Kafka知识点总结
好记性不如赖笔头,通过写博客可以梳理自己的知识,也能够加深记忆,这个只是做了简单的总结,推荐一个更加详细的文章:
http://www.importnew.com/25247.html
1.topic&partition
Topic是用于存储消息的逻辑概念,可以看作一个消息集合。
每个topic可以划分多个分区(每个Topic至少有一个分区),同一topic下的不同分区包含的消息是不同的。每个消息在被添加到分区时,都会被分配一个offset(称之为偏移量),它是消息在此分区中的唯一编号,kafka通过offset保证消息在分区内的顺序,offset的顺序不跨分区,即kafka只保证在同一个分区内的消息是有序的;
Partition是以文件的形式存储在文件系统中,存储在kafka-log目录下,命名规则是:-
2.kafka的高性能
顺序写入写出,提升了吞吐量。
允许批量的消息发送,先将消息缓存到内存中打包一次性的发送,减少了磁盘IO和网络IO
zeroCopy,减少copy过程的无用功

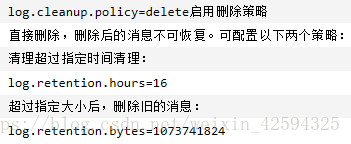
3.日志保留策略
日志是kafka中数据保留的主体,提供了两种数据保留的策略:
按照指定的保留时间进行删除;
按照设置的日志文件阈值删除Old的数据。
4.日志压缩策略
日志中只保留最新的key值对应的value值,类似于redis的AOF重写的机制

5.kafka中的消息副本leader
https://blog.csdn.net/liuao107329/article/details/70213599 点击打开链接
6.kafka消息可靠性机制
1)消息发送的可靠性
当producer向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别:
- 1(默认):这意味着producer在ISR中的leader已成功收到的数据并得到确认后发送下一条message。如果leader宕机了,则会丢失数据。
- 0:这意味着producer无需等待来自broker的确认而继续发送下一批消息。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
- -1:producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。但是这样也不能保证数据不丢失,比如当ISR中只有leader时(前面ISR那一节讲到,ISR中的成员由于某些情况会增加也会减少,最少就只剩一个leader),这样就变成了acks=1的情况。可以通过设置min.insync.replicas这个参数设定ISR中的最小副本数是多少,默认值为1,当且仅当为-1时min.insync.replicas才会生效。
2)消息存储的可靠性
kafka为每个topic设置了分区partition,又为每个分区设置了副本,来保障了数据的可靠性和高可用性