在阿里云上搭建Elasticsearch7.6集群,并用python操作es集群
在阿里云上搭建Elasticsearch7.6集群,并用python操作es集群
- 一安装elasticsearch7.6
- 二集群搭建
- 三python操作es集群
一安装elasticsearch7.6
1.下载es安装包并解压,在 https://www.newbe.pro/Mirrors/Mirrors-Elasticsearch/ 可以下载加速
2.创建一个普通用户,并把解压后的es文件夹完全赋权给普通用户
3.对服务器系统进行配置,并且放开9200和9300端口
(1)vim /etc/sysctl.conf
在文件末尾追加:vm.max_map_count=655360
保存设置之后在命令行输入 sysctl -p
(2)vim /etc/security/limits.conf
65535修改为65536
(3)vim /etc/security/limits.d/20-nproc.conf
修改
* soft nproc 1024
为
* soft nproc 4096
- elasticsearch 设置
切换到elasticsearch安装文件夹下的config文件夹内
(1)vim jvm.options
-Xms256m
-Xmx256m
这俩数值分别代表JVM堆的初始值和最大值,大小不要超过可用好内存的一半
还是在config文件夹内
(2)vim elasticsearch.yml
network.host: 0.0.0.0 # 允许外部访问
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
cluster.initial_master_nodes: ["node-1"]
保存相关配置,退出服务器,重新登录服务器。使用普通用户在elasticsearch根目录执行 bin/elasticsearch
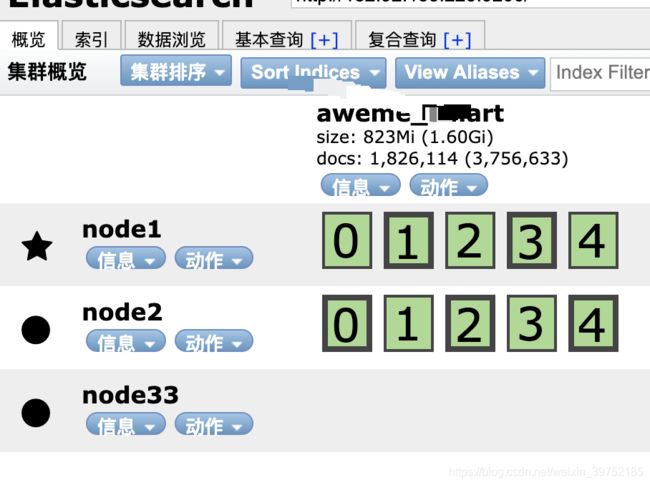
二集群搭建
配置集群主要修改elasticsearch.yml配置文件
我这边是使用三台服务器,每台服务器部署一个elasticsearch。
node1节点配置
cluster.name: shadou # 同一个集群的名称必须一致
node.name: node1 # 节点名称
node.master: true # 是否作为主节点
node.data: true # 是否会存储数据
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300 # 9300端口必须可以正常访问
discovery.seed_hosts: ["node1ip:9300","node2ip:9300","node3ip:9300"]
cluster.initial_master_nodes: ["node1", "node2","node33"]
http.cors.enabled: true
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
node2节点配置
cluster.name: shadou
node.name: node2
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["node1ip:9300","node2ip:9300","node3ip:9300"]
cluster.initial_master_nodes: ["node1", "node2","node33"]
http.cors.enabled: true
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
node33节点配置
cluster.name: shadou
node.name: node33
node.master: true
node.data: False
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["node1ip:9300","node2ip:9300","node33ip:9300"]
cluster.initial_master_nodes: ["node1", "node2","node33"]
http.cors.enabled: true
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
动态添加节点时,要保证elasticsearch里面的data文件夹是干净的,否则添加节点会失败
分别启动三个服务器上的elasticsearch。第一个先启动的会作为主节点
三python操作es集群
现在用python操作es我是使用 elasticsearch 这个库,直接手写需要执行body体,进行传参即可
from elasticsearch import Elasticsearch
es_client = Elasticsearch([{
'host': "ip1", 'port': 9200}, {
'host': "ip2", 'port': 9200}, {
'host': "ip3", 'port': 9201}], timeout=3600)
body =
{
"query": {
"bool": {
"filter": {
"terms": {
"_id": aweme_id_list}
}
}
},
"sort": {
"video_like": {
"order": "desc"}},
"from": start,
"size": size
}
data = es_client.search(body=body, index=es的index)