Pandas中apply,applymap以及python自带map的用法与区别
1.apply()
Pandas中apply函数的格式为:
apply(func, axis=0,raw=False, result_type=None, args=(), **kwds)其中,func可以是匿名函数,应用在DataFrame的行或列上。
axis:0或'index':函数应用在DataFrame每列上;
1或'columns':函数应用在DataFrame每行上。
raw:布尔值,默认False。
False or None:将每一行或一列作为系列传入函数;
True:传入的函数将接收nparray对象。
result_type:{‘expand’, ‘reduce’, ‘broadcast’, None},默认为 None
仅作用在axis=1上(列)
'expand':列表结果将变为列,返回的为Dataframe;
'reduce':返回一个系列,Series;
'broadcast':返回DataFrame数据,将保留原来的索引和列。
args:除了数组、系列之外,参数将传递给func。
import pandas as pd
import numpy as np
np.random.seed(123)
df = pd.DataFrame(np.random.randint(1,20,size=(5,4)),
index=['A','B','C','D','E'],
columns=['a','b','c','d'])
首先,用numpy生成一个(5,4)的随机整数DataFrame,范围是在(1,20)。其中设置了随机数种子,这样所产生的的随机数是一样的。
df.apply(np.sqrt)将会作用于DataFrame数据框的每一个数,其结果如下:

df.apply(np.sum,axis=0)
df.apply(np.sum,axis=1)

其中,axis=0按列进行求和;axis=2按行进行求和。
df.apply(lambda x:[1,2,3,4],axis=1,result_type='reduce')
df.apply(lambda x:[1,2,3,4],axis=1,result_type='expand')
df.apply(lambda x:[1,2,3,4],axis=1,result_type='broadcast')其结果依次为:



图1的结果就是Series,图2,3的结果都是Dataframe,唯一不同的就是图3保留的原来的索引和列。
2.map()
map() 会根据提供的函数对指定序列做映射。第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
iterable可以是一个或多个序列。其返回值为一个map对象。
map(function, iterable, ...)def f(x):
return x**2
list(map(f,[1,3,5,7,8]))map()函数在python3中的返回值是iterators,可用list()函数转换;在python2中为返回值为list。

3.applymap()
函数语法格式为:
applymap(func)该函数的返回值为一个DataFrame。
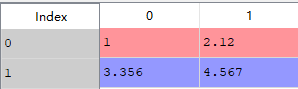
df1 = pd.DataFrame([[1, 2.12], [3.356, 4.567]])
a = df1.applymap(lambda x:len(str(x)))