《MySQL 技术内幕》事务
文章目录
- 前言
- 认识事物
- 事务的实现
- 事务控制语句
- 隐式提交的 SQL 语句
- 对于事务操作的统计
- 事务的隔离级别
- 分布式事务
- 不好的事务习惯
- 长事务
前言
- 事务(Transaction)是数据库区别于文件系统的重要特性之一
- 数据库系统引入事务的主要目的
- 事务会把数据库从一种一致状态为另一种一致状态
- 数据库提交时,可以确保要么全部修改都已经保存,要么所有修改都不保存
- InnoDB 存储引擎中的事务完全符合 ACID 的特性(原子性、一致性、隔离性、持久性
认识事物
-
概述
- 事物是访问并更新数据库中各种数据项的一个程序执行单元
- 事务中的操作,要么都做修改,要么都不做,这就是事务的目的,也是事务模型区别于文件系统的重要特征之一
- 对于 InnoDB 存储引擎而言,其默认的事务隔离级别为
READ REPEATABLE,完全遵循和满足事务的 ACID 特性- A(Atomicity) 原子性,指整个数据库事务是不可分割的工作单位
- C(Consistency)一致性,指事务将数据库从一种状态转变为下一种一致的状态
- I(Isolation)隔离性,指要求每个读写事务的对象对其他事务的操作对象能相互隔离
- D(Duration)持久性,指事务一旦提交,其结果就是永久性的
-
分类
-
从事务理论的角度来说,事务可分为以下几类
- 扁平事务(Flat Transactions)
- 带有保存点的扁平事务(Flat Transactions with Savepoints)
- 链事务(Chained Transactions)
- 嵌套事务(Nested Transactions)
- 分布式事务(Distributed Transactions)
-
扁平事务是事务类型中最简单的一种,但在实际生产环境中,这可能是使用最为频繁的事务
- 扁平事务是应用程序成为原子操作的基本组成模块
- 扁平事务的三种情况
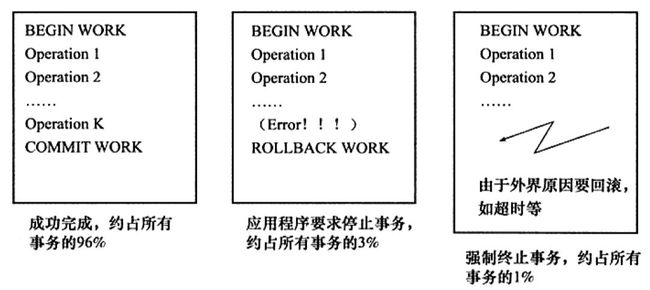
- 扁平事务的主要限制是不能提交或者回滚事务的某一部分,或分几个步骤提交
-
带有保存点的扁平事务
-
指支持扁平事务支持的操作外,允许在事务执行过程中回滚到同一事务中较早的一个状态
-
保存点(Savepoint)用来通知系统应该记住事务当前的状态,以便错误时能回到保存点当时的状态
- 对应扁平事务来说,其隐式地设置了一个保存点(事务开始时的状态
- 保存点用 SAVE WORK 函数来建立,通知系统记录当前的处理状态
- 保存点在事务内部是单调递增的,ROLLBACK 不影响保存点的计数
-
栗子:在事务中使用保存点

-
-
链事务可视为保存点模式的一种变种
- 带有保存点的扁平事务中的保存点时易失的,而非持久的,系统崩溃时,索引保存点都将消失
- 意味着当进行恢复时,事务需要从开始处重新执行,而不能从最近的一个保持点继续执行
- 链事务的思想
- 提交一个事务时,释放不需要的数据对象,将必要的处理上下文隐式传给下一个开始的事务
- 提交事务操作和开始下一个事务操作将合并为一个原子操作
- 链事务的工作方式

- 与带有保存点的扁平事务不同之处
- 带有保存点的扁平事务能回滚到任务正确的保存点,而链事务中的回滚仅限于当前事务
- 即只能恢复到最近的一个的保存点
- 链事务在执行 COMMIT 后释放了当前事务所持有的锁,而前者不影响迄今为止所持有的锁
- 带有保存点的扁平事务能回滚到任务正确的保存点,而链事务中的回滚仅限于当前事务
- 带有保存点的扁平事务中的保存点时易失的,而非持久的,系统崩溃时,索引保存点都将消失
-
嵌套事务是一个层次结构框架,又一个顶层事务控制各个层次的事务(子事务,控制每一个局部的变换)
- 嵌套事务的层次结构
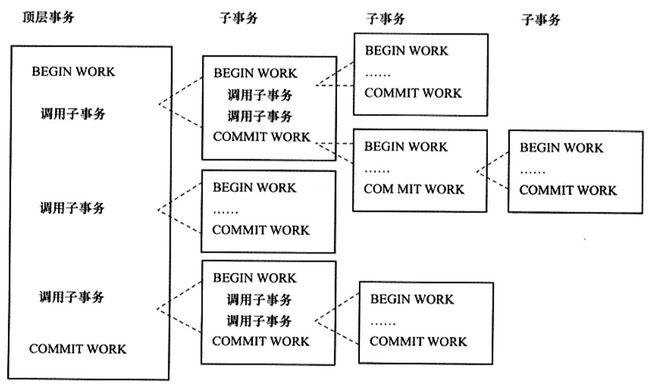
- 嵌套事务的定义
- 嵌套事务是由若干事务组成的一棵树,子树既可以是嵌套事务,也可以说是扁平事务
- 处在叶节点的事务是扁平事务(子事务从根到叶节点的距离可以是不同的
- 处于根节点的事务称为顶层事务,其他事务称为子事务(事务的前驱称为父事务,下一层称为儿子事务
- 子事务既可以提交也可以回滚(但它的提交操作并不马上生效,除非其父事务已经提交
- 树中的任意一个事务的回滚会引起它的所有子事务一同回滚(子事务仅保留 A、C、I 特性,不具备 D
- 在 Moss 的理论中,实际的工作是交由叶子节点来完成的,高层的事务仅负责逻辑控制
- 即只有叶子节点的事务才能访问数据库、发送消息、获取其他类型的资源
- 高层事务绝对何时调用相关的子任务
- 用保存点技术来模拟嵌套事务
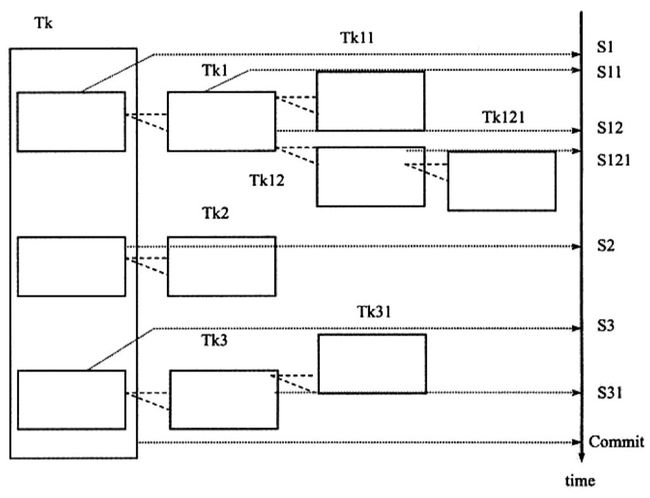
- 用保存点技术来模拟嵌套事务与嵌套查询的区别
- 模拟实现的嵌套事务无法选择哪些锁需要被子事务继承,所有锁住的对象都可以被得到和访问
- 嵌套查询中,不同的子事务在数据库对象上持有的锁是不相同的(同时也支持反向继承
- 同时模拟实现的嵌套事务无法实现并行执行(带有保存点的事务仅能模拟串休的嵌套事务
- 嵌套事务的层次结构
-
分布式事务通常是一个在分布式环境下运行的扁平事务,需要根据数据所在位置访问网络中的不同节点
- 对于分布式事务,其同样需要满足 ACID 特性,要么都发生,要么都失效
-
事务的实现
- 事务隔离性是由锁来实现
- redo log 称为重做日志,用来保证事务的原子性和持久性
- undo log 用来保证事务的一致性
- redo 和 undo 的作用都可以视为一种恢复操作
- redo 恢复提交事务修改的页操作(物理日志,记录的是页的物理修改操作
- undo 回滚行记录到某个特定版本(逻辑日志,根据每行记录进行记录
-
redo
-
基本概念
-
重做日志用来实现事务的持久性,即事务 ACID 中的 D,其由两部分组成
- 一是内存中的重做日志缓冲(redo log buffer),其是易失的
- 二是重做日志文件(redo log file),其是持久的
-
InnoDB 是事务的存储引擎,其通过 Force Log at Commit 机制实现事务的持久性
- 即当事务提交时,必须先将该事务的所有日志写入到重做日志文件进行持久化,待 COMMIT 后才算完成
-
redo log 与 undo log
- 前者用来保证事务的持久性,且基本上都是顺序写,在数据库运行时不需要对 redo log 的文件进行读取
- 后着用来帮助事务回滚及 MVCC 功能,且是需要进行随机读写的
-
为了确保每次日志都写入重做日志文件,重做日志缓冲写入重做日志文件后,需要再执行一次 fsync 操作
- 因为重做日志文件打开并没有使用 O_DIRECT 选项,因此重做日志缓冲先写入的是文件系统缓存
- 由于 fsync 的效率取决于磁盘的性能,因此 磁盘性能 -> 事务提交性能 -> 数据库性能
-
参数
innodb_flush_log_at_trx_commit用来控制重做日志刷新到磁盘的策略参数 含义 0 事务提交时不进行写入重做日志操作(利用 master thred 中每秒进行重做日志文件的 fsync 操作 1 事务提交时必须调用一次 fsync 操作(默认参数) 2 事务提交时仅写入至文件系统的缓存中,不进行 fsync操作 - 参数0 :可能导致在数据库发生宕机时,丢失最后一段时间的事务
- 参数2:数据库宕机不会丢失事务,但操作系统宕机时,会丢失未从文件系统缓存刷新到日志文件的事务
- 不同的
innodb_flush_log_at_trx_commit设置对应插入的速度影响

-
MySQL 数据库中还有一种二进制日志(binlog),用来进行 POINT-IN-TIME 的恢复及主从复制环境建立
-
重做日志与二进制日志的区别
- 重做日志在 InnoDB 存储引擎层产生,二进制日志是在 MySQL 数据库的上层产生的
- 并且二进制日志不仅仅针对于 InnoDB 存储引擎,任何存储引擎都会产生二进制日志
- 两种日志记录的内容形式不同
- 二进制日志是一种逻辑日志,其记录的对应的 SQL 语句
- 重做日志是物理格式日志,其记录的是对于每个页的修改
- 两种日志记录写入磁盘的时间点不同
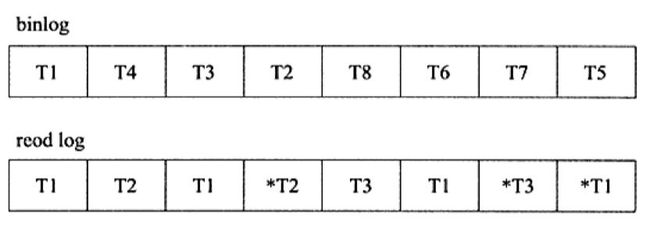
- 二进制日志只在事务提交完成后进行一次写入
- 重做日志再事务进行中不断地被写入,这表现为日志并不是随事务提交的顺序进行写入
- 重做日志在 InnoDB 存储引擎层产生,二进制日志是在 MySQL 数据库的上层产生的
-
-
-
undo
- 基本概念
- undo 主要用于进行回滚操作(将数据回滚到修改之前的样子
- undo 存放在数据库内部的一个特殊段(segement)中,这个段称为 undo 段(undo segment)
- undo 段位于共享表空间内
- undo 是逻辑日志,因此只是将数据库逻辑地恢复到原来的样子
- 数据库的主要任务就是协调对数据记录的并发访问
- 不能将一个页回滚到事务开始的样子,因为这样会影响其他事务正在进行的工作
- 栗子
- 执行一个 INSERT 10W 条记录的事务后,再执行 ROLLBACK 后,表空间的大小依然增大了
- 只是逻辑回滚,即执行了对应的 DELETE 语句,但申请的表空间不会回收
- 执行一个 INSERT 10W 条记录的事务后,再执行 ROLLBACK 后,表空间的大小依然增大了
- undo 的另外一个作用是 MVCC,即在 InnoDB 存储引擎中 MVCC 的实现是通过 undo 来完成
- 通过 undo 读取之前的行版本信息·,以此实现非锁定读取
- undo log 会产生 redo log,也就是 undo log 的产生会伴随着 redo log 的产生
- 基本概念
-
purge
- delete 和 update 操作可能并不直接删除原有的数据,真正删除行记录的操作是延时由 purge 完成的
- delete 和 update 只是将主键列的记录
delete flag设置为 1,即记录还是存在于 B+ 树中
- delete 和 update 只是将主键列的记录
- purge 用于最终完成 delete 和 update 操作
- 设计的目的是因为 InnoDB 存储引擎支持 MVCC,所以记录不能在事务提交时立即进行处理
- 若该行记录已不被任何其他事务引用,那么就可以进行真正的 delete 操作
- delete 和 update 操作可能并不直接删除原有的数据,真正删除行记录的操作是延时由 purge 完成的
事务控制语句
-
在 MySQL 命令行的默认设置下,事务都是自动提交(auto commit)的,即 SQL 执行后立即执行 COMMIT 操作
-
事务控制语句
- START TRANSACTION | BEGIN:显示地开启一个事务(存储过程中只能使用 START TRANSACTION
- COMMIT:提交事务,并使得已对数据库做的所有修改称为永久性的
- ROLLBACK:回滚会结束用户的事务,并撤销正在进行的所有未提交的修改
- SAVEPOINT identifier:允许在事务中创建一个保存点,一个事务中可以有多个 SAVEPOINT
- RELEASE SAVEPOINT identifier:删除一个事务的保存点(若未存在该保存点时,抛出异常
- ROLLBACK TO [SAVEPOINT]identifier:可以把事务回滚到标记点,而不回滚在此标记点之前的任何工作
- SET TRANSACTION:设置事务隔离级别
-
参数
completion_type配置对 COMMIT WORK 的影响参数值 影响 0 没有任何操作(默认值) 1 等同于 COMMIT AND CHAIN ,表示马上自动开启一个相同隔离级别的事务 2 等同于 COMMIT AND RELEASE ,表示在事务提交后会自动断开与服务器的连接 -
InnoDB 存储引擎中的事务都是原子的
- 构成事务的每条语句都会提交(成为永久),或者所有语句都回滚
- 因此一条语句失败并抛出异常时,并不会导致先前已执行的语句自动回滚,需用户自己决定是否回滚或提交
-
执行了 ROLLBACK TO SAVEPOINT 后需要显示地运行 COMMIT 或 ROLLBACK 命令才会起效
隐式提交的 SQL 语句
- 执行完以下这些语句后,会有一个隐式的 COMMIT 操作
- TRUNCATE TABLE 语句是 DDL,因此虽然和对整张表执行 DELETE 的结果是一样,但不能被回滚
对于事务操作的统计
- TPS(Transaction Per Second)每秒事务处理的能力
- 计算 TPS 的方法是:(com_commit+com_rollback)/time
- 前提:所有的事务必须都是显示提交的,若存在隐式地提交和回滚(默认 autocommit=1),则不会计算进去
- MySQL 数据库中另外还有两个参数 handler_commit 和 handler_rollback 用于事务的统计操作
- MySQL 5.1 中可以很好地用来统计 InnoDB 存储引擎显式和隐式的事务提交操作
事务的隔离级别
- SQL 标准定义的四个隔离级别
- READ UNCOMMITTED
- 浏览访问(browse access)
- READ COMMITTED
- 游标稳定(cursor stability)
- REPEATABLE READ
- 2.9999° 的隔离,没有幻读的保护
- SERIALIZABLE
- 3° 的隔离
- READ UNCOMMITTED
- SQL 和 SQL2 标准的默认事务隔离级别是 SERIALIZABLE
- InnoDB存储引擎默认支持的隔离级别是 REPEATABLE READ
- 但与标准 SQL 不同的是:通过使用 Next-Key Lock 锁的算法来避免幻读的产生
- 即 InnoDB 在默认的默认隔离级别下已经能完全保证事务的隔离性要求(达到 SQL 标准的 SERIALIZABLE 级别
- 在 SERIALIZABLE 的事务隔离级别,InnoDB 会对每个 SELECT 语句后自动加上
LOCK IN SHARE MODE,即共享读锁- 因此在此隔离级别下,读占用了锁,对一致性的非锁定读不再予以支持
- 此隔离级别复核数据库理论上的要求,即事务是
well-formed的,并且是two-phrased - SERIALIZABLE 的隔离级别主要用于 InnoDB 存储引擎的分布式事务
- 在 READ COMMITTED 的事务隔离级别下,除唯一性约束检查及外键约束检查需要 gap lock,其他情况都不会使用
分布式事务
- MySQL 数据库分布式事务
- InnoDB 存储引擎提供了对 XA 事务的支持,并通过 XA 事务来支持分布式事务的实现
- 分布式事务指的是允许多个独立的事务资源(Transactional resources)参与到一个全局的事务中
- 全局事务要求在其中的所有参与的事务要么都提交,要么都回滚,这对于事务原有的 ACID 要求又有了提高
- 在使用分布式事务时,InnoDB 存储引擎的事务隔离级别必须设置为 SERIALIZABLE
- XA 事务允许不同数据库之间的分布式事务
- 例如一台服务器是 MySQL,一台是 Orace,一台是 SQL Server 等,只要参与的每一个节点都支持 XA 事务
- XA 事务由一个或多个资源管理器、一个事务管理器以及一个应用程序组成
- 资源管理器:提供访问事务资源的方法(通常一个数据库就是一个资源管理器
- 事务管理器:协调参与全局事务中的各个事务(需要和参与全局事务的所有资源管理器进行通信
- 应用程序:定义事务的边界,指定全局事务中的操作
- 分布式事务模型图

- 分布式事务使用两段式提交(
two-phase commit)的方式- 第一阶段,所有参与全局事务的节点都开始准备(PREPATE),告诉事务管理器它们准备好提交了
- 第二阶段,事务管理器告诉资源管理器执行 ROLLBACK 还是 COMMIT
- 如果任何一个节点显示不能提交,则所有的节点都被告知需要回滚
- 内部 XA 事务
- 在 MySQL 中还存在另外一种分布式事务,其在存储引擎与插件之间,或存储引擎之间,称之为内部 XA 事务
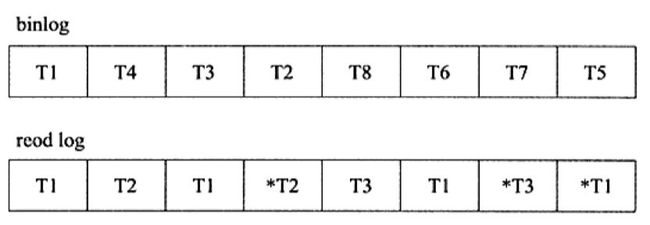
- 最常见的内部 XA 事务存在于 binlog 与 InnoDB 存储引擎之间
- 在事务提交时,先写二进制日志,再写 InnoDB 存储引擎的重做日志
- 对以上两个操作的要求也是原子的,即二进制日志和重做日志必须同时写入
- 若二进制日志写入完成后,再写入重做日志时发生宕机导致 replication 主从不一致的情况

- 为了解决这个问题,MySQL 数据库在 binlog 与 InnoDB 存储引擎之间采用 XA 事务

- 当事务提交时,InnoDB 存储引擎会先做一个 PREPARE 操作,将事务的 xid 写入
- 若在写入重做日志发生宕机,那么数据库在重启后会先检查 UXID 事务是否已经提交,若没,再一次提交
不好的事务习惯
- 在循环中提交
- 栗子:总共插入 1000 条 记录,A 选用遍历这1000条记录,循环中提交事务;B 将插入1000条放在一个事务中
- 因为每一次提交都要写一次重做日志,即 A 需要写入 1000次,而 B 只需要写入一次
- 有些人可能持有以下两种观点
- 在他们曾经使用过的数据库中,对事务的要求总是尽快地进行释放,不能有长时间的事务
- 可能担心存在 Oracle 中由于没有足够的 undo 产生的
Snapshot Too Old的经典问题 - MySQL 的 InnoDB 存储引擎没有上述两个问题,因此不管从任何角度出发,都不应该循环中提交事务
- 栗子:总共插入 1000 条 记录,A 选用遍历这1000条记录,循环中提交事务;B 将插入1000条放在一个事务中
- 使用自动提交
- MySQL 数据库设置使用自动提交,可以使用
SET autocommit = 0改变当前的自动提交方式 - 编写应用程序开发时,最好把事务的控制权限交给开发人员,即在程序端进行事务的开始和结束
- 同时,开发人员必须先了解自动提交可能带来的问题
- MySQL 数据库设置使用自动提交,可以使用
- 使用自动回滚
- InnoDB 存储引擎支持通过定义一个 HANDLER 来进行自动事务的回滚操作
- 如在一个存储过程中发生了错误会自动对其进行回滚操作
- 但自动回滚后,InnoDB 并不会像 SQL Server 那样把错误的异常抛出,导致问题没有最终被解决
- 对事务的 BEGIN、COMMIT 和 ROLLBACK 操作应该交给程序端来完成
- 用户可以得知发生错误的原因,并根据原因来进一步调试程序
- InnoDB 存储引擎支持通过定义一个 HANDLER 来进行自动事务的回滚操作
长事务
- 长事务(Long_Lived Transactions),顾名思义,就是执行时间较长的事务
- 针对长事务的问题,有时可以通过转化为小批量(mini batch)的事务来进行处理
- 当事务发生错误时,只需要回滚一部分数据,然后接着上次已完成的事务继续进行
- 通过将每个小事务完成的结果存放在 result 表中,可以在长事务的执行过程中,知道现在大概执行到了哪个阶段
- 需要注意的是,在开始执行小批量的事务时,需提交对影响的行记录加一个共享锁,防止其他事务更新数据