R语言实现SOM(自组织映射)模型(三个函数包+代码)
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~
———————————————————————————
笔者前言: 最近发现这个被发明于1982年的方法在如今得到了极为广泛的应用,在提倡深度学习的时候,基于聚类的神经网络方法被众多人青睐。但是呢, 网上貌似木有人贴出关于SOM模型的R语言实现,我就抛砖引玉一下。
一、SOM模型定义与优劣
自组织映射 ( Self Organization Map, SOM )神经网络是较为广泛应用于聚类的神经网络,它是由 Kohonen提出的一种无监督学习的神经元网络模型。
主要功能是将输入的 n 维空间数据映射到一个较低的维度 (通常是一维或者二维 )输出 ,同时保持数据原有的拓扑逻辑关系。
优劣:
(1)它不是以一个神经元或网络的状态矢量反映分类结果的 ,而是以若干神经元同时 (并行 )反映分类结果 .这种特征映射神经网络通过对输入模式的反复学习 ,使连接权矢量的空间分布能反映输入模式的统计特性。
(2)SOM 神经网络对于解决各类别特征不明显、特征参数相互交错混杂的、非线性分布的类型识别问题是非常有效的(客户行为的客户细分和分类研究也是相当有效的 ,因为客户行为识别本身也是一种复杂多变的问题)。
还不了解的童鞋,来带他们看一张图:

SOM模型与普通的神经网络模型相同的是有输入层、黑箱、输出层,
但是最大的区别就是在输出层,一般神经网络可能只是某几个点,而SOM在点基础上还加入了线(点与点之间的关系)。
具体的原理可自行baidu或者参考列出来的参考文献中,都有较为详细的说明。
二、SOM模型原理
同时该获胜神经元周围的一些神经元也因侧向相互作用而受到较大刺激,修改这些神经元和输入神经元之间的连接权值。
当输入模式发生变化时,输出层上获胜的输出神经元也发生改变。通过神经网络权值的调整,使得输出层特征分布能反映输入样本的分布情况。
据SOM模型的输出状态,不但能够判断输入模式所属的类别,并使得输出神经元代表某一模式类别,还能够得到整个数据区域的大体分布情况,即从样本数据中获得数据分布的大体本质特征。
某输入信号模式X=(x1,x2,…,xn)T连接到所有的输入神经元。输出神经元i与所有输入神经元之间连接的权向量为:Wi=(wi1,wi2,…,win)T。
输出神经元i的输出值oi:

1、初始化:随机选取某个较小的权值。各个输出神经元j的邻接输出神经元集合NEj的选取如图。NEj(t)表示在时刻t时输出单元j的邻接单元的集合,它是随时间的增长而不断缩小的。
2、输入: 输入单元接受一组新的输入X=(x1,x2,x3,...,xn)
3、计算输入X和每个输出神经元连接权向量Wj之间的距离dj

4、选择具有最小距离的输出神经元j*作为获胜结点。
5、调整输出神经元j*及其邻域Nej*(t)内的神经元所连接的权值向量。
6、假设样本输入和连接权值都是归一化的,则选择最小距离的神经元就是选择具有最大输出的神经元。
SOM模型的特征映射是一种有序的映射,因此它适合于进行特征提取和特征变换。
三、SOM模型的R语言实现——三个函数包介绍
SOM模型在R语言中,目前,我看到的有三个函数包,分别是:Kohonen包、som包、RSNNS包。
补充内容:
SOM的分类是否有意义?
答:木有,需要进行后续的分析,如客户细分中,还要继续计算每个群落的RFM值的均值,然后进行判断,可参考博客:
RFM模型及R语言实现
也可以用在离群值筛选中,可参考博客:RFM模型+SOM聚类︱离群值筛选问题
SOM如何合理地自定义分组数量?
答:笔者认为需要写一个循环语句,来验证一下,哪些组更好。
SOM是神经网络,能够载入训练、验证模型吗?
答:SOM,自组织映射网络是可以进行训练的,可以先用数据训练模型,然后验证其他数据。
——————————————————————————————————
1、som包
library(som)
#输入函数
som(data, xdim, ydim, init="linear", alpha=NULL, alphaType="inverse",
neigh="gaussian", topol="rect", radius=NULL, rlen=NULL, err.radius=1,
inv.alp.c=NULL)#结果分析函数
#foo$data源数据
#init 初始化方法
#xdim x的维数
#ydim y的维数
#code 初始矩阵行索引=x维度+y维度*x向量值(行)
#visual 每一案例,地图上的维数坐标 qerror是初始向量和最后测试向量的差的平方距离,这个就是分类
#alpha0 学习速率
#alpha 学习训练函数形式
#neigh 近邻函数类型
#topol 输出层近邻函数类型
#qerror 误差的平均
#code.sum xy的计数矩阵(类似混淆矩阵)
#som案例
data(yeast)
yeast <- yeast[, -c(1, 11)]
yeast.f <- filtering(yeast)
yeast.f.n <- normalize(yeast.f)
foo <- som(yeast.f.n, xdim=6, ydim=6)
foo <- som(yeast.f.n, xdim=5, ydim=6, topol="hexa", neigh="gaussian")
plot(foo)
names(foo)

因为最近使用了这个包,那么贴一些心得与技巧(更新于2016-10-28):
(1)标准化函数——normalize
聚类讲求数据需要标准化,那么som包自带标准化功能函数,
normalize(x, byrow=TRUE)默认byrow=T,按照行进行标准化,一般来说,都是按照列进行标准化。
(2)画图函数——plot
plot(x, sdbar=1, ylim=c(-3, 3), color=TRUE,
ntik=3, yadj=0.1, xlab="", ylab="", ...)其中上面的图就是plot出来的,那么基本上,plot(som,ylim=c(-3,3))是最基本的画图函数内容,其中SOM展示图代表啥意思呢?
代表每一个分块内容数据分布,如果标准化之后,一般(-3,3)就差不多了,当然你也可以自己设定成(-1,1)之类的内容,按照实际数据表现来定义。
(3)模型参数结果——summary
summary(som)
输出的结果是模型参数的类型,譬如使用了什么迭代函数,什么近邻函数,学习率以及总的平均误差率等指标。
(4)SOM模型的训练函数
som.train(data, code, xdim, ydim)这个函数没有试过,大致看了一下内容,跟som()大致一样,其中多出来一个code项,可能输入的是som之后整个模型,或者是som之后,其中som$code有一个code项目,应该二者选一。
——————————————————————————————————
2、kohonen包
这个包有人已经用来给白葡萄酒进行评分,可视化程序很高,比较适合做科研的包,粘贴一些细节,
完整请点击

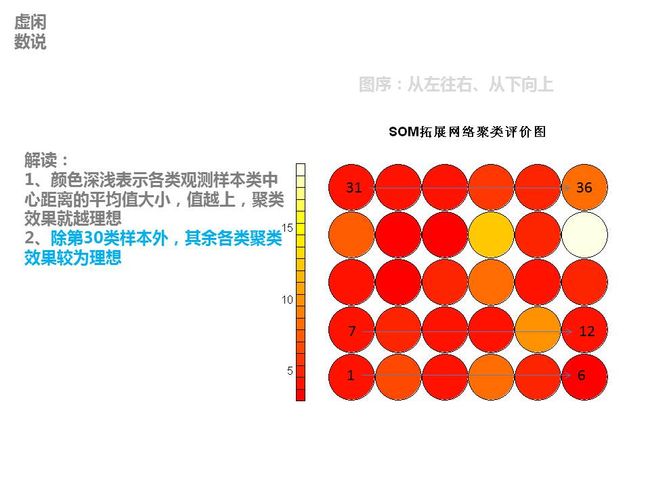
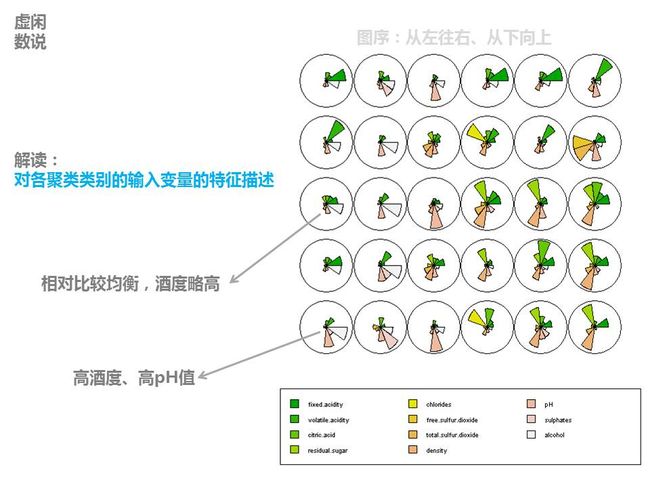
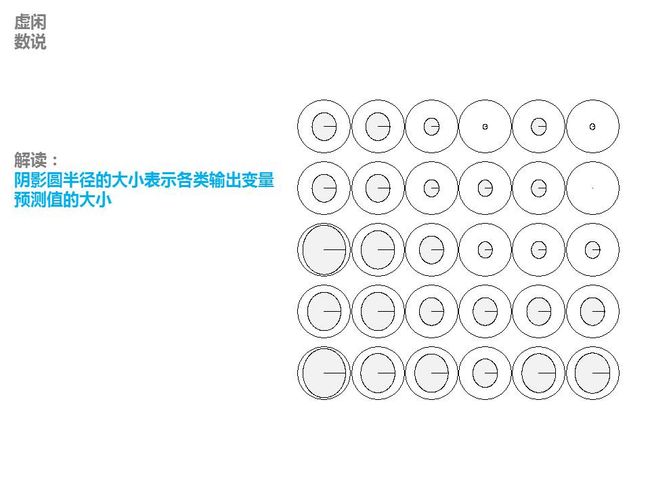

——————————————————————————————————
3、RSNNS包
号称做神经网络最强的包,这个包中有很多很神经网络方法,其他方面很值得研究。目前,国内没有看到特别好的关于这个包的应用案例。(包介绍参考点击)
包的介绍
R语言中已经有许多用于神经网络的package。例如nnet、AMORE以及neuralnet,nnet提供了最常见的前馈反向传播神经网络算法。AMORE包则更进一步提供了更为丰富的控制参数,并可以增加多个隐藏层。neuralnet包的改进在于提供了弹性反向传播算法和更多的激活函数形式。但以上各包均围绕着BP网络,并未涉及到神经网络中的其它拓扑结构和网络模型。而新出炉的RSNNS包则在这方面有了极大的扩充。
Stuttgart Neural Network Simulator(SNNS)是德国斯图加特大学开发的优秀神经网络仿真软件,为国外的神经网络研究者所广泛采用。其手册内容极为丰富,同时支持友好的 Linux 平台。而RSNNS则是连接R和SNNS的工具,在R中即可直接调用SNNS的函数命令。######RSNNS案例
library(RSNNS)
data(iris)
inputs <- normalizeData(iris[,1:4], "norm") #数据标准化
model <- som(inputs, mapX=16, mapY=16, maxit=500,
calculateActMaps=TRUE, targets=iris[,5])
par(mfrow=c(3,3))
for(i in 1:ncol(inputs)) plotActMap(model$componentMaps[[i]],
col=rev(topo.colors(12)))
plotActMap(model$map, col=rev(heat.colors(12)))
plotActMap(log(model$map+1), col=rev(heat.colors(12)))
persp(1:model$archParams$mapX, 1:model$archParams$mapY, log(model$map+1),
theta = 30, phi = 30, expand = 0.5, col = "lightblue")
plotActMap(model$labeledMap)
model$componentMaps
model$labeledUnits
model$map
names(model)
————————————————————————————————————————————————————————————
小技巧一:SOM聚类编码一则
一般SOM结果都是以两列,譬如0-3,0-3,我想变成一列,16个品类的聚类结果。那咋办呢?
之前还在想,要不直接用Ifelse来写,不过想想写这个好头疼,于是乎想了想,可以这样:
之前是:

把其中一列(0,1,2,3)*4=(0,4,8,12)
然后加到原来那列就可以完成依次编码的要求了。
————————————————————————————————————————
应用一:SOM与Kmeans的关系
更一般地说,SOM应该是一个降维算法,它可以将高维的数据投影到节点平面上,实现高维数据可视化,然后也可以继续根据降维之后的数据再进行聚类,就像谱聚类一样。
对于每一个输入的数据点,网络节点都要进行竞争,最后只有一个节点获胜。获胜节点会根据赢得的数据点进行演化,变得与这个数据点更匹配。如果数据可以明显地分为多个cluster,节点变得跟某个cluster内的数据点更为匹配,一般而言就会跟其它cluster不太匹配,这样其它节点就会赢得了其它cluster的数据点。如此反复学习,每个节点就会变得只跟特定的一个cluster匹配,这样就完成了数据点的聚类。
SOM需要输入数据点的坐标矩阵,对应的,每个网络节点也有一个坐标,初始时刻随机赋值。每次输入一个数据点,与这个数据距离最近的节点获胜,获胜点的坐标向着这个数据点的方向偏移。聪明的看官们肯定发现了,这个简单化的SOM算法跟K-means算法思路基本一致,确实一些文章也提到,在节点数目偏少的情况下SOM的结果就类似于K-means。
参考博文:http://blog.csdn.net/u013524655/article/details/40893191
————————————————————————————————————————
可参考以下文献:
1、自组织映射神经网络_SOM_在客户分类中的一种应用_陈伯成
2、基于RFM分析的银行信用卡客户的_省略_经网络SOM和Apriori方法_梁昌勇
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~
———————————————————————————