sharp results非常重要。
3. The Proposed RealSR
在本节中,我们介绍如图2所示的proposed degradation method。我们的方法主要分为两个阶段。
- 第一步是根据实际数据估算退化程度,并生成逼真的LR图像。
- 第二阶段是根据构建的数据训练SR模型。
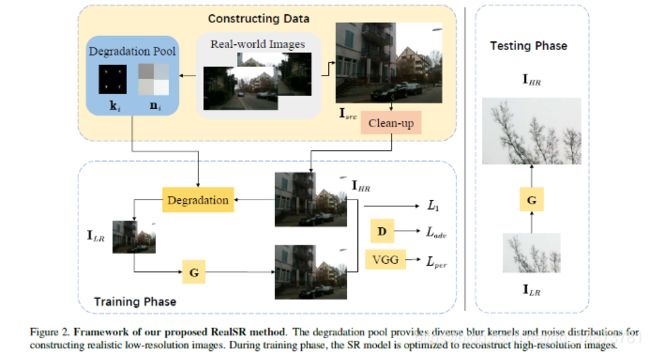
3.1 Realistic Degradation for Super Resolution
在这里,我们介绍一种基于kernel estimation and noise injection的真实图像质量下降的新方法。 假定通过以下降级方法获得LR图像:
![]()
其中,k和n分别表示模糊的内核和噪声。 ![]() 未知,表明k和n也未知。 为了更准确地估计退化方法,我们明确估计了图像的kernel和noise。 在获得估计的kernel and noise patch之后,我们建立了一个degradation pool,该degradation pool用于将干净的HR图像降级为blurry and noisy images,从而生成用于训练SR模型的图像对。 为了简明地描述我们的方法,我们将该data-constructing pipeline形式化为算法1中所示的算法。
未知,表明k和n也未知。 为了更准确地估计退化方法,我们明确估计了图像的kernel和noise。 在获得估计的kernel and noise patch之后,我们建立了一个degradation pool,该degradation pool用于将干净的HR图像降级为blurry and noisy images,从而生成用于训练SR模型的图像对。 为了简明地描述我们的方法,我们将该data-constructing pipeline形式化为算法1中所示的算法。

3.2 Kernel Estimation and Downsampling
我们使用kernel estimation algorithm从实际图像中显式估计kernel。 受KernelGAN [3]的启发,我们采用了类似的kernel estimation 方法,并根据真实图像设置适当的参数。 KernelGAN的生成器是没有任何激活层的线性模型,因此所有层的参数都可以组合为固定的内核。 estimated kernel需要满足以下约束:
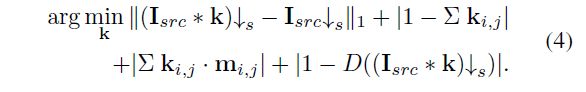
![]() :是使用内核k下采样的LR图像,
:是使用内核k下采样的LR图像,
![]() : 是具有理想内核的下采样图像,因此,要使该误差最小化,是为了鼓励下采样图像保留源图像的重要低频信息。
: 是具有理想内核的下采样图像,因此,要使该误差最小化,是为了鼓励下采样图像保留源图像的重要低频信息。
此外,上述公式的第二项是将k限制为1,而第三项是对k的惩罚边界。
最后,鉴别符D(·)是为了确保source domain的一致性。
Clean-Up
为了获得更多的HR图像,我们尝试从X生成无噪声的图像。具体地说,我们在sourse domain 中对实际图像采用bicubic降采样以消除噪声并使图像更清晰。 设Isrc∈X是来自真实源图像集的图像,而kbic是理想的bicubic kernel。 然后,使用clean-up scale factor sc对图像进行降采样。
![]()
Degradation with Blur Kernels
我们将降采样后的图像视为干净的HR图像。 然后,通过从degradation pool中随机选择模糊内核,对这些HR图像执行degradation。下采样过程是cross-correlation operations,然后是步长为s的采样,其表达式可为:
![]()
其中,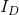 表示降采样的图像,ki表示从{k1,k2···km}中选择的特定模糊内核。
表示降采样的图像,ki表示从{k1,k2···km}中选择的特定模糊内核。
3.3 Noise Injection
对于noisy images,我们将噪声显式注入降采样后的图像以生成逼真的LR图像。 由于高频信息在下采样过程中丢失,因此降级的噪声分布会同时发生变化。 为了使降级图像具有与源图像相似的噪声分布,我们直接从源数据集X收集噪声补丁。我们观察到内容含量更高的补丁具有较大的方差。 基于这种观察并受到[6,49]的启发,我们设计了一个filtering rule来收集patches在一定范围内的方差。 简单但有效地,我们通过以下规则将噪声和内容分离:
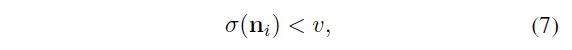
其中![]() 表示计算方差的函数,而v是方差的最大值。
表示计算方差的函数,而v是方差的最大值。
Degradation with Noise Injection
假设收集了一系列噪声noise patches {n1,n2 ... nl}并将其添加到degradation pool中。 噪声注入过程是通过从noise pool中randomly cropping patches来执行的。 同样,我们将此流程形式化为:
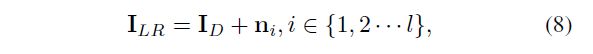
其中ni是来自noise pool的经裁剪的noise patch,由{k1,k2···kl}组成。
详细地,我们采用在线噪声注入方法,在训练阶段将内容和噪声结合在一起。 这使噪声更加多样化,并规范化了SR模型以区分带有噪声的内容。经过模糊核和注入噪声的退化后,我们得到![]() ∈X。
∈X。
3.4 Super Resolution Model
基于ESRGAN [39],我们实现了一个SR模型,并在构造的配对数据{ILR,IHR}∈{X,Y}上训练它。 生成器采用RRDB [39]结构,生成图像的分辨率将放大4倍。 训练有几种损失,包括像素损失,知觉损失[18]和对抗损失。 像素损失L1使用L1距离。 感知损失Lper使用VGG-19的非活动功能[33],这有助于增强低频功能(如边缘)的视觉效果。 对抗损失Ladv用于增强生成图像的纹理细节,使其看起来更逼真。 最终损失函数是这三个损失的加权和:
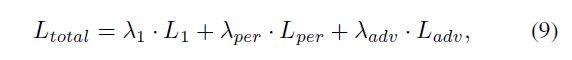
where λ1, λper, and λadv are set as 0.01, 1, and 0.005 empirically(根据经验).
3.5 Patch Discriminator in RealSR
此外,我们观察到ESRGAN [39]鉴别器可能会引入许多artifacts。 与默认的ESRGAN设置不同,我们使用patch discriminator [17,50]代替VGG-128 [33],这有两个便利:1)VGG-128将生成的图像的大小限制为128,这使得多尺度训练不方便。 2)VGG-128包含一个更深的网络,其固定的完全连接层使区分器更加关注全局功能,而忽略了局部功能。 相反,我们使用patch discriminator with fully convolution structure,它具有固定的感受野。例如,三层网络对应于一个70×70的patch。 即,discriminator的每个输出值仅与局部固定区域的patch有关。 Patch losses将反馈给发生器,以优化局部细节的梯度。 请注意,最终误差是所有局部误差的平均值,以确保全局一致性。
4. Experiments
4.1. Datasets
DF2K
DF2K数据集合并了DIV2K [36]和Flikr2K [1]数据集,总共包含3450张图像。 这些图像会被人为添加高斯噪声以模拟传感器噪声。 验证集包含100张具有相应地ground truth的图像,因此可以计算基于参考的度量标准。
DPED
DPED [15]数据集包含iPhone3相机拍摄的5614张图像。 此数据集中的图像是未经处理的真实图像,更具挑战性,包括噪声,模糊,暗光和其他低质量问题。 验证集中的100张图像是从原始真实图像中裁剪出来的。 由于没有相应的基本事实,因此我们只能提供视觉比较。
4.2. Evaluation Metrics
对于合成数据,我们计算通过不同方法生成的结果的PSNR,SSIM和LPIPS [43]。
- 其中,PSNR和SSIM是图像恢复的常用评估指标。 这两个指标更加关注图像的保真度,而不是视觉质量。
- 相反,LPIPS更加关注图像的视觉特征是否相似。 它使用预先训练的Alexnet提取图像特征,然后计算两个特征之间的距离。 因此,LPIPS越小,生成的图像就越接近地面真实性。
4.3. Evaluation on Corrupted Images
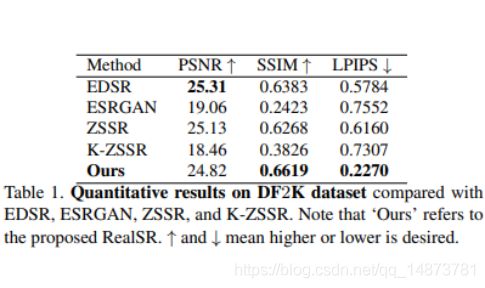
首先,我们将RealSR与最先进的SR方法对损坏的DF2K数据集进行比较。 我们评估包含100张图像的验证集的性能。 通过这些方法生成结果后,我们将根据实际情况计算PSNR,SSIM和LPIPS。 由于LPIPS可以更好地反映视觉质量,因此我们主要关注此指标。 比较方法包括EDSR [23],ESRGAN [39],ZSSR [32],K-ZSSR。 我们使用作者发布的预训练模型评估EDSR和ESRGAN方法。 由于ZSSR不需要训练过程,因此我们只需在验证图片上运行其测试代码即可。 具体来说,K-ZSSR是KernelGAN [3]和ZSSR的组合。 由Kernel-GAN估计的内核用于ZSSR训练期间的图像块降采样,而ZSSR采用默认的双三次降级。
Quantitative Results on DF2K
如表1所示,我们的RealSR实现了最佳的LPIPS性能,这表明我们的结果在视觉特性方面更接近ground truth。 请注意,我们的方法的PSNR低于EDSR,这是因为我们使用的感知损失更加关注视觉质量。 通常,PSNR和LPIPS度量不是正相关的,甚至在一定范围内显示相反的关系。
Qualitative Results on DF2K
从图3中,我们可以看到同一图像上不同方法的局部细节,其中RealSR产生的噪声要少得多。 一方面,与EDSR和ZSSR相比,通过更丰富的纹理细节,我们的结果更加清晰。 另一方面,与ESRGAN和K-ZSSR相比,我们的结果几乎没有伪像,这得益于实际噪声分布估计的准确降级。 特别是,K-ZSSR使用比双三次方更模糊的内核,因此用于训练的图像几乎没有噪点,当喂入有噪点的图像时会导致许多伪像。 在测试过程中,SR模型将噪声误认为是输入图像的内容。

4.4 Evaluation on Real World Images
我们提出的方法最关心的问题是现实世界的超分辨率,因此我们在DPED数据集上评估RealSR,其中照片遭受诸如模糊,噪点等降级问题的困扰。就像SR训练中遇到的问题一样 真实图像,没有在验证阶段可以参考的事实。 因此,我们仅显示视觉比较的结果。 In order to make the details clearer,we enlarge the local area.
Qualitative Results on DPED
如图4所示,EDSR,ESRGAN和ZSSR方法无法正确地区分来自树枝和天空的噪声,从而导致模糊的结果。 在我们的结果中,主干和分支更加清晰,对象和背景之间的分界线更加清晰。 关于K-ZSSR,由于对噪声的错误处理,结果会产生不必要的纹理细节。 如果放大,则此结果是不可接受的,不能视为HR图像。 当处理一些扎实的背景时,我们方法的优势更加明显。 从第三幅图像可以看出,屋檐下的噪声已被消除,仅留下了重要的低频特征。
与现有方法相比,我们的RealSR产生的噪声和伪像很少,这表明通过噪声注入估算出的噪声更接近真实噪声。 与EDSR,ESRGAN和ZSSR相比,我们的RealSR结果更加清晰明确。 这是因为他们的方法都是在双三次数据上训练的,而没有从实际图像中估计模糊的内核。 另外,我们使用感知损失,它更加关注图像的视觉特征。 与使用像素损失的EDSR相比,我们的结果具有更清晰的细节。 而且,训练新的ZSSR或K-ZSSR模型的成本比推理要高得多,而我们的方法仅在推理过程中花费了前进时间。

4.5. NTIRE 2020 Challenge
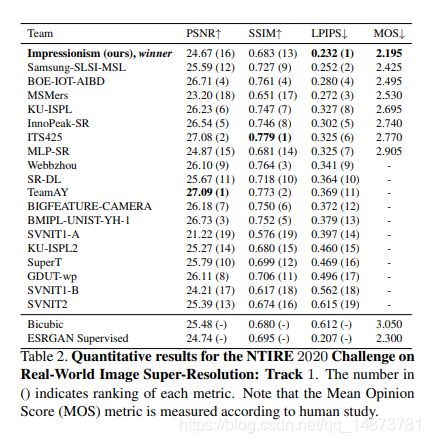
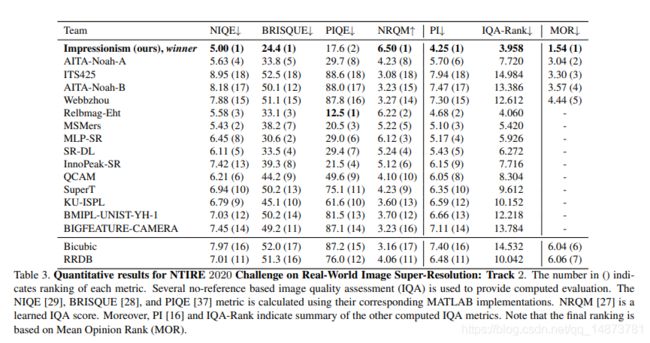
Our RealSR is the winner of NTIRE 2020 Challenge on both tracks of Real-World Super-Resolution [26], where Track 1 is synthetic corrupted data via image processing artifacts and Track 2 is real data of smartphone images.
每个轨道提供的数据包括两个域。一个是包含噪声和模糊的源域数据集,另一个是定义的干净HR目标数据集。任务是将LR图像的分辨率扩大4倍,并使生成的SR图像的清晰度和清晰度与给定的目标数据集保持一致。由于没有用于训练的给定数据对,因此参与者需要使用这两套图像来构造训练数据。如表2和表3所示,我们应用了所提出的方法并在两个轨道上均取得了最佳结果。请注意,最终决策基于人类研究,即轨道1的平均意见得分(MOS)和平均意见等级(MOR)音轨2 [26]。我们的方法在很大程度上优于其他方法,并生成具有出色清晰度和清晰度的SR图像。
4.6. Ablation Study
为了进一步验证估计内核的必要性,在降级过程中注入噪声以及在SR训练过程中使用patch discriminator ,我们对DPED数据集进行了消融实验。 我们首先介绍每个实验的设置。
- Bicubic: Under this setting, we adopt bicubic kernel to downsample HR images, and then directly use these paired data to train SR model. Without kernel estimation and noise injection, this setting keeps other parameters as default, which can be understood as fine-tuning ESRGAN on the real dataset to verify its robustness.
- Noise: This setting is to add noise injection on the basis of bicubic. Because the kernel estimation method is not used, this setting can be observed to verify the validity of the kernel estimation when compared with the proposed complete method.
- Kernel: This setting only uses the kernel estimation method, but no explicit noise is added, so it can be used to observe the effect of noise injection on the result.
- VGG-128: As discussed in Section 3.5, this setting uses the default VGG-128 discriminator.
- Patch: This setting uses a lighter patch discriminator, which is compared with the previous four settings to verify our conclusion.
接下来,我们演示三个比较分析,以验证三个提议的组件的有效性。
- Effect of the Kernel Estimation
从图5可以看出,与“噪声”相比,生成的结果“patch”更为清晰。 这证明了核估计对于SR训练很重要,这有助于SR模型产生更 sharper edges.
- Effect of the Noise Injection
在此对比实验中,我们将噪声注入作为选项来验证是否有必要注入噪声。 从图5可以看出,在没有显式噪声注入的情况下,``kernel''的结果有很多artifacts,这与在干净数据上训练的ESRGAN结果非常相似。 注入的噪声与原始噪声分布一致,从而确保SR模型对测试期间的噪声具有鲁棒性。
- Effect of the Patch Discriminator
对于真实数据,我们使用patch discriminator 替换VGG-128。 将“patch”与“ VGG-128”进行比较,我们发现receptive field过大的VGG-128鉴别器将导致虚幻的纹理,这与原始图像有部分冲突。 相比之下,patch discriminator to可恢复重要的边缘特征,并避免令人不快的artifacts,从而生成更真实的细节。
5. Conclusion
在本文中,我们提出了一种基于内核估计和噪声注入的新型降级框架RealSR。 通过使用降级的不同组合(例如,模糊和噪声),我们获得了与真实图像共享同一域的LR图像。 借助这些领域一致的数据,我们然后使用斑块鉴别器训练真实图像超分辨率GAN,从而可以更好地感知HR结果。 对合成噪声数据和真实图像进行的实验表明,我们的RealSR优于最新方法,从而降低了噪声并提高了视觉质量。 此外,我们的RealSR还是真实世界超级分辨率两个方面的NTIRE 2020挑战赛的获胜者,在人类感知方面大大优于其他方法。