简单易懂 Mysql B+Tree索引
索引是为了加速对表中数据行的检索而创建的一种分散存储的数据结构,在RDBMS系统中数据的索引都是硬盘级索引。
hash索引:查询快(时间复杂度O(1) ),不支持范围查询(比如like,>,<=)
innodb不支持Hash索引,但是在底层有一个自适应Hash索引的应用(见下文)
innodb B+Tree索引结构演变
-
二叉搜索树
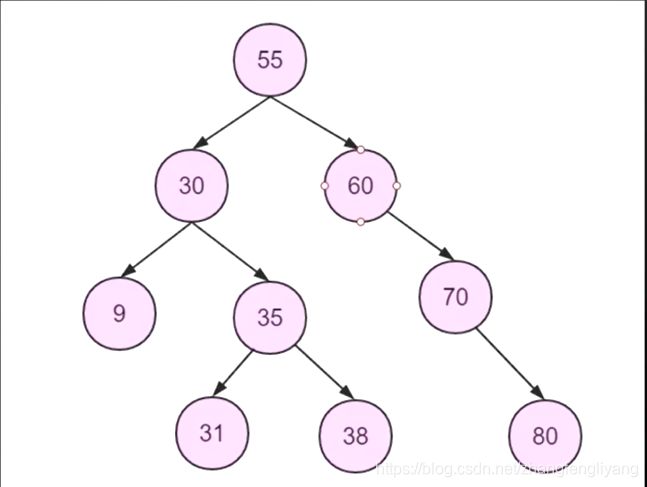

问题:当主键是自增长主键时,二叉树就会变成单链表结构,数据的查询复杂度就会变成O(n),不符和索引加快查询速度的要求。
-
平衡二叉搜索树
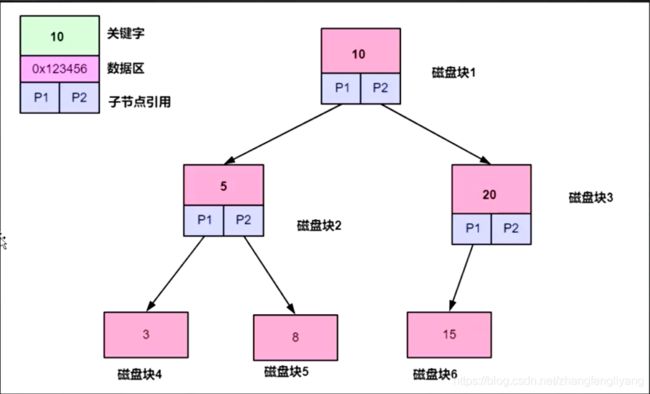
特点:树中的每一个节点的与它的子节点的高度差不允许超过1。
问题:
1:树的高度太高(每扫描一个树节点都要做一次磁盘io,io太多)
2:没有利用好操作系统和磁盘的交互特性(扫描一个树节点都要做一次磁盘io,加载的数据太少,造成io浪费)
-
多路平衡树(B树)

特点:绝对平衡,所有子节点的高度都在同一个水平线上
搜索步骤:以当前树为例,每一个树节点将空间划为5个区间,比如根节点将空间划为(-∞,17),17,(17,35),35,(35,+∞),当搜索17或35时就会直接命中根节点,当搜索第一个区间的数字时就会走根节点的左子树,搜索第3个区间就会走中间的分支,搜索第5个区间就会走右子树。
解决问题:将平衡二叉搜索树,这样一种瘦高的数据结构改为矮胖的数据结构,很好的解决了树高问题;再者假如我们一个磁盘块大小为4k,关键字假如是int类型,那么大小为4byte,再加上数据区的大小假如也是4byte,也就是说一个磁盘块大约可以放(4K*1024)/(4byte+4byte)=512个关键字,通过上面的树形结构,我们可以知道,假如关键字是2个,那么第二层就是3个节点,如果按照512个关键字,第二层就是512+1个节点,每个节点可以放512个关键字,那么两层我们就可以放512+512*(512+1)=263168约等于26万的数据,也就是说在充分利用磁盘的情况下,两层的B树就可以存储26万的数据。B树结构很好的解决了树高和磁盘Io问题,但是相比B+树还是稍有逊色。
-
加强版多路平衡树(B+树)
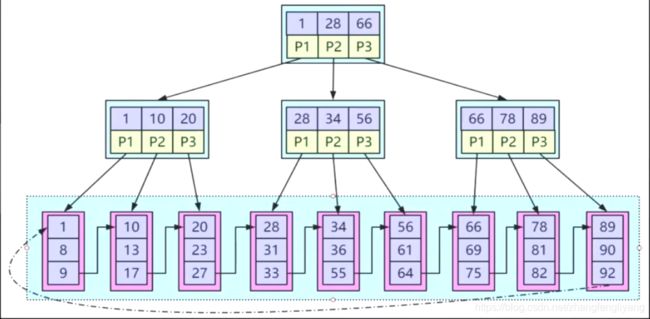
特点:非叶子节点没有数据区,叶子节点才有数据区,并且叶子节点形成了一个天然有序的链表结构
搜索步骤:以当前树为例,每一个树节点将空间划为3个区间,比如根节点将空间划为[1,28),[28,66),[66,+∞),当搜索第一区间的数字时,会走根节点的左子树,搜索第2个区间就会走中间的分支,搜索第3个区间就会走右子树。
优点:
1、如果非叶子节点不存储数据区,那么单个节点存储的关键字会多余B树,io能力强于B树
2、全表扫描只需要扫最后一层,针对基于索引的全表扫描优于B树,B树需要扫描全表
3、基于叶子节点的有序列表使得针对索引范围查询强于B树
4、查询性能稳定,查询任意关键字都需要扫描到叶子节点
B+Tree索引的落地及实践
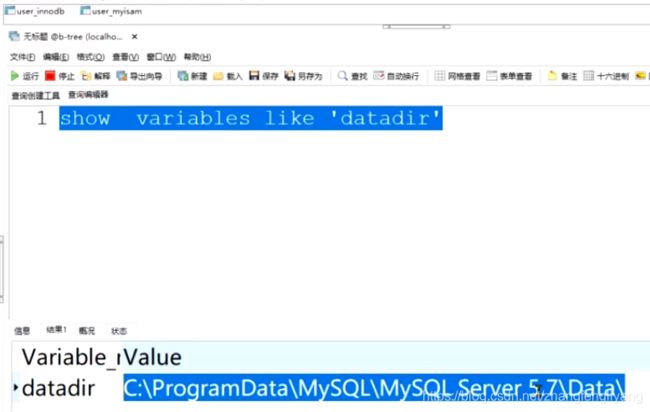

通过执行 show variables like 'datadir' 命令我们可以知道mysql数据存储目录,我们在b-tree这个数据库建了两张表,一张表基于innodb引擎,一张基于myisam引擎,从右上图中我们可以看出innodb表有2个文件,myisam有3个文件,其中后缀为.frm的是表的框架文件或者表结构定义文件,另外的文件是数据文件。
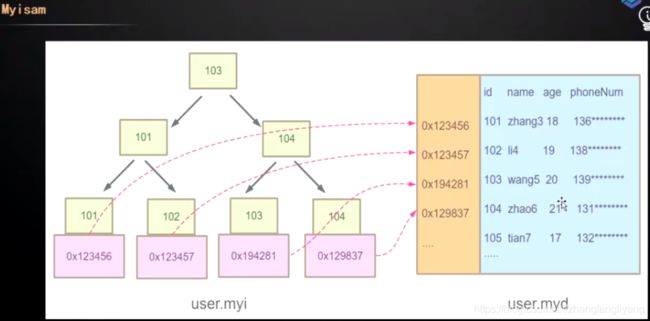
上图是myisam两个文件存储的数据内容,后缀为.MYI存储着索引文件,.MYD存储的数据文件,myisam索引树的叶子节点存储的是数据行地址,不论主键索引还是其它普通索引都是如上图所示的数据结构,叶子节点始终存储的是数据行地址

上图是innodb一个文件存储的数据内容,它是基于主键索引来存储数据的,辅助索引的叶子节点存储的是行主键

自适应hash索引(上面提到):在mysql运行过程中,如果innodb发现很多sql执行存在每次都会很长路径,就会在buffer开辟一块空间,建立自适应hash索引
B+Tree索引的正确姿势
-
列的离散性

离散性(列的重复度),离散性越好的作为索引区分度越高,可以更快的查到指定记录
问题:name like '123%' 当name是索引时,就一定会用到索引吗?
答案:不一定,当name的离散性很差时,比如很多数据name的前缀是123时,这时使用索引查询不一定比全表查询快,mysql会自己选择最优执行计划
-
最左匹配原则

问题:针对联合索引 users(name,phoneNum,age),执行sql:select * from users where name='张三丰' and phoneNum>13666666666 and age=20,查询语句会在联合索引中匹配哪些列?
答案:只会使用name 和 phoneNum 索引(最左匹配原则,范围之后全失效)
-
覆盖索引
定义:通过索引项的信息可直接返回所需的查询列,则该索引称之为查询sql的覆盖索引
举例:

-
索引使用打油诗一首
