计算引擎Spark
计算引擎Spark
一、Spark主要特点
1.性能高效
- 内存计算引擎:Spark允许用户将数据放到内存中以加快数据读取,进而提高数据处理性能。
- 通用DAG计算引擎:Spark可以使得数据通过本地磁盘或内存流向不同计算单元而不是像MapReduce那样借助低效的HDFS。
- 性能高效:Spark是在MapReduce基础上产生的,在相同资源消耗的情况下,Spark比MapReduce快几倍到几十倍。
2.简单易用
Spark提供了丰富的高层次的API,包括sortByKey、groupByKey等。实现相同功能模块,Spark比MapReduce少2~5倍。
3.与Hadoop完好集成
Hadoop以及成为大数据标准解决方案,设计数据收集、数据存储、资源管理以及分布式计算等一系列系统。Spark作为新型计算框架,定位为除MapReduce等引擎之外的另一种可选的数据分析引擎,可以与Hadoop进行完好集成,可以与MapReduce等类型的应用一起运行在YARN集群,读取存储在HDFS/HBase中的数据,并写入各种存储系统中。

二、Spark程序基本框架
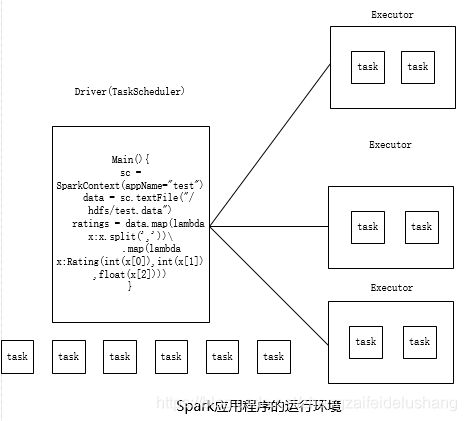
每个Spark应用程序的运行时环境是由一个Driver进程和多个Executor进程构成的,运行在不同的机器上(也可能其中几个运行在同一个机器上,具体取决于资源调度器的调度算法),并通过网络相互通信。
Driver进程运行用户程序(main函数),并依次经历逻辑计划生成、物理计划生成、任务调度等阶段后,将任务分配到各个Executor上执行;Executor进程是拥有独立计算资源的JVM实例,其内部以线程方式运行Driver分配的任务。
如下图所示:展示了一个Spark应用程序的运行环境,该应用程序由1个Driver和3个Executor(可能分布到不同节点上)构成,每个Executor内部可同时运行4个任务。
Spark程序设计流程一般如下:
- 实例化SparkContext对象:SparkContext封装了程序运行上下文环境,包括配置信息、数据块管理器、任务调度器等;
- 构造RDD:可通过SparkContext提供的函数构造RDD。
- 在RDD基础上,通过Spark提供的transformation算子完成数据处理逻辑。
- 通过action算子将最终RDD作为结果直接返回或者保存到文件中。
三、Spark运行模式
每个Spark程序由一个Driver和多个Executor组成,它们之间通过网络通信。用户可将程序的Driver和Executor两类进程运行在不同类型的系统中,进而产生了多种运行模式。
Spark支持的运行模式包括:
1)local:本地模式,将Driver与Executor均运行在本地,方便调试。用户可根据需求设置多个Executor,而Executor本身则以线程方式运行。
2)standalone:standalone是指由一个master和多个slave服务组成的Spark独立集群运行环境,而Spark应用程序的Driver与Executor则运行在该集群环境中。
根据Driver是否运行在Spark独立集群中,可进一步将之分为client和cluster两种模式:
- client模式:Driver运行在客户端,不受master管理和控制,但Executor运行在slave上,受master管理和控制
- cluster模式:Driver和Executor均运行在slave上。
3)YARN:将Hadoop YARN作为资源管理和调度系统,让Spark程序运行在YARN之上。根据Driver是否由YARN管理,可进一步分为yarn-client和yarn-cluster两种模式:
- yarn-client:Driver运行在客户端,不受YARN管理和控制,但Executor运行在YARN Container中。
- yarn-cluster:Driver和Executor均运行在YARN Container中,受YARN管理和控制。
注意:Spark On YARN与Spark On Standalone Cluster的区别:YARN是一个通用的资源管理平台,可以同时混合运行MapReduce、Spark等应用程序,而Standalone集群是为Spark应用程序专门打造的,不能运行除Spark之外的其他的应用程序。
四、Stanalone模式
Spark自带了基于master/slave架构的分布式运行环境,master只有一个,负责集群中资源的管理和任务的调度,slave可以有多个,负责运行Spark应用程序的Driver或Executor。根据Driver是否运行在Spark集群中,可进一步将之分为client和cluster两种模式。
1.client模式
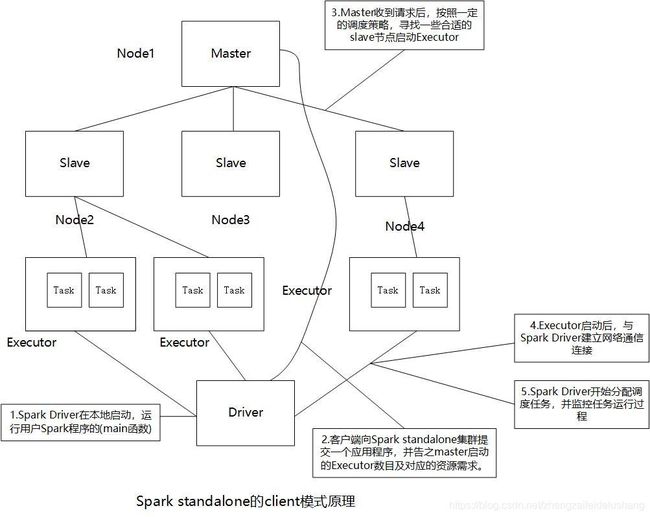
在client模式中,Spark Driver运行在客户端(客户端和Driver位于同一JVM中),而Executor运行在slave中,该模式便于程序的调试(main函数运行在客户端),task任务运行在slave上的Executor中。
一个Spark应用程序以client模式运行在standalone集群中的流程如下:
1)用户在Spark客户端机器上运行程序,Spark Driver在本地启动,可以理解为在本机运行用户Spark程序,运行用户程序的(main函数)。
2)客户端向Spark standalone集群提交一个应用程序,并告之启动的Executor数目及对应的资源需求。
3)Master收到请求后,按照一定的调度策略,找一些合适的slave节点启动Executor。
4)Executor启动后,与Spark Driver建立网络通信连接。
5)Spark Driver开始分配和调度任务,并监控任务运行过程(失败会重新调度),直到所有任务运行完毕,应用程序退出。
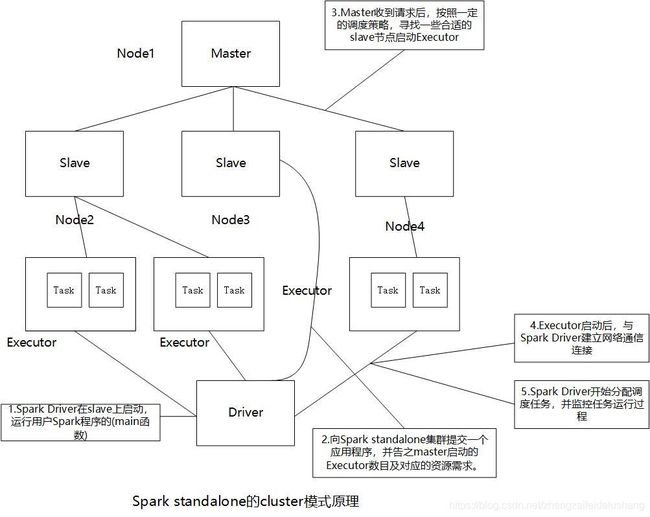
2.cluster模式
在cluster模式中,Spark Driver和Executor均运行在slave上,受Spark master和slave的管理。在该模式下,Driver和Executor均具备良好的容错性,一旦因故障退出后,Master会重新分配资源并将之启动起来。
五、YARN模式
YARN是Hadoop中的资源管理和调度系统,能够对其上的各类应用程序进行统一管理和调度。Spark可直接运行在YARN上,根据Driver是否由YARN管理,可将Spark On YARN运行模式分为两种:yarn-client和yarn-cluster。
1.yarn-client
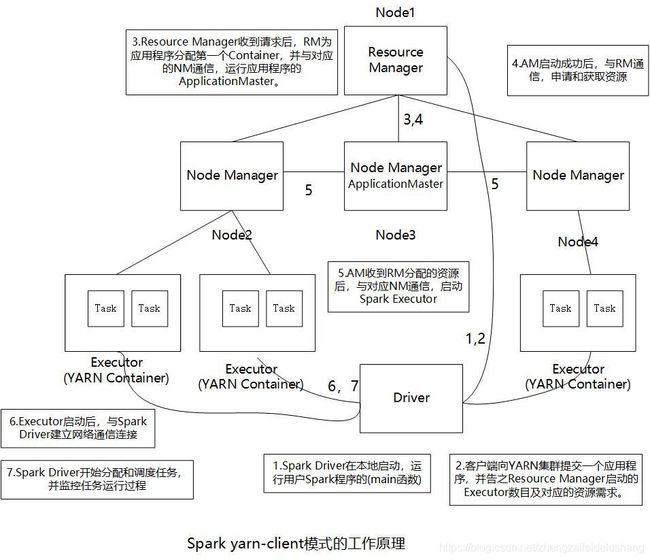
在yarn-client模式中,Spark-driver运行在客户端(两者位于同一JVM中),而Executor运行在YARN Container中。该模式便于程序的调试,但因Driver不受YARN管理,因此Driver本身不具备容错特性。
一个Spark应用程序以yarn-client模式运行在YARN集群中的流程如下:
1)用户在Spark客户端机器上运行程序,Spark Driver在本地启动。
2)客户端向YARN集群提交一个应用程序,并告之启动的Executor数目以及每个Executor需要的资源等信息。
3)ResourceManager收到请求后,ResourceManager为应用程序分配第一个Container,并与对应的NodeManager通信,运行应用程序的ApplicationMaster。
4)ApplicationMaster启动成功后,与ResourceManager通信,申请和获取资源。
5) ApplicationMaster收到ResourceManager分配的资源后,与对应的NodeManager通信,启动Spark Executor。
6) Executor启动后,与Spark Driver建立网络通信连接。
7)Spark Driver开始分配和调度任务,并监控任务运行过程(失败会重新调度),直到所有任务运行完毕,应用程序退出。
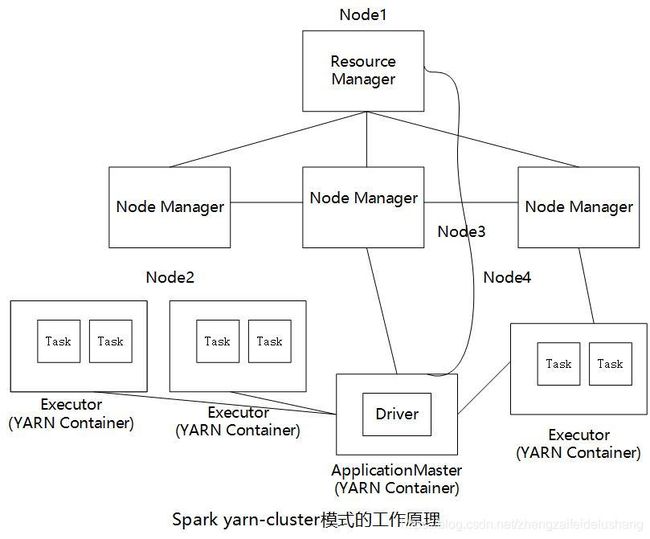
2.yarn-cluster
在yarn-cluster模式种,Spark Driver和Executor均运行在YARN Container中,且Spark Driver由ApplicationMaster启动,该模式下,Driver和Executor均具备良好的容错性能;Driver因故障退出后,由YARN ResourceManager重新调度与启动,Executor因故障退出后,由ApplicationMaster向ResourceManager重新申请资源,并重新启动之。
六、Spark应用程序
对于一个Spark应用程序(Application),通常会由一个或多个作业(job)构成,其中每个作业被划分成若干个阶段(Stage),而每个阶段内部进一步包含多个可并行执行的任务(Task)。
- Application:一个独立可执行的Spark应用程序,内部只包含一个SparkContext对象。
- Job:每个Action算子会产生一个Job,因此一个Application内部产生多个Job,用户可通过特殊的设置让没有依赖关系的Job并行执行。
- Stage:每个Job内部会产生多个Stage。
- Task:每个Stage可包含多个Task,这些Task之间通常没有依赖关系,是相互独立的,可并行执行。
Spark应用程序从提交到运行,依次会经历以下几个阶段:
1)生成逻辑计划:通过应用程序内部RDD之间的依赖关系,构造DAG,其中DAG中每个点是一个RDD对象,边则是两个RDD之间的转换方式。该阶段主要作用是将用户程序直接翻译成DAG。
2)生成物理计划:根据前一阶段生成的DAG,按照一定的规则进一步将之划分成若干Stage,其中每个Stage由若干个可并行计算的任务构成。
3) 调度并执行任务:按照依赖关系,调度并计算每个Stage。对于给定的Stage,将其对应的任务调度给多个Executor同时计算。
Spark应用程序提交,语法如下:
./bin/spark-submit --class <main-class> --master <master-url>
--deploy-mode <deploy-mode> --conf <key>=<value>
<application-jar> [application-arguments]
各参数含义解释如下表所示:
| 参数 | 描述 |
|---|---|
| –class | 应用程序的入口类 |
| –master | master URL,指定了具体的Spark运行模式 |
| –deploy-mode | Spark Driver部署模式,包括cluster和client两种,分别表示Driver运行在集群中和客户端 |
| –conf | Spark应用程序配置参数,以key/value键值对方式指定(比如:–conf spark.default.parallelism=8) |
| applicatio-jar | 应用程序的bundled jar,包含用户程序及其依赖jar包,可以存放在本地文件系统种或者分布式文件系统HDFS上 |
| application-arguments | 用户应用程序的输入参数 |
示例:
1)Driver运行在集群中,需要1个CPU,3GB内存(由参数"–driver-memory"指定)。
2)启动3个Executor(由参数"–num-executors"指定),每个Executor需要4个core(即同时可运行4个任务,由参数"–executor-cores"指定),8GB内存(由参数"–executor-memory"指定)。
3)提交到YARN中的spark队列中(由参数"–queue"指定)。
./bin/spark-submit
--class com.hadoop123.example.SparkInvertedIndex
--master yarn-cluster
--deploy-mode cluster
--driver-memory 3g
--num-executors 3
--executor-memory 4g
--executor-cores 4
--queue spark
SparkInvertedIndex.jar
七、Spark配置
1.为Spark配置环境变量
#JAVA环境
export JAVA_HOME=/moudle/jdk
export PATH=$JAVA_HOME/bin:$PATH
#hadoop环境
export HADOOP_HOME=/moudle/hadoop3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
#Spark环境
export SPARK_HOME=/moudle/spark
export PATH=$PATH:$SPARK_HOME/sbin:$SPARK_HOME/bin:$PATH
export PYTHON_PATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip:$PYTHON_PATH
2.配置Spark环境变量
cp spark-env.sh.template spark-env.sh
vim /moudle/spark/conf/spark-env.sh
#文件末尾加入以下内容
export JAVA_HOME=/moudle/jdk
export HADOOP_HOME=
export HADOOP_CONF_DIR=/moudle/hadoop3/etc/hadoop
export SPARK_MASTER_HOST=kafka1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_DRIVER_MEMORY=16g
export SPARK_WORKER_MEMORY=1g
export SPARK_MASTER_WEBUI_PORT=8080
#日志聚合
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000
-Dspark.history.retainedApplications=3
-Dspark.history.fs.logDirectory=hdfs://kafka1:8020/sparklog"
- 从节点配置
cp slaves.template slaves
vim /moudle/spark/conf/slaves
# A Spark Worker will be started on each of the machines listed below.
kafka1
kafka2
kafka3
4.基本配置文件
vim /moudle/spark/conf/spark-defaults.conf
#node2上启动spark的history server,配置node1则在node1上启动spark的history server
#18080是spark的history server
spark.yarn.historyServer.address=node2:18080
spark.history.ui.port=18080
spark.eventLog.enabled true
#日志目录
spark.eventLog.dir hdfs://kafka1:8020/sparklog
spark.history.fs.logDirectory=hdfs://kafka1:8020/sparklog