Netty ByteBuf源码解读
Netty里的ByteBuf主要用于发送或接收消息。在JDK里有相似功能的类java.nio.ByteBuffer。由于JDK在设计ByteBuffer API的时候对用户不太友好,主要表现在1:写读切换的时候需要调用flip方法。2:初使化的时候长度便固定了,没有提供自动扩容的功能。而Netty在设计ByteBuf的时候考虑到API在使用上的便利,对上面提到的两个问题很好的进行了规避。
java.nio.ByteBuffer源码解读
先来了解一下jdk自带的ByteBuffer是如何实现的,有利于我们看Netty里ByteBuf的源码。在jdk里对基本的数据类型都提供了相应的Buffer进行数据的读取(除了boolean)。下图很好的看出除boolean外的Buffer继承关系:
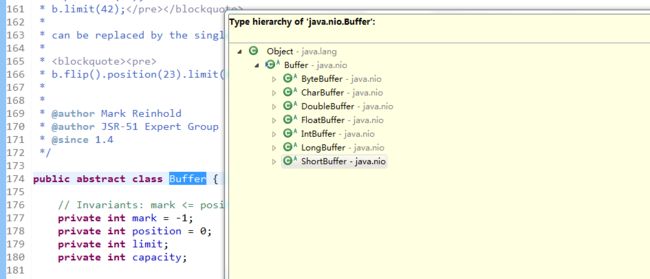
首先来看一下Buffer类的源码,这里面实现了一些公共的方法,比如刚刚提到的flip()方法。在Buffer里维护了四个属性,分别为mark, position, limit, capacity;他们之前的关系 是
mark<=position<=limit<=capacity;其中mark属性用于执行些与mark相关的操作,主要用于标识位置来实现重复读取功能。部分源码如下:
public abstract class Buffer {
// Invariants: mark <= position <= limit <= capacity
private int mark = -1;
private int position = 0;
private int limit;
private int capacity;
Buffer(int mark, int pos, int lim, int cap) { // package-private
if (cap < 0)
throw new IllegalArgumentException("Negative capacity: " + cap);
this.capacity = cap;
limit(lim);
position(pos);
if (mark >= 0) {
if (mark > pos)
throw new IllegalArgumentException("mark > position: ("
+ mark + " > " + pos + ")");
this.mark = mark;
}
}
/**
这个就是flip方法的实现。Buffer类实现读写用同一个Buffer的核心方法就是需要调用这个方法,其实也就是将读写的标识位进行换一下。
**/
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
//用于移动position操作
final int nextGetIndex() { // package-private
if (position >= limit)
throw new BufferUnderflowException();
return position++;
}
}
ByteBuffer通过继承Buffer类有了一些公共的方法,从内存分配的位置来分类可以分为:
1)堆内存(HeapByteBufer),特点:分配与回收比较快,在socket传输的过程中多了一次内存复制。
2)直接内存(DirectByteBufer),特点:分配与回收相对比较慢,但在socket数据传输中少了内存复制。
所以在ByteBuffer里也只提供了一些通用的公共方法,具体的存储还是留给子类来实现,部分源码如下:
public abstract class ByteBuffer
extends Buffer
implements Comparable
{
//用于存数据的数组 这里只定义了引用
final byte[] hb; // Non-null only for heap buffers
final int offset;
boolean isReadOnly; // Valid only for heap buffers
/**
调用这个方法可以将src里的数据往hb里放
**/
public final ByteBuffer put(byte[] src) {
return put(src, 0, src.length);
}
/**
这个方法会将src里的数据从offset到length的数据放入到hb里
**/
public ByteBuffer put(byte[] src, int offset, int length) {
checkBounds(offset, length, src.length);
if (length > remaining())
throw new BufferOverflowException();
int end = offset + length;
for (int i = offset; i < end; i++)
this.put(src[i]);
return this;
}
//具体怎么放的留给子类来实现
public abstract ByteBuffer put(byte b);
//将ByteBuffer里的数据往dst里填充
public ByteBuffer get(byte[] dst) {
return get(dst, 0, dst.length);
}
//具体的填充调用这个方法,需要传入填充的开始和结束位置
public ByteBuffer get(byte[] dst, int offset, int length) {
checkBounds(offset, length, dst.length);
if (length > remaining())
throw new BufferUnderflowException();
int end = offset + length;
for (int i = offset; i < end; i++)
dst[i] = get();
return this;
}
//留给子类来实现,不同的内存类型采用不同的方式
public abstract byte get();
}
下面来看看堆内存是如何实现上面的put与get方法的
class HeapByteBuffer
extends ByteBuffer
{
//这个构造方法传入的hb是new byte[cap]
HeapByteBuffer(int cap, int lim) { // package-private
super(-1, 0, lim, cap, new byte[cap], 0);
}
//往byte数组里放数据的方法就是这个啦,nextPutIndex用于移动position位置,而ix用于根据offset找到具体的位置放数据,这里的offset是ByteBuffer内部的offset.
public ByteBuffer put(byte x) {
hb[ix(nextPutIndex())] = x;
return this;
}
protected int ix(int i) {
return i + offset;
}
//取数据与存数据是一样的,都需要通过position确定数据的位置,这就是为什么jdk自带的Buffer需要调用flip()方法对position位置做转换啦。
public byte get() {
return hb[ix(nextGetIndex())];
}
}
上面的代码分析了jdk里ByteBuffer类的实现原理,通过分析ByteBuffer再来看Netty里ByteBuff的源码就更简单了。
ByteBuf源码解读
Netty实现自已的ByteBuf是基于jdk自带的ByteBuffer有我们上面所说的两个缺点。Netty通过多加一个变量就解决了写读转换城要调用flip方法的问题,而通过自动扩容解决了ByteBuffer大小固定的问题。下面我们来看看Netty是如何实现的,首先看主要的类关系图如下:

在这里就没有七种基本类型的Buffer啦,但是在ByteBuf里提供了对应的方法来实现写入与读出不同类型的数据。从这个类图上我们也可以看出不但对内存类型分为DirectByteBuf与HeapByteBuf。也分为Pooled与Unpooled。ByteBuf只定义了一些方法,具体的实现通过模板方法模式,将通用的方法在AbstractByteBuf类中实现。下面来看一下AbstractByteBuf里的部分源码:
public abstract class AbstractByteBuf extends ByteBuf {
//这个是读到的位置
int readerIndex;
//这个是写到的位置
int writerIndex;
//标记读位置,用于resetReaderIndex方法
private int markedReaderIndex;
//标记写位置,用于resetWriterIndex
private int markedWriterIndex;
//当前ByteBuf的最大内存
private int maxCapacity;
//构造方法,只需要传入可用的最大内存参数
protected AbstractByteBuf(int maxCapacity) {
if (maxCapacity < 0) {
throw new IllegalArgumentException("maxCapacity: " + maxCapacity + " (expected: >= 0)");
}
this.maxCapacity = maxCapacity;
}
}
AbstractByteBuf方法分为以下以内,下面分别进行源码的注释:
- 写类型的方法,比如writeInt方法,源码如下:
public abstract class AbstractByteBuf extends ByteBuf {
//写入一个int类型的数据
@Override
public ByteBuf writeInt(int value) {
//确定能够写入4个字节大小的数据,如果写入不了,这个方法会进行扩容或者抛出异常
ensureWritable0(4);
//根据writerIndex,将数据写到到指定位置
_setInt(writerIndex, value);
//writerIndex 往后移4位
writerIndex += 4;
return this;
}
/**
*这个方法用于保证能够写入最小minWritableBytes个字节的数据
**/
final void ensureWritable0(int minWritableBytes) {
ensureAccessible();
//如果当前的容量足够写入的,则直接返回
if (minWritableBytes <= writableBytes()) {
return;
}
//超过设置的最大容最,那就直接抛出异常,这种情况不会进行扩容了
if (minWritableBytes > maxCapacity - writerIndex) {
throw new IndexOutOfBoundsException(String.format(
"writerIndex(%d) + minWritableBytes(%d) exceeds maxCapacity(%d): %s",
writerIndex, minWritableBytes, maxCapacity, this));
}
//在这里会进行扩容处理,并返回扩容后的大小
// Normalize the current capacity to the power of 2.
int newCapacity = alloc().calculateNewCapacity(writerIndex + minWritableBytes, maxCapacity);
//调整newCapacity 进行扩容
// Adjust to the new capacity.
capacity(newCapacity);
}
}
下面来看看Netty里是如何调整需要扩容ByteBuf的大小的。逻辑在AbstractByteBufAllocator 类里源码如下:
public abstract class AbstractByteBufAllocator implements ByteBufAllocator {
// 计算需要扩容的大小
@Override
public int calculateNewCapacity(int minNewCapacity, int maxCapacity) {
// 验证参数的合法性
if (minNewCapacity < 0) {
throw new IllegalArgumentException("minNewCapacity: " + minNewCapacity + " (expected: 0+)");
}
if (minNewCapacity > maxCapacity) {
throw new IllegalArgumentException(String.format(
"minNewCapacity: %d (expected: not greater than maxCapacity(%d)",
minNewCapacity, maxCapacity));
}
//CALCULATE_THRESHOLD这里是个常量,4M
final int threshold = CALCULATE_THRESHOLD; // 4 MiB page
if (minNewCapacity == threshold) {
return threshold;
}
// If over threshold, do not double but just increase by threshold.
//如果需要写入数据的Buffer已经超过4M大小了,这时会分配4M大小的容量空间,但是不会超过最在允许的maxCapacity
if (minNewCapacity > threshold) {
int newCapacity = minNewCapacity / threshold * threshold;
if (newCapacity > maxCapacity - threshold) {
newCapacity = maxCapacity;
} else {
newCapacity += threshold;
}
return newCapacity;
}
// Not over threshold. Double up to 4 MiB, starting from 64.
//小于4M的话以64比特进行翻倍扩容
int newCapacity = 64;
while (newCapacity < minNewCapacity) {
newCapacity <<= 1;
}
return Math.min(newCapacity, maxCapacity);
}
}
上面的注释很清晰的描述了如何确定扩容的大小。下面来看一下确定大小后又是如何扩容的呢,可以肯定不同的内存类型有不同的扩容方式,我还还是看一下堆内存的扩容方式吧,源码如下:
public class UnpooledHeapByteBuf extends AbstractReferenceCountedByteBuf {
/**
**这个方法里会根据 newCapacity进行具体的扩容,其实也就是对原有的数据进行复制
**/
@Override
public ByteBuf capacity(int newCapacity) {
//验证传入参数的合法性
checkNewCapacity(newCapacity);
int oldCapacity = array.length;
byte[] oldArray = array;
if (newCapacity > oldCapacity) {
//这里首先分配块byte[]大小的内存
byte[] newArray = allocateArray(newCapacity);
//采用System.arraycopy方法进行数据的复制
System.arraycopy(oldArray, 0, newArray, 0, oldArray.length);
//将新的arry设置成原来的array对象
setArray(newArray);
//释放老的array对象
freeArray(oldArray);
} else if (newCapacity < oldCapacity) {
//下面是缩容的逻辑啦,缩容需要考虑的更多,读写指向的位置需要调整
byte[] newArray = allocateArray(newCapacity);
int readerIndex = readerIndex();
if (readerIndex < newCapacity) {
int writerIndex = writerIndex();
if (writerIndex > newCapacity) {
writerIndex(writerIndex = newCapacity);
}
System.arraycopy(oldArray, readerIndex, newArray, readerIndex, writerIndex - readerIndex);
} else {
setIndex(newCapacity, newCapacity);
}
setArray(newArray);
freeArray(oldArray);
}
return this;
}
}
写的方法我们分析到这里,从源码分析上看,在具体应用ByteBuf的时候最后能对ByteBuf的大小有一个预估。必竟扩容的方法还是很耗性能的。
- 读方法,比如readInt方法,源码如下:
public abstract class AbstractByteBuf extends ByteBuf {
@Override
public int readInt() {
//保证有数据可读,这里有很简单了,主要判断一下readerIndex与writerIndex之间的差是不是比4小
checkReadableBytes0(4);
//_getInt方法肯定是由子类来实现的啦,传入的是读数据的开始位置
int v = _getInt(readerIndex);
//读指示位往生移4位
readerIndex += 4;
//返回读到的数据
return v;
}
//这里验证传入的数据,保证操作的安全
private void checkReadableBytes0(int minimumReadableBytes) {
ensureAccessible();
if (readerIndex > writerIndex - minimumReadableBytes) {
throw new IndexOutOfBoundsException(String.format(
"readerIndex(%d) + length(%d) exceeds writerIndex(%d): %s",
readerIndex, minimumReadableBytes, writerIndex, this));
}
}
}
- 清空读过的数据,以重复利用存储空间,通过discardReadBytes方法来实现源码如下:
public abstract class AbstractByteBuf extends ByteBuf {
@Override
public ByteBuf discardReadBytes() {
ensureAccessible();
//通过readerIndex 判断如果没有读过的数据,则直接返回
if (readerIndex == 0) {
return this;
}
if (readerIndex != writerIndex) {
//读写位置不一样时的处理逻辑,将byte数据进行移位操作,由不同的子类来实现
setBytes(0, this, readerIndex, writerIndex - readerIndex);
//重置writerIndex
writerIndex -= readerIndex;
//重置markedReaderIndex 与markedWriterIndex
adjustMarkers(readerIndex);
//readerIndex 变成0
readerIndex = 0;
} else {
adjustMarkers(readerIndex);
writerIndex = readerIndex = 0;
}
return this;
}
}
堆内存的移位操作源码如下:
public class UnpooledHeapByteBuf extends AbstractReferenceCountedByteBuf {
@Override
public ByteBuf setBytes(int index, ByteBuf src, int srcIndex, int length) {
//验证传入的参数
checkSrcIndex(index, length, srcIndex, src.capacity());
if (src.hasMemoryAddress()) {
PlatformDependent.copyMemory(src.memoryAddress() + srcIndex, array, index, length);
} else if (src.hasArray()) {
//这里通过下面的方法,内部还是调用System.arraycopy方法
setBytes(index, src.array(), src.arrayOffset() + srcIndex, length);
} else {
src.getBytes(srcIndex, array, index, length);
}
return this;
}
@Override
public ByteBuf setBytes(int index, byte[] src, int srcIndex, int length) {
checkSrcIndex(index, length, srcIndex, src.length);
System.arraycopy(src, srcIndex, array, index, length);
return this;
}
}
ByteBuf是如何处理引用计数
Netty里通过池技术来重复利用ByteBuf对象,而池必然涉及到回何回收对象,Netty通过对ByteBuf增加一个计数器来实现对无引用对象的回收。源码如下:
public abstract class AbstractReferenceCountedByteBuf extends AbstractByteBuf {
//这个对象就有意思了,这个对象内部通过cas的操作保证修改的安全性。
private static final AtomicIntegerFieldUpdater refCntUpdater =
AtomicIntegerFieldUpdater.newUpdater(AbstractReferenceCountedByteBuf.class, "refCnt");
//增加引用计数的属性,将这个值设为volatile保证各线程在并发访问的时候可见性
private volatile int refCnt;
//通过retain方法将引用计数加一
@Override
public ByteBuf retain() {
return retain0(1);
}
@Override
public ByteBuf retain(int increment) {
return retain0(checkPositive(increment, "increment"));
}
private ByteBuf retain0(final int increment) {
int oldRef = refCntUpdater.getAndAdd(this, increment);
if (oldRef <= 0 || oldRef + increment < oldRef) {
// Ensure we don't resurrect (which means the refCnt was 0) and also that we encountered an overflow.
refCntUpdater.getAndAdd(this, -increment);
throw new IllegalReferenceCountException(oldRef, increment);
}
return this;
}
//通过relaese方法将引用计数进行减操作
@Override
public boolean release() {
return release0(1);
}
@Override
public boolean release(int decrement) {
return release0(checkPositive(decrement, "decrement"));
}
private boolean release0(int decrement) {
//refCntUpdater的getAndAdd能够保证操作的原子性,
int oldRef = refCntUpdater.getAndAdd(this, -decrement);
if (oldRef == decrement) {
deallocate();
return true;
} else if (oldRef < decrement || oldRef - decrement > oldRef) {
// Ensure we don't over-release, and avoid underflow.
refCntUpdater.getAndAdd(this, decrement);
throw new IllegalReferenceCountException(oldRef, -decrement);
}
return false;
}
//这个方法用于释放当前ByteBuf空间啦
/**
* Called once {@link #refCnt()} is equals 0.
*/
protected abstract void deallocate();
}