android代码.rc文件结构解析
一、.rc文件结构介绍
.rc文件基本组成单位是section, section分为三种类型,分别由三个关键字(所谓关键字即每一行的第一列)来区分,这三个关键字是on、service、import。

on类型的section表示一系列命令的组合,命令的执行是以section为单位的,所以这on下面的命令是一起执行的,不会单独执行, 那什么时候执行呢? 这是由init.c的main()所决定的,main()里在某个时间会调用
action_for_each_trigger("init", action_add_queue_tail);
这就把on init开始的这样一个section里的所有命令加入到一个执行队列,在未来的某个时候会顺序执行队列里的命令,所以调用action_for_each_trigger的先后决定了命令执行的先后。
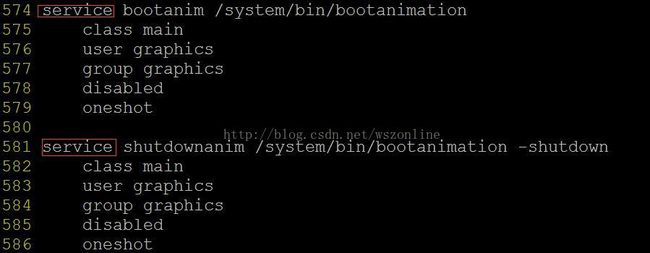
service类型的section表示一个可执行程序,bootanim作为一个名字标识了这个service, /system/bin/bootanimation表示可执行文件的位置, class、user、group等这些关键字所对应的行都被称为options, options是用来描述的service一些特点,不同的service有着不同的options。service类型的section标识了一个service(或者说可执行程序), 那这个service什么时候被执行呢?是在class_start这个命令被执行的时候或者在代码中使用setprop时,class_start命令行总是存在于某个on类型的section中,“class_start core”这样一条命令被执行,就会启动类型为core的所有service。
所以可以看出android的启动过程主要就是on类型的section被执行的过程。
import类型的section表示引入另外一个.rc文件,例如:
import /init.usb.rc
相当包含另外一些section, 在解析完.rc文件后继续会调用init_parse_config_file来解析引入的.rc文件。
二、.rc文件解析过程
由上述可知,解析.rc的过程就是识别一个个section的过程,将各个section的信息保存下来,然后在init.c的main()中去执行一个个命令。android采用双向链表来存储section的信息,解析完成之后,会得到三个双向链表action_list、service_list、import_list来分别存储三种section的信息上。
1、init.c中调用init_parse_config_file(“/init.rc”), 代码如下:
int init_parse_config_file(const char *fn)
{
char *data;
data = read_file(fn, 0); //read_file()调用open\lseek\read 将init.rc读出来
if (!data) return -1;
parse_config(fn, data); //调用parse_config开始解析
DUMP();
return 0;
}
2、parse_config()代码如下:
static void parse_config(const char *fn, char *s)
{
struct parse_state state;
struct listnode import_list;
struct listnode *node;
char *args[INIT_PARSER_MAXARGS];
int nargs;
nargs = 0;
state.filename = fn;
state.line = 0;
state.ptr = s;
state.nexttoken = 0;
state.parse_line = parse_line_no_op;
list_init(&import_list);
state.priv = &import_list;
for (;;) {
switch (next_token(&state)) { //next_token()根据从state.ptr开始遍历
case T_EOF: //遍历到文件结尾,然后goto解析import的.rc文件
state.parse_line(&state, 0, 0);
goto parser_done;
case T_NEWLINE: //到了一行结束
state.line++;
if (nargs) {
int kw = lookup_keyword(args[0]); //找到这一行的关键字
if (kw_is(kw, SECTION)) { //如果这是一个section的第一行
state.parse_line(&state, 0, 0);
parse_new_section(&state, kw, nargs, args);
} else { //如果这不是一个section的第一行
state.parse_line(&state, nargs, args);
}
nargs = 0;
}
break;
case T_TEXT: //遇到普通字符
if (nargs < INIT_PARSER_MAXARGS) {
args[nargs++] = state.text;
}
break;
}
}
parser_done:
list_for_each(node, &import_list) {
struct import *import = node_to_item(node, struct import, list);
int ret;
INFO("importing '%s'", import->filename);
ret = init_parse_config_file(import->filename);
if (ret)
ERROR("could not import file '%s' from '%s'\n",
import->filename, fn);
}
}
next_token() 解析完init.rc中一行之后,会返回T_NEWLINE,这时调用lookup_keyword函数来找出这一行的关键字, lookup_keyword返回的是一个整型值,对应keyword_info[]数组的下标,keyword_info[]存放的是keyword_info结构体类型的数据
struct {
const char *name; //关键字的名称
int (*func)(int nargs, char **args); //对应的处理函数
unsigned char nargs; //参数个数
unsigned char flags; //flag标识关键字的类型,
//包括COMMAND、OPTION、SECTION
} keyword_info
因此keyword_info[]中存放的是所有关键字的信息,每一项对应一个关键字。
根据每一项的flags就可以判断出关键字的类型,如新的一行是SECTION,就调用parse_new_section()来解析这一行, 如新的一行不是一个SECTION的第一行,那么调用state.parseline()来解析(state.parseline所对应的函数会根据section类型的不同而不同),在parse_new_section()中进行动态设置。三种类型的section: service、on、import, service对应的state.parseline为parse_line_service,on对应的state.parseline为parse_line_action, import section中只有一行所以没有对应的state.parseline。